 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifu Gao
Don't Half-listen: Capturing Key-part Information in Continual Instruction Tuning
Mar 15, 2024
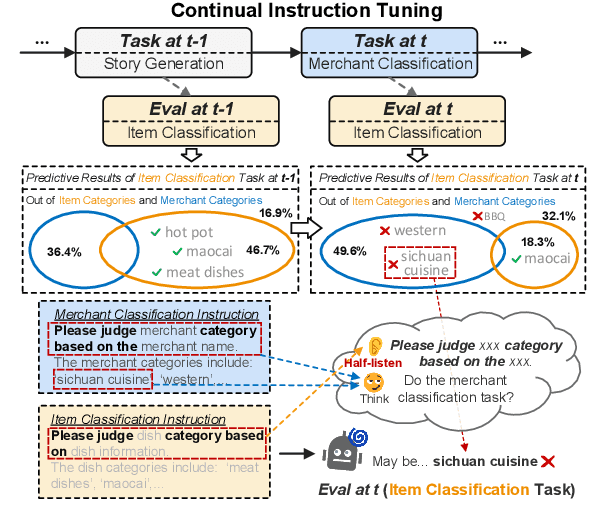
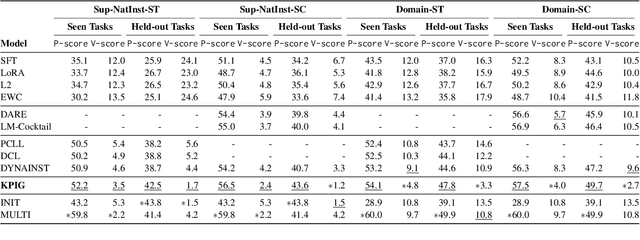
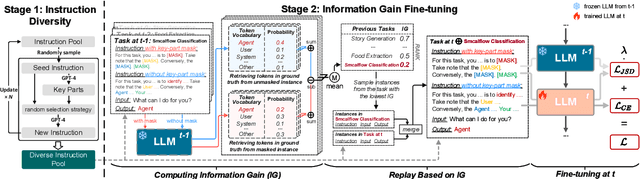
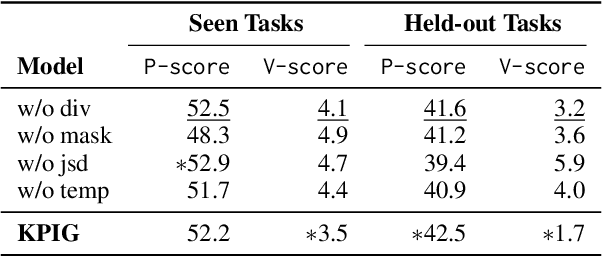
Instruction tuning for large language models (LLMs) can drive them to produce results consistent with human goals in specific downstream tasks. However, the process of continual instruction tuning (CIT) for LLMs may bring about the catastrophic forgetting (CF) problem, where previously learned abilities are degraded. Recent methods try to alleviate the CF problem by modifying models or replaying data, which may only remember the surface-level pattern of instructions and get confused on held-out tasks. In this paper, we propose a novel continual instruction tuning method based on Key-part Information Gain (KPIG). Our method computes the information gain on masked parts to dynamically replay data and refine the training objective, which enables LLMs to capture task-aware information relevant to the correct response and alleviate overfitting to general descriptions in instructions. In addition, we propose two metrics, P-score and V-score, to measure the generalization and instruction-following abilities of LLMs. Experiments demonstrate our method achieves superior performance on both seen and held-out tasks.
Two-stage Generative Question Answering on Temporal Knowledge Graph Using Large Language Models
Feb 26, 2024Temporal knowledge graph question answering (TKGQA) poses a significant challenge task, due to the temporal constraints hidden in questions and the answers sought from dynamic structured knowledge. Although large language models (LLMs) have made considerable progress in their reasoning ability over structured data, their application to the TKGQA task is a relatively unexplored area. This paper first proposes a novel generative temporal knowledge graph question answering framework, GenTKGQA, which guides LLMs to answer temporal questions through two phases: Subgraph Retrieval and Answer Generation. First, we exploit LLM's intrinsic knowledge to mine temporal constraints and structural links in the questions without extra training, thus narrowing down the subgraph search space in both temporal and structural dimensions. Next, we design virtual knowledge indicators to fuse the graph neural network signals of the subgraph and the text representations of the LLM in a non-shallow way, which helps the open-source LLM deeply understand the temporal order and structural dependencies among the retrieved facts through instruction tuning. Experimental results demonstrate that our model outperforms state-of-the-art baselines, even achieving 100\% on the metrics for the simple question type.