 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYichen Zhang
APACE: Agile and Perception-Aware Trajectory Generation for Quadrotor Flights
Mar 13, 2024

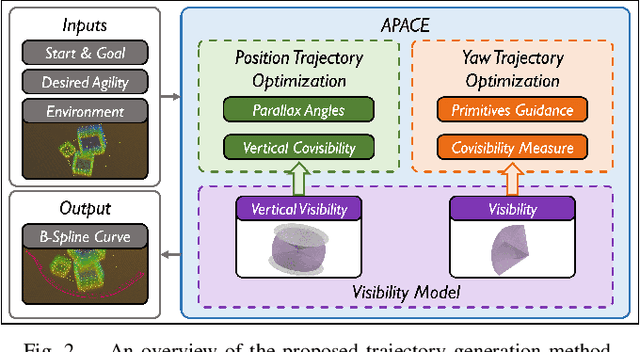
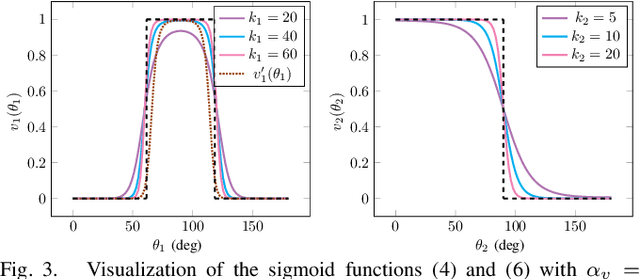
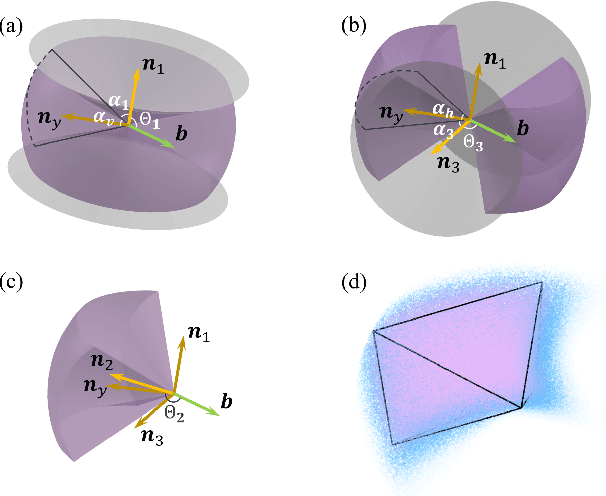
Various perception-aware planning approaches have attempted to enhance the state estimation accuracy during maneuvers, while the feature matchability among frames, a crucial factor influencing estimation accuracy, has often been overlooked. In this paper, we present APACE, an Agile and Perception-Aware trajeCtory gEneration framework for quadrotors aggressive flight, that takes into account feature matchability during trajectory planning. We seek to generate a perception-aware trajectory that reduces the error of visual-based estimator while satisfying the constraints on smoothness, safety, agility and the quadrotor dynamics. The perception objective is achieved by maximizing the number of covisible features while ensuring small enough parallax angles. Additionally, we propose a differentiable and accurate visibility model that allows decomposition of the trajectory planning problem for efficient optimization resolution. Through validations conducted in both a photorealistic simulator and real-world experiments, we demonstrate that the trajectories generated by our method significantly improve state estimation accuracy, with root mean square error (RMSE) reduced by up to an order of magnitude. The source code will be released to benefit the community.
Online Tensor Inference
Dec 28, 2023Recent technological advances have led to contemporary applications that demand real-time processing and analysis of sequentially arriving tensor data. Traditional offline learning, involving the storage and utilization of all data in each computational iteration, becomes impractical for high-dimensional tensor data due to its voluminous size. Furthermore, existing low-rank tensor methods lack the capability for statistical inference in an online fashion, which is essential for real-time predictions and informed decision-making. This paper addresses these challenges by introducing a novel online inference framework for low-rank tensor learning. Our approach employs Stochastic Gradient Descent (SGD) to enable efficient real-time data processing without extensive memory requirements, thereby significantly reducing computational demands. We establish a non-asymptotic convergence result for the online low-rank SGD estimator, nearly matches the minimax optimal rate of estimation error in offline models that store all historical data. Building upon this foundation, we propose a simple yet powerful online debiasing approach for sequential statistical inference in low-rank tensor learning. The entire online procedure, covering both estimation and inference, eliminates the need for data splitting or storing historical data, making it suitable for on-the-fly hypothesis testing. Given the sequential nature of our data collection, traditional analyses relying on offline methods and sample splitting are inadequate. In our analysis, we control the sum of constructed super-martingales to ensure estimates along the entire solution path remain within the benign region. Additionally, a novel spectral representation tool is employed to address statistical dependencies among iterative estimates, establishing the desired asymptotic normality.
