 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaoting Wang
Prompting Segmentation with Sound is Generalizable Audio-Visual Source Localizer
Sep 18, 2023
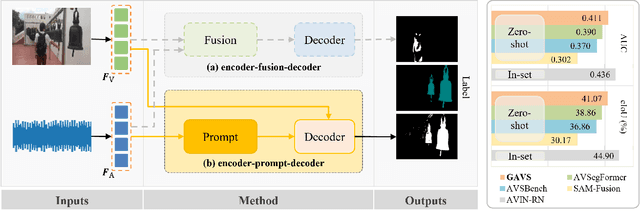
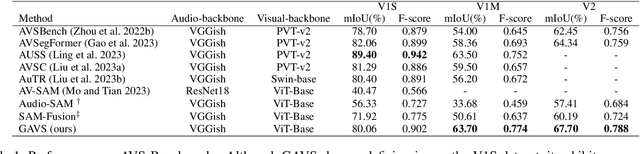
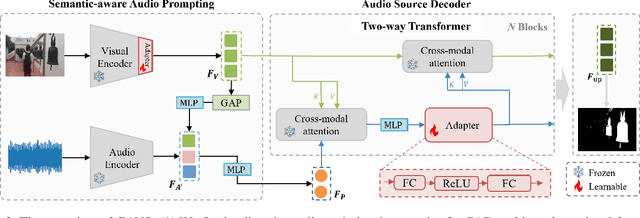

Never having seen an object and heard its sound simultaneously, can the model still accurately localize its visual position from the input audio? In this work, we concentrate on the Audio-Visual Localization and Segmentation tasks but under the demanding zero-shot and few-shot scenarios. To achieve this goal, different from existing approaches that mostly employ the encoder-fusion-decoder paradigm to decode localization information from the fused audio-visual feature, we introduce the encoder-prompt-decoder paradigm, aiming to better fit the data scarcity and varying data distribution dilemmas with the help of abundant knowledge from pre-trained models. Specifically, we first propose to construct Semantic-aware Audio Prompt (SAP) to help the visual foundation model focus on sounding objects, meanwhile, the semantic gap between the visual and audio modalities is also encouraged to shrink. Then, we develop a Correlation Adapter (ColA) to keep minimal training efforts as well as maintain adequate knowledge of the visual foundation model. By equipping with these means, extensive experiments demonstrate that this new paradigm outperforms other fusion-based methods in both the unseen class and cross-dataset settings. We hope that our work can further promote the generalization study of Audio-Visual Localization and Segmentation in practical application scenarios.
Cross-Attention is Not Enough: Incongruity-Aware Multimodal Sentiment Analysis and Emotion Recognition
May 23, 2023



Fusing multiple modalities for affective computing tasks has proven effective for performance improvement. However, how multimodal fusion works is not well understood, and its use in the real world usually results in large model sizes. In this work, on sentiment and emotion analysis, we first analyze how the salient affective information in one modality can be affected by the other in crossmodal attention. We find that inter-modal incongruity exists at the latent level due to crossmodal attention. Based on this finding, we propose a lightweight model via Hierarchical Crossmodal Transformer with Modality Gating (HCT-MG), which determines a primary modality according to its contribution to the target task and then hierarchically incorporates auxiliary modalities to alleviate inter-modal incongruity and reduce information redundancy. The experimental evaluation on three benchmark datasets: CMU-MOSI, CMU-MOSEI, and IEMOCAP verifies the efficacy of our approach, showing that it: 1) outperforms major prior work by achieving competitive results and can successfully recognize hard samples; 2) mitigates the inter-modal incongruity at the latent level when modalities have mismatched affective tendencies; 3) reduces model size to less than 1M parameters while outperforming existing models of similar sizes.
Aesthetic Quality Assessment for Group photograph
Feb 04, 2020



Image aesthetic quality assessment has got much attention in recent years, but not many works have been done on a specific genre of photos: Group photograph. In this work, we designed a set of high-level features based on the experience and principles of group photography: Opened-eye, Gaze, Smile, Occluded faces, Face Orientation, Facial blur, Character center. Then we combined them and 83 generic aesthetic features to build two aesthetic assessment models. We also constructed a large dataset of group photographs - GPD- annotated with the aesthetic score. The experimental result shows that our features perform well for categorizing professional photos and snapshots and predicting the distinction of multiple group photographs of diverse human states under the same scene.