 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi-Cheng Zhang
A Fast Maximum Clique Algorithm Based on Network Decomposition for Large Sparse Networks
Apr 19, 2024
Finding maximum cliques in large networks is a challenging combinatorial problem with many real-world applications. We present a fast algorithm to achieve the exact solution for the maximum clique problem in large sparse networks based on efficient graph decomposition. A bunch of effective techniques is being used to greatly prune the graph and a novel concept called Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the structures with the potential to form the maximum clique are retained in the process of graph decomposition. Our algorithm first pre-prunes peripheral nodes, subsequently, one or two small-scale CUBISs are constructed guided by the core number and current maximum clique size. Bron-Kerbosch search is performed on each CUBIS to find the maximum clique. Experiments on 50 empirical networks with a scale of up to 20 million show the CUBIS scales are largely independent of the original network scale. This enables an approximately linear runtime, making our algorithm amenable for large networks. Our work provides a new framework for effectively solving maximum clique problems on massive sparse graphs, which not only makes the graph scale no longer the bottleneck but also shows some light on solving other clique-related problems.
Predicting missing links via correlation between nodes
Sep 30, 2014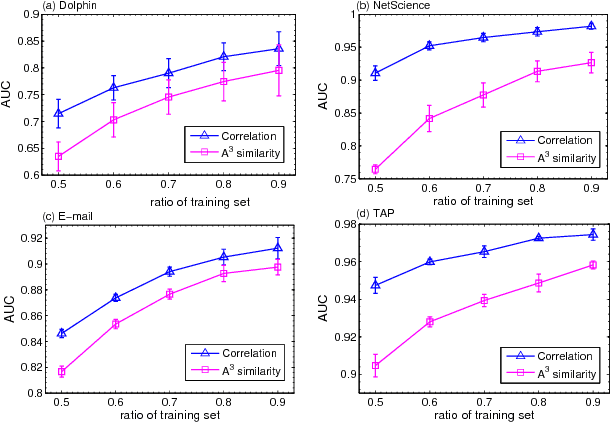
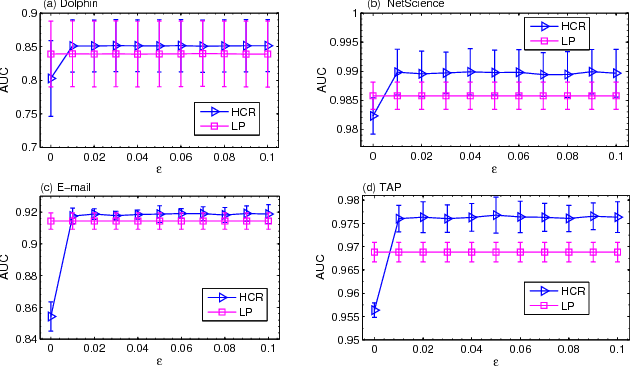
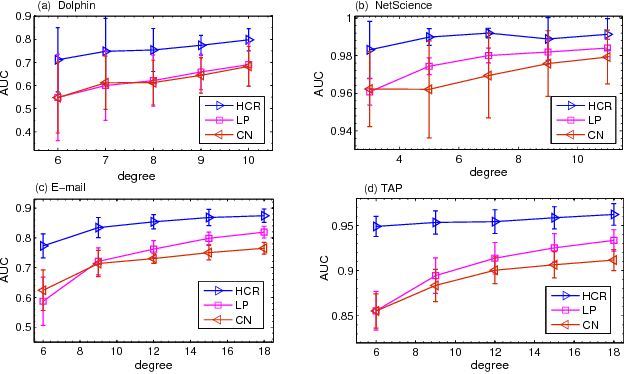
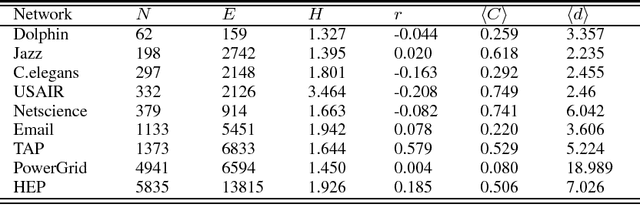
As a fundamental problem in many different fields, link prediction aims to estimate the likelihood of an existing link between two nodes based on the observed information. Since this problem is related to many applications ranging from uncovering missing data to predicting the evolution of networks, link prediction has been intensively investigated recently and many methods have been proposed so far. The essential challenge of link prediction is to estimate the similarity between nodes. Most of the existing methods are based on the common neighbor index and its variants. In this paper, we propose to calculate the similarity between nodes by the correlation coefficient. This method is found to be very effective when applied to calculate similarity based on high order paths. We finally fuse the correlation-based method with the resource allocation method, and find that the combined method can substantially outperform the existing methods, especially in sparse networks.