Online Estimation and Inference for Robust Policy Evaluation in Reinforcement Learning
Oct 04, 2023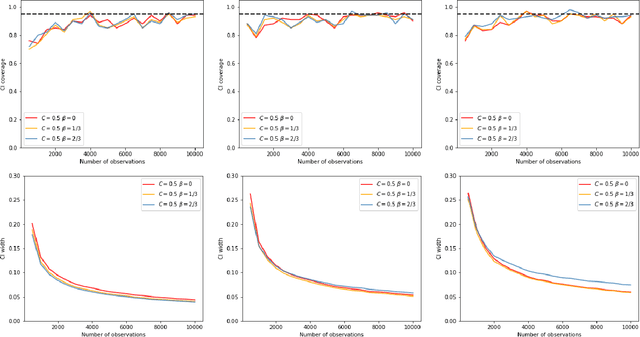
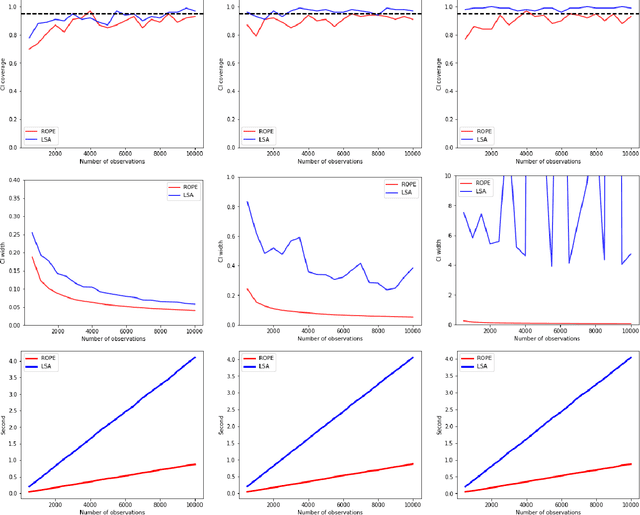
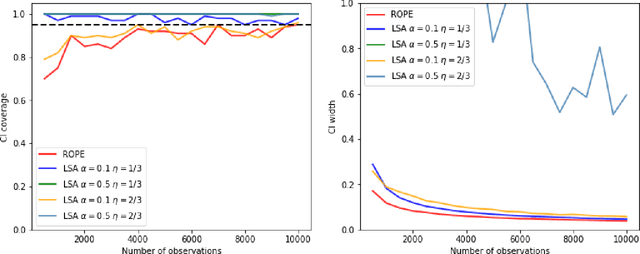
Recently, reinforcement learning has gained prominence in modern statistics, with policy evaluation being a key component. Unlike traditional machine learning literature on this topic, our work places emphasis on statistical inference for the parameter estimates computed using reinforcement learning algorithms. While most existing analyses assume random rewards to follow standard distributions, limiting their applicability, we embrace the concept of robust statistics in reinforcement learning by simultaneously addressing issues of outlier contamination and heavy-tailed rewards within a unified framework. In this paper, we develop an online robust policy evaluation procedure, and establish the limiting distribution of our estimator, based on its Bahadur representation. Furthermore, we develop a fully-online procedure to efficiently conduct statistical inference based on the asymptotic distribution. This paper bridges the gap between robust statistics and statistical inference in reinforcement learning, offering a more versatile and reliable approach to policy evaluation. Finally, we validate the efficacy of our algorithm through numerical experiments conducted in real-world reinforcement learning experiments.
