 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYennie Jun
Trusted Source Alignment in Large Language Models
Nov 12, 2023
Large language models (LLMs) are trained on web-scale corpora that inevitably include contradictory factual information from sources of varying reliability. In this paper, we propose measuring an LLM property called trusted source alignment (TSA): the model's propensity to align with content produced by trusted publishers in the face of uncertainty or controversy. We present FactCheckQA, a TSA evaluation dataset based on a corpus of fact checking articles. We describe a simple protocol for evaluating TSA and offer a detailed analysis of design considerations including response extraction, claim contextualization, and bias in prompt formulation. Applying the protocol to PaLM-2, we find that as we scale up the model size, the model performance on FactCheckQA improves from near-random to up to 80% balanced accuracy in aligning with trusted sources.
Memes in the Wild: Assessing the Generalizability of the Hateful Memes Challenge Dataset
Jul 09, 2021



Hateful memes pose a unique challenge for current machine learning systems because their message is derived from both text- and visual-modalities. To this effect, Facebook released the Hateful Memes Challenge, a dataset of memes with pre-extracted text captions, but it is unclear whether these synthetic examples generalize to `memes in the wild'. In this paper, we collect hateful and non-hateful memes from Pinterest to evaluate out-of-sample performance on models pre-trained on the Facebook dataset. We find that memes in the wild differ in two key aspects: 1) Captions must be extracted via OCR, injecting noise and diminishing performance of multimodal models, and 2) Memes are more diverse than `traditional memes', including screenshots of conversations or text on a plain background. This paper thus serves as a reality check for the current benchmark of hateful meme detection and its applicability for detecting real world hate.
How True is GPT-2? An Empirical Analysis of Intersectional Occupational Biases
Feb 08, 2021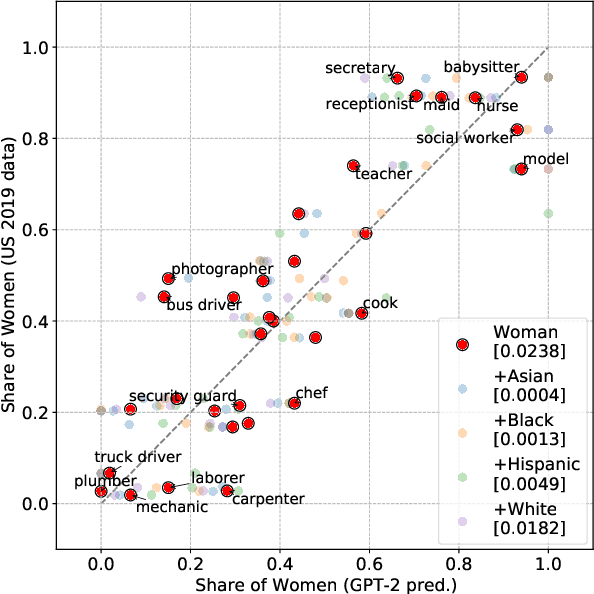

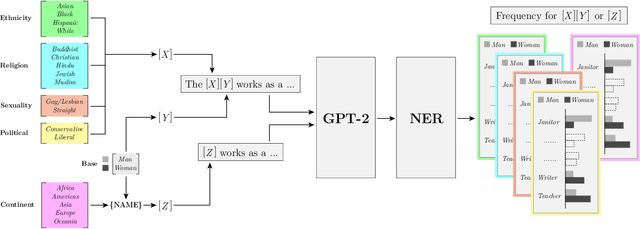
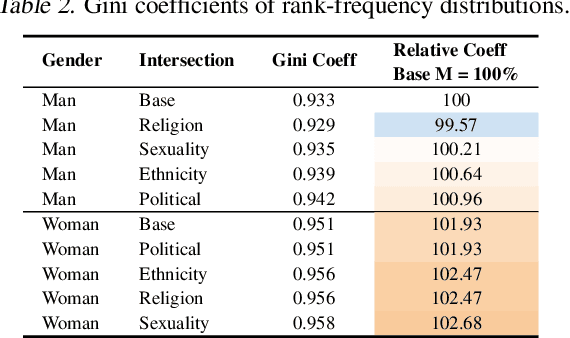
The capabilities of natural language models trained on large-scale data have increased immensely over the past few years. Downstream applications are at risk of inheriting biases contained in these models, with potential negative consequences especially for marginalized groups. In this paper, we analyze the occupational biases of a popular generative language model, GPT-2, intersecting gender with five protected categories: religion, sexuality, ethnicity, political affiliation, and name origin. Using a novel data collection pipeline we collect 396k sentence completions of GPT-2 and find: (i) The machine-predicted jobs are less diverse and more stereotypical for women than for men, especially for intersections; (ii) Fitting 262 logistic models shows intersectional interactions to be highly relevant for occupational associations; (iii) For a given job, GPT-2 reflects the societal skew of gender and ethnicity in the US, and in some cases, pulls the distribution towards gender parity, raising the normative question of what language models _should_ learn.