 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYanming Lai
Convergence Analysis of Flow Matching in Latent Space with Transformers
Apr 03, 2024
We present theoretical convergence guarantees for ODE-based generative models, specifically flow matching. We use a pre-trained autoencoder network to map high-dimensional original inputs to a low-dimensional latent space, where a transformer network is trained to predict the velocity field of the transformation from a standard normal distribution to the target latent distribution. Our error analysis demonstrates the effectiveness of this approach, showing that the distribution of samples generated via estimated ODE flow converges to the target distribution in the Wasserstein-2 distance under mild and practical assumptions. Furthermore, we show that arbitrary smooth functions can be effectively approximated by transformer networks with Lipschitz continuity, which may be of independent interest.
Convergence Analysis of the Deep Galerkin Method for Weak Solutions
Feb 05, 2023This paper analyzes the convergence rate of a deep Galerkin method for the weak solution (DGMW) of second-order elliptic partial differential equations on $\mathbb{R}^d$ with Dirichlet, Neumann, and Robin boundary conditions, respectively. In DGMW, a deep neural network is applied to parametrize the PDE solution, and a second neural network is adopted to parametrize the test function in the traditional Galerkin formulation. By properly choosing the depth and width of these two networks in terms of the number of training samples $n$, it is shown that the convergence rate of DGMW is $\mathcal{O}(n^{-1/d})$, which is the first convergence result for weak solutions. The main idea of the proof is to divide the error of the DGMW into an approximation error and a statistical error. We derive an upper bound on the approximation error in the $H^{1}$ norm and bound the statistical error via Rademacher complexity.
Deep Neural Networks with ReLU-Sine-Exponential Activations Break Curse of Dimensionality on Hölder Class
Mar 07, 2021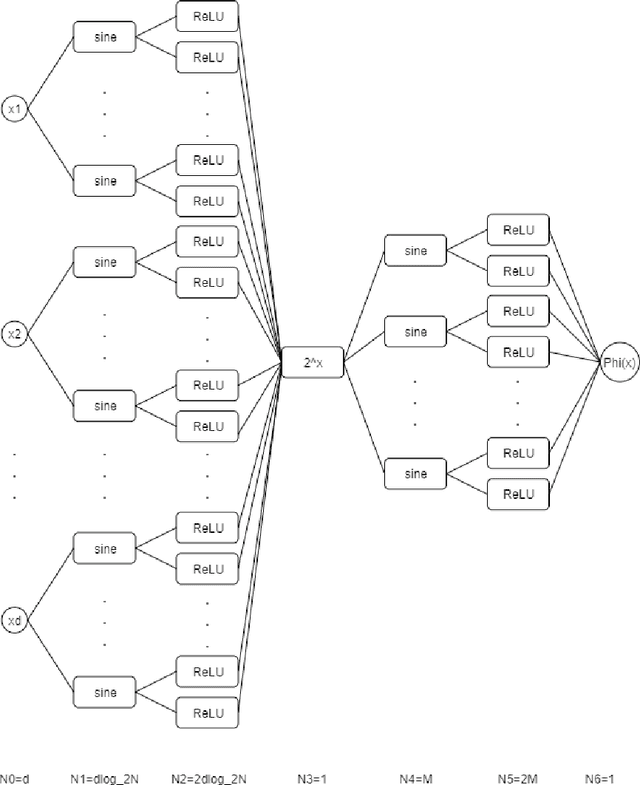

In this paper, we construct neural networks with ReLU, sine and $2^x$ as activation functions. For general continuous $f$ defined on $[0,1]^d$ with continuity modulus $\omega_f(\cdot)$, we construct ReLU-sine-$2^x$ networks that enjoy an approximation rate $\mathcal{O}(\omega_f(\sqrt{d})\cdot2^{-M}+\omega_{f}\left(\frac{\sqrt{d}}{N}\right))$, where $M,N\in \mathbb{N}^{+}$ denote the hyperparameters related to widths of the networks. As a consequence, we can construct ReLU-sine-$2^x$ network with the depth $5$ and width $\max\left\{\left\lceil2d^{3/2}\left(\frac{3\mu}{\epsilon}\right)^{1/{\alpha}}\right\rceil,2\left\lceil\log_2\frac{3\mu d^{\alpha/2}}{2\epsilon}\right\rceil+2\right\}$ that approximates $f\in \mathcal{H}_{\mu}^{\alpha}([0,1]^d)$ within a given tolerance $\epsilon >0$ measured in $L^p$ norm $p\in[1,\infty)$, where $\mathcal{H}_{\mu}^{\alpha}([0,1]^d)$ denotes the H\"older continuous function class defined on $[0,1]^d$ with order $\alpha \in (0,1]$ and constant $\mu > 0$. Therefore, the ReLU-sine-$2^x$ networks overcome the curse of dimensionality on $\mathcal{H}_{\mu}^{\alpha}([0,1]^d)$. In addition to its supper expressive power, functions implemented by ReLU-sine-$2^x$ networks are (generalized) differentiable, enabling us to apply SGD to train.