Prototypical Cross-domain Knowledge Transfer for Cervical Dysplasia Visual Inspection
Aug 19, 2023
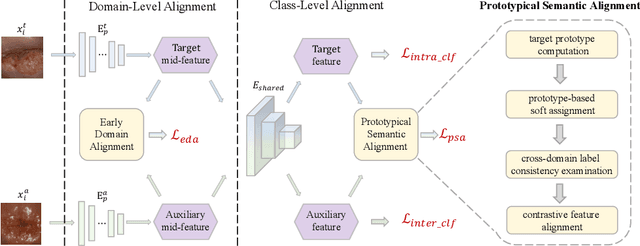
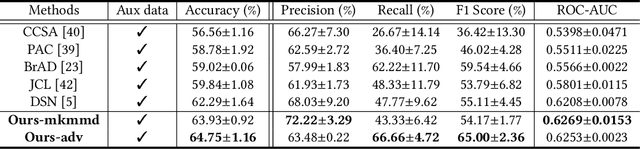

Early detection of dysplasia of the cervix is critical for cervical cancer treatment. However, automatic cervical dysplasia diagnosis via visual inspection, which is more appropriate in low-resource settings, remains a challenging problem. Though promising results have been obtained by recent deep learning models, their performance is significantly hindered by the limited scale of the available cervix datasets. Distinct from previous methods that learn from a single dataset, we propose to leverage cross-domain cervical images that were collected in different but related clinical studies to improve the model's performance on the targeted cervix dataset. To robustly learn the transferable information across datasets, we propose a novel prototype-based knowledge filtering method to estimate the transferability of cross-domain samples. We further optimize the shared feature space by aligning the cross-domain image representations simultaneously on domain level with early alignment and class level with supervised contrastive learning, which endows model training and knowledge transfer with stronger robustness. The empirical results on three real-world benchmark cervical image datasets show that our proposed method outperforms the state-of-the-art cervical dysplasia visual inspection by an absolute improvement of 4.7% in top-1 accuracy, 7.0% in precision, 1.4% in recall, 4.6% in F1 score, and 0.05 in ROC-AUC.
Beyond Geo-localization: Fine-grained Orientation of Street-view Images by Cross-view Matching with Satellite Imagery with Supplementary Materials
Jul 13, 2023
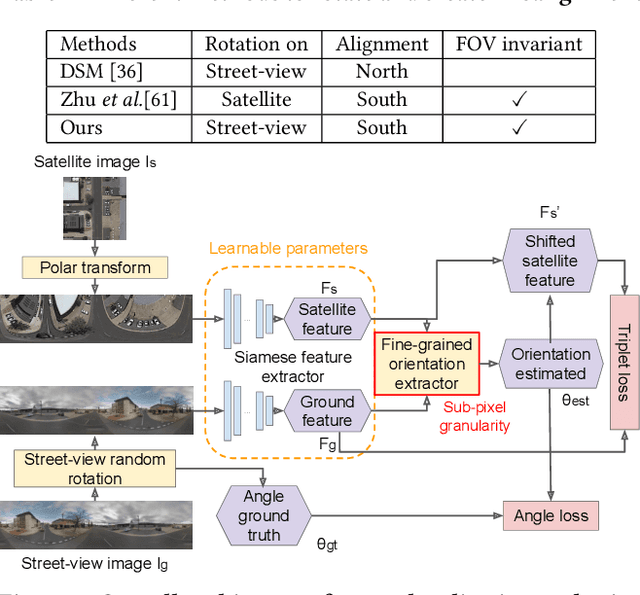

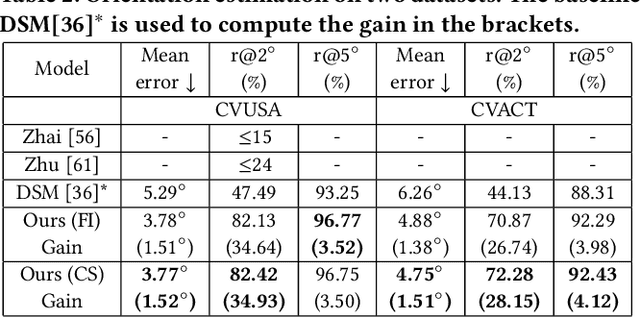
Street-view imagery provides us with novel experiences to explore different places remotely. Carefully calibrated street-view images (e.g. Google Street View) can be used for different downstream tasks, e.g. navigation, map features extraction. As personal high-quality cameras have become much more affordable and portable, an enormous amount of crowdsourced street-view images are uploaded to the internet, but commonly with missing or noisy sensor information. To prepare this hidden treasure for "ready-to-use" status, determining missing location information and camera orientation angles are two equally important tasks. Recent methods have achieved high performance on geo-localization of street-view images by cross-view matching with a pool of geo-referenced satellite imagery. However, most of the existing works focus more on geo-localization than estimating the image orientation. In this work, we re-state the importance of finding fine-grained orientation for street-view images, formally define the problem and provide a set of evaluation metrics to assess the quality of the orientation estimation. We propose two methods to improve the granularity of the orientation estimation, achieving 82.4% and 72.3% accuracy for images with estimated angle errors below 2 degrees for CVUSA and CVACT datasets, corresponding to 34.9% and 28.2% absolute improvement compared to previous works. Integrating fine-grained orientation estimation in training also improves the performance on geo-localization, giving top 1 recall 95.5%/85.5% and 86.8%/80.4% for orientation known/unknown tests on the two datasets.
