 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYannan Xing
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024
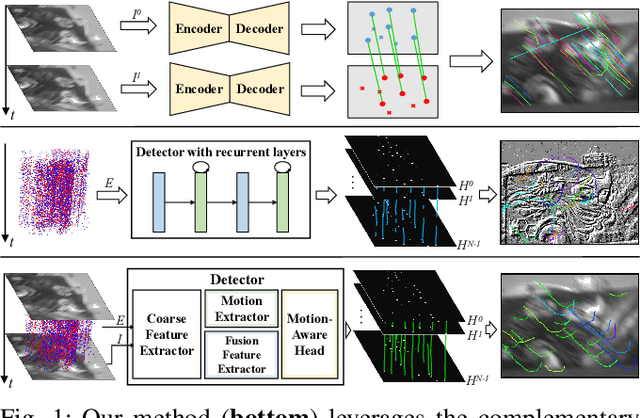
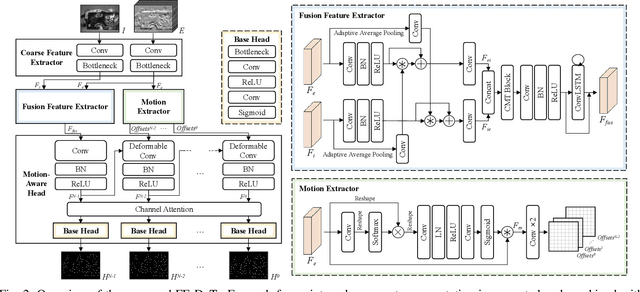

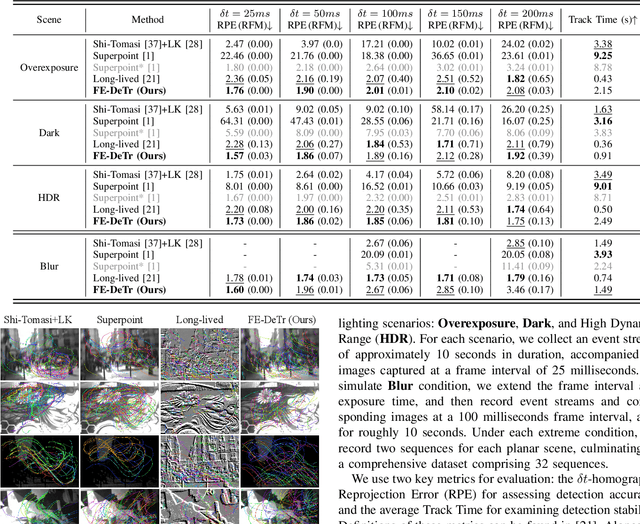
Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.
Speck: A Smart event-based Vision Sensor with a low latency 327K Neuron Convolutional Neuronal Network Processing Pipeline
Apr 13, 2023



Edge computing solutions that enable the extraction of high level information from a variety of sensors is in increasingly high demand. This is due to the increasing number of smart devices that require sensory processing for their application on the edge. To tackle this problem, we present a smart vision sensor System on Chip (Soc), featuring an event-based camera and a low power asynchronous spiking Convolutional Neuronal Network (sCNN) computing architecture embedded on a single chip. By combining both sensor and processing on a single die, we can lower unit production costs significantly. Moreover, the simple end-to-end nature of the SoC facilitates small stand-alone applications as well as functioning as an edge node in a larger systems. The event-driven nature of the vision sensor delivers high-speed signals in a sparse data stream. This is reflected in the processing pipeline, focuses on optimising highly sparse computation and minimising latency for 9 sCNN layers to $3.36\mu s$. Overall, this results in an extremely low-latency visual processing pipeline deployed on a small form factor with a low energy budget and sensor cost. We present the asynchronous architecture, the individual blocks, the sCNN processing principle and benchmark against other sCNN capable processors.