 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaojie Shen
Accurate and Fast Compressed Video Captioning
Sep 22, 2023
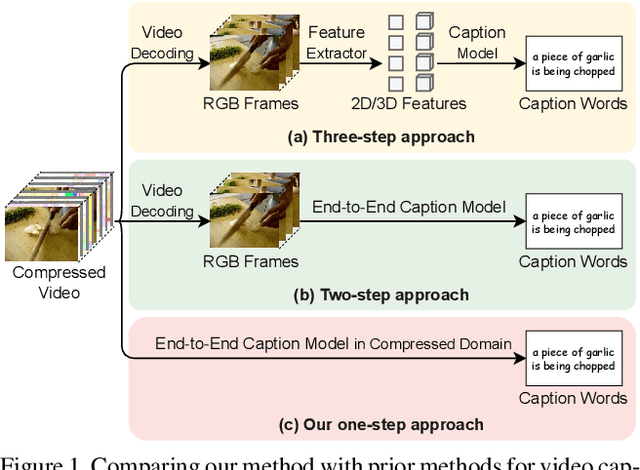
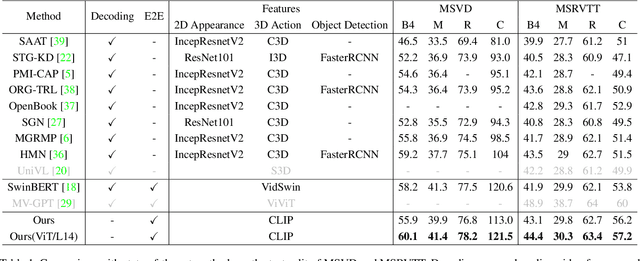
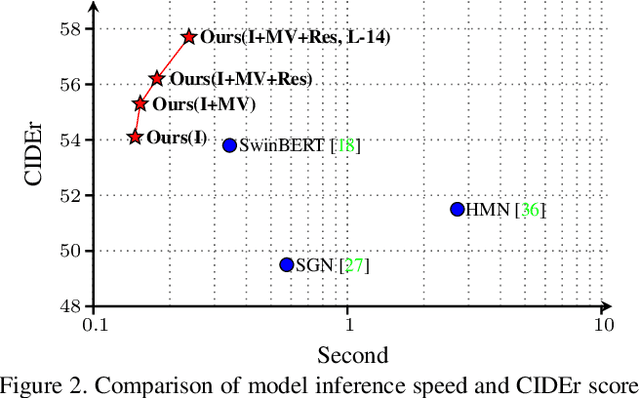
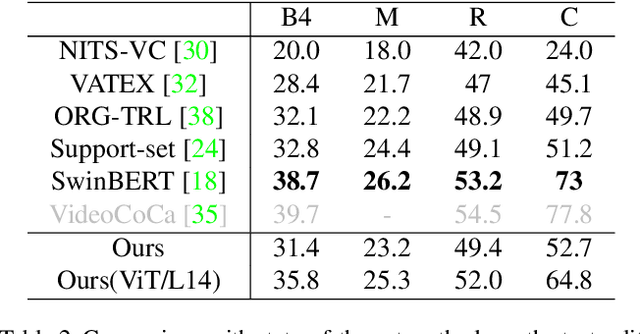
Existing video captioning approaches typically require to first sample video frames from a decoded video and then conduct a subsequent process (e.g., feature extraction and/or captioning model learning). In this pipeline, manual frame sampling may ignore key information in videos and thus degrade performance. Additionally, redundant information in the sampled frames may result in low efficiency in the inference of video captioning. Addressing this, we study video captioning from a different perspective in compressed domain, which brings multi-fold advantages over the existing pipeline: 1) Compared to raw images from the decoded video, the compressed video, consisting of I-frames, motion vectors and residuals, is highly distinguishable, which allows us to leverage the entire video for learning without manual sampling through a specialized model design; 2) The captioning model is more efficient in inference as smaller and less redundant information is processed. We propose a simple yet effective end-to-end transformer in the compressed domain for video captioning that enables learning from the compressed video for captioning. We show that even with a simple design, our method can achieve state-of-the-art performance on different benchmarks while running almost 2x faster than existing approaches. Code is available at https://github.com/acherstyx/CoCap.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022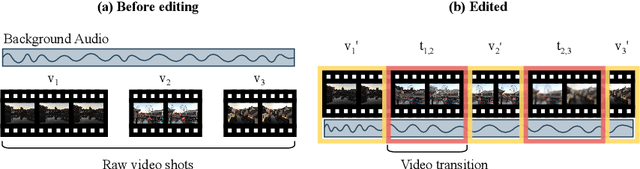
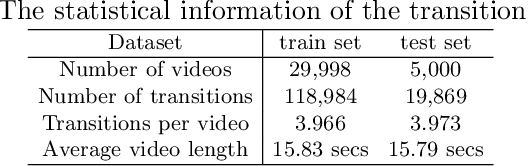
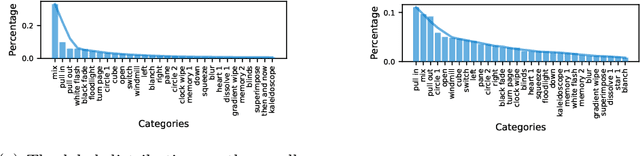
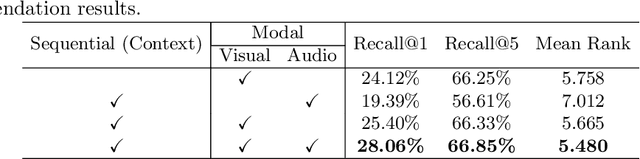
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.