* This paper has been accepted by ACM Multimedia 2022. This version contains additional supplementary materials
Acceleration of stochastic gradient descent with momentum by averaging: finite-sample rates and asymptotic normality
May 28, 2023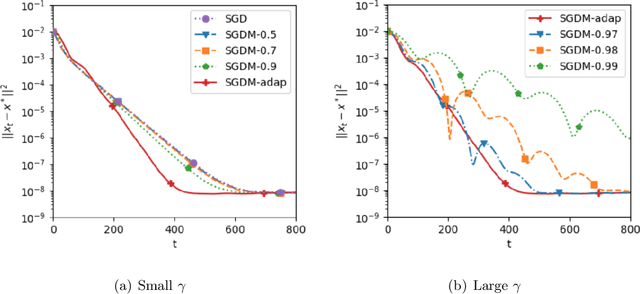
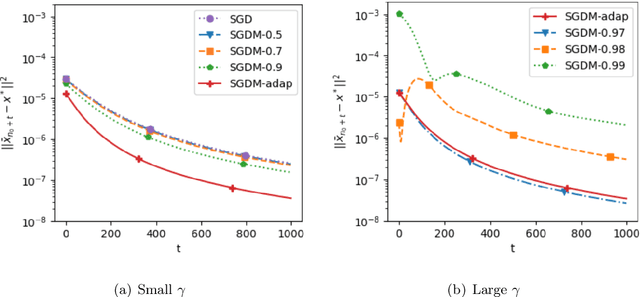
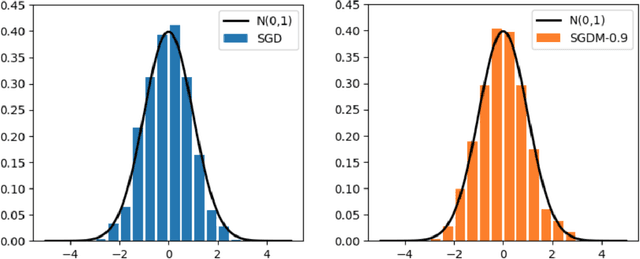
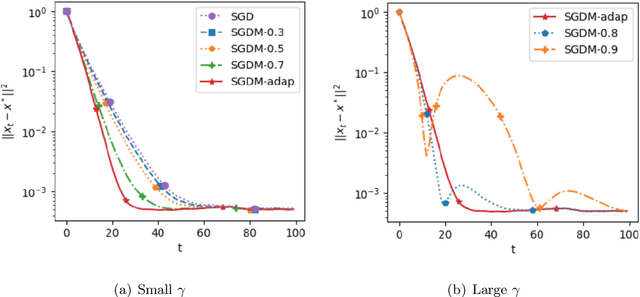
Stochastic gradient descent with momentum (SGDM) has been widely used in many machine learning and statistical applications. Despite the observed empirical benefits of SGDM over traditional SGD, the theoretical understanding of the role of momentum for different learning rates in the optimization process remains widely open. We analyze the finite-sample convergence rate of SGDM under the strongly convex settings and show that, with a large batch size, the mini-batch SGDM converges faster than mini-batch SGD to a neighborhood of the optimal value. Furthermore, we analyze the Polyak-averaging version of the SGDM estimator, establish its asymptotic normality, and justify its asymptotic equivalence to the averaged SGD.
Manifold-Aware Self-Training for Unsupervised Domain Adaptation on Regressing 6D Object Pose
May 18, 2023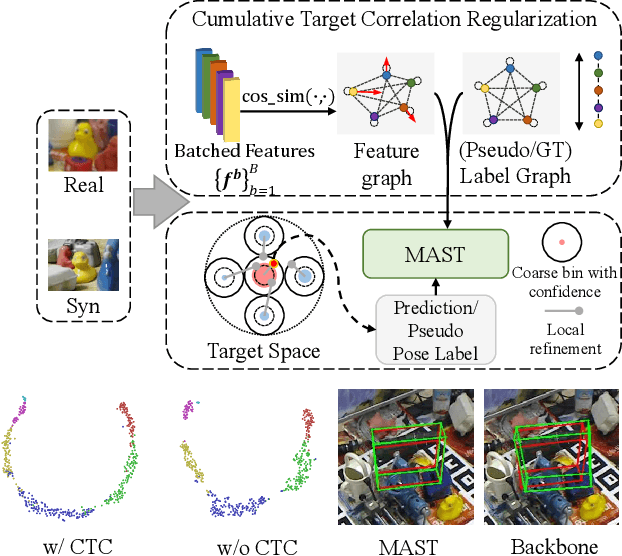
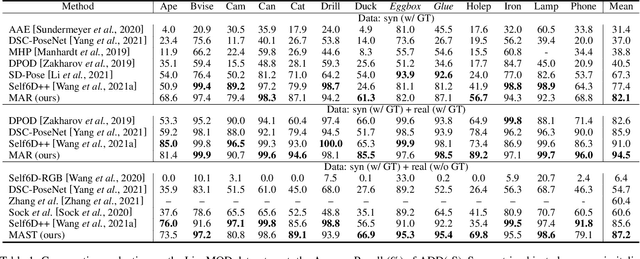
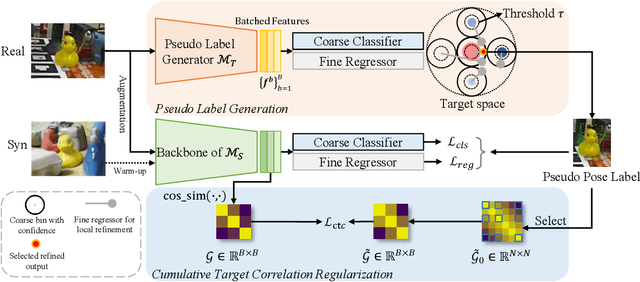
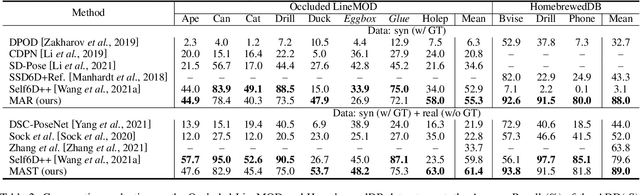
Domain gap between synthetic and real data in visual regression (\eg 6D pose estimation) is bridged in this paper via global feature alignment and local refinement on the coarse classification of discretized anchor classes in target space, which imposes a piece-wise target manifold regularization into domain-invariant representation learning. Specifically, our method incorporates an explicit self-supervised manifold regularization, revealing consistent cumulative target dependency across domains, to a self-training scheme (\eg the popular Self-Paced Self-Training) to encourage more discriminative transferable representations of regression tasks. Moreover, learning unified implicit neural functions to estimate relative direction and distance of targets to their nearest class bins aims to refine target classification predictions, which can gain robust performance against inconsistent feature scaling sensitive to UDA regressors. Experiment results on three public benchmarks of the challenging 6D pose estimation task can verify the effectiveness of our method, consistently achieving superior performance to the state-of-the-art for UDA on 6D pose estimation.
Online Statistical Inference for Contextual Bandits via Stochastic Gradient Descent
Dec 30, 2022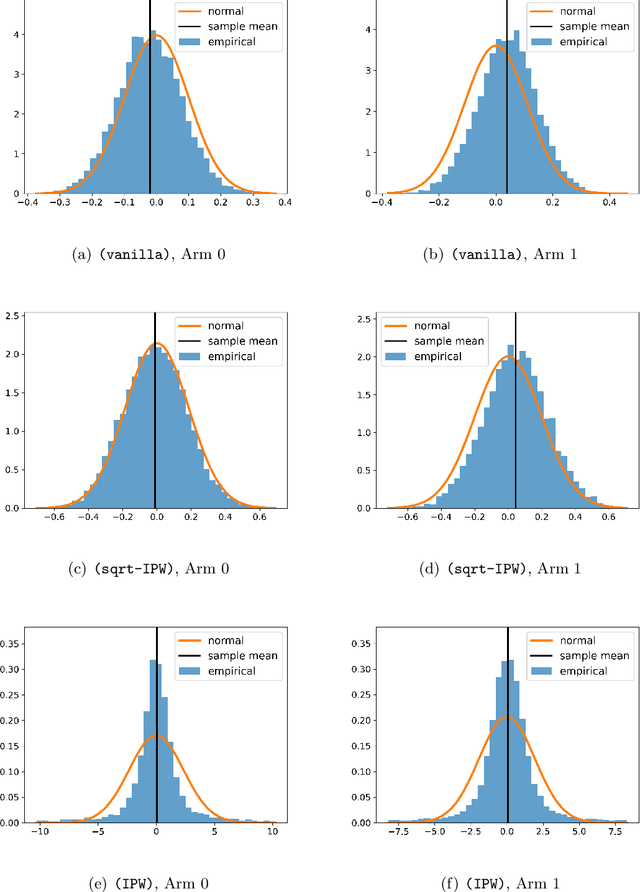
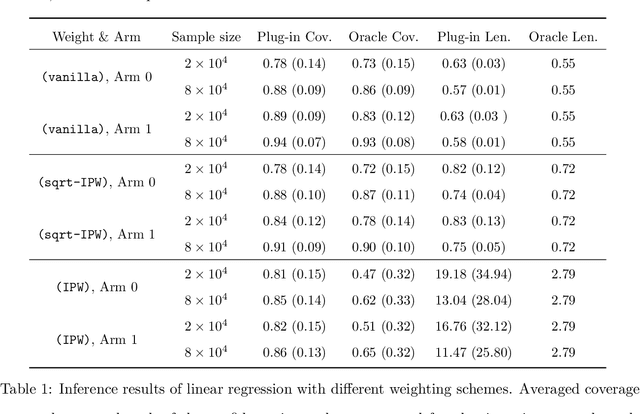
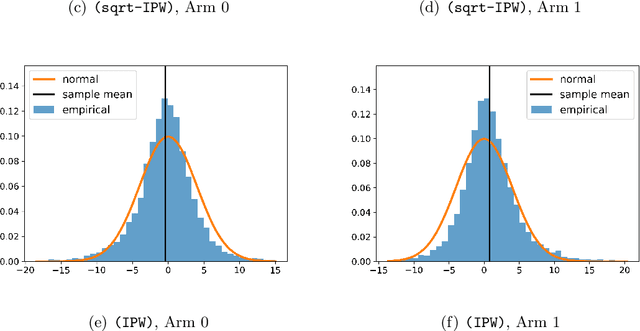
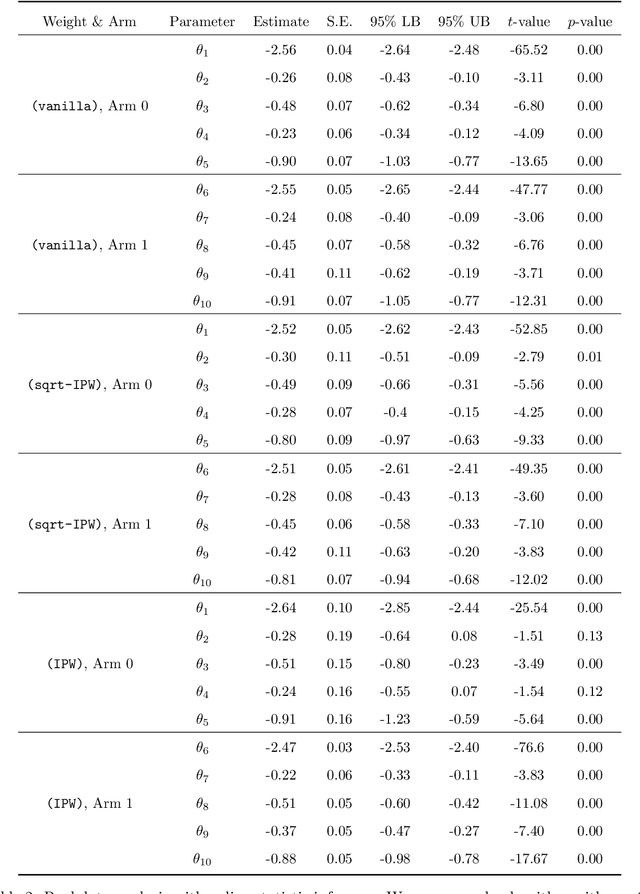
With the fast development of big data, it has been easier than before to learn the optimal decision rule by updating the decision rule recursively and making online decisions. We study the online statistical inference of model parameters in a contextual bandit framework of sequential decision-making. We propose a general framework for online and adaptive data collection environment that can update decision rules via weighted stochastic gradient descent. We allow different weighting schemes of the stochastic gradient and establish the asymptotic normality of the parameter estimator. Our proposed estimator significantly improves the asymptotic efficiency over the previous averaged SGD approach via inverse probability weights. We also conduct an optimality analysis on the weights in a linear regression setting. We provide a Bahadur representation of the proposed estimator and show that the remainder term in the Bahadur representation entails a slower convergence rate compared to classical SGD due to the adaptive data collection.
Online Statistical Inference for Matrix Contextual Bandit
Dec 21, 2022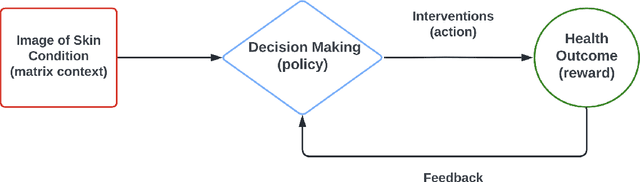

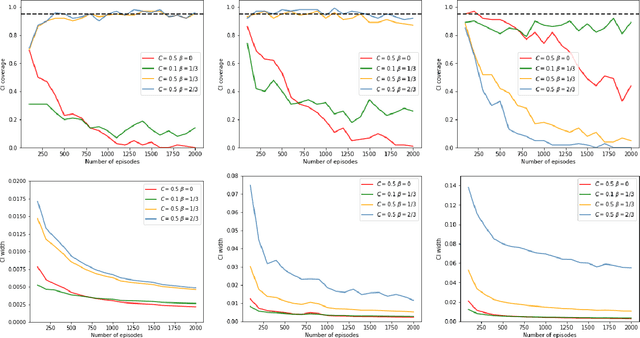
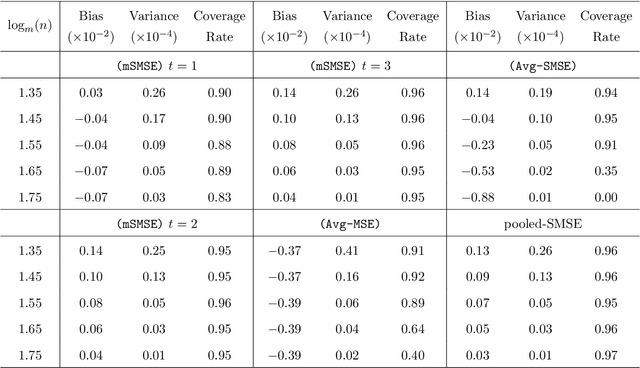
Contextual bandit has been widely used for sequential decision-making based on the current contextual information and historical feedback data. In modern applications, such context format can be rich and can often be formulated as a matrix. Moreover, while existing bandit algorithms mainly focused on reward-maximization, less attention has been paid to the statistical inference. To fill in these gaps, in this work we consider a matrix contextual bandit framework where the true model parameter is a low-rank matrix, and propose a fully online procedure to simultaneously make sequential decision-making and conduct statistical inference. The low-rank structure of the model parameter and the adaptivity nature of the data collection process makes this difficult: standard low-rank estimators are not fully online and are biased, while existing inference approaches in bandit algorithms fail to account for the low-rankness and are also biased. To address these, we introduce a new online doubly-debiasing inference procedure to simultaneously handle both sources of bias. In theory, we establish the asymptotic normality of the proposed online doubly-debiased estimator and prove the validity of the constructed confidence interval. Our inference results are built upon a newly developed low-rank stochastic gradient descent estimator and its non-asymptotic convergence result, which is also of independent interest.
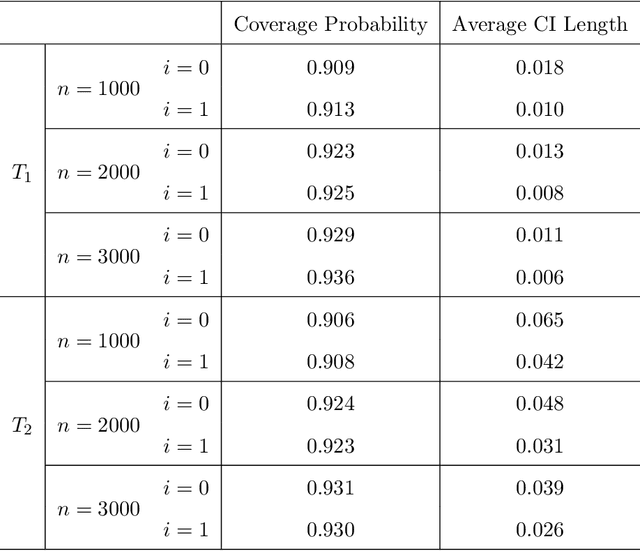
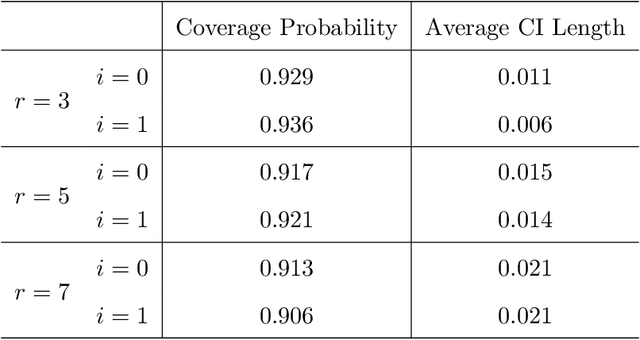
Distributed Estimation and Inference for Semi-parametric Binary Response Models
Oct 15, 2022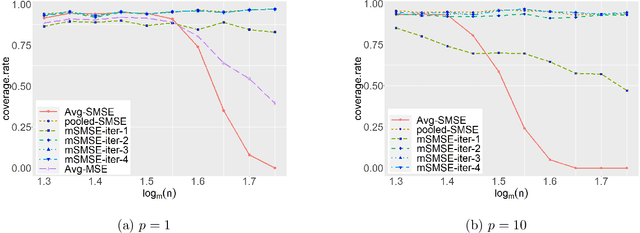
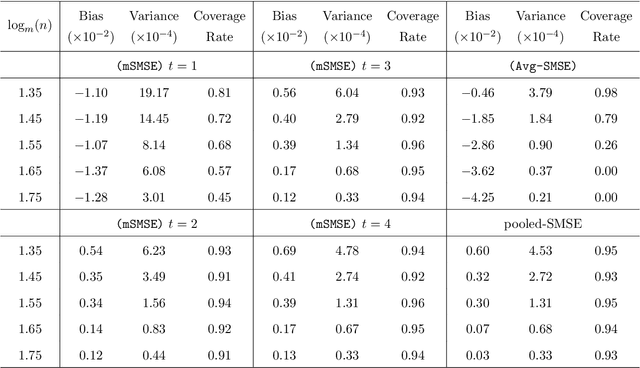
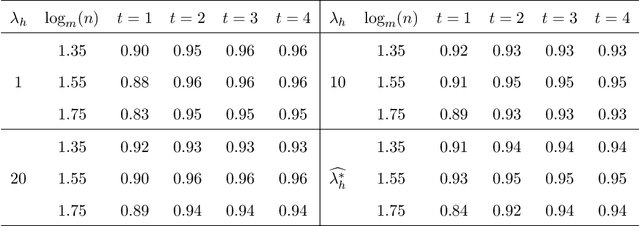
The development of modern technology has enabled data collection of unprecedented size, which poses new challenges to many statistical estimation and inference problems. This paper studies the maximum score estimator of a semi-parametric binary choice model under a distributed computing environment without pre-specifying the noise distribution. An intuitive divide-and-conquer estimator is computationally expensive and restricted by a non-regular constraint on the number of machines, due to the highly non-smooth nature of the objective function. We propose (1) a one-shot divide-and-conquer estimator after smoothing the objective to relax the constraint, and (2) a multi-round estimator to completely remove the constraint via iterative smoothing. We specify an adaptive choice of kernel smoother with a sequentially shrinking bandwidth to achieve the superlinear improvement of the optimization error over the multiple iterations. The improved statistical accuracy per iteration is derived, and a quadratic convergence up to the optimal statistical error rate is established. We further provide two generalizations to handle the heterogeneity of datasets with covariate shift and high-dimensional problems where the parameter of interest is sparse.