 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYihua Cheng
TextGaze: Gaze-Controllable Face Generation with Natural Language
Apr 26, 2024
Generating face image with specific gaze information has attracted considerable attention. Existing approaches typically input gaze values directly for face generation, which is unnatural and requires annotated gaze datasets for training, thereby limiting its application. In this paper, we present a novel gaze-controllable face generation task. Our approach inputs textual descriptions that describe human gaze and head behavior and generates corresponding face images. Our work first introduces a text-of-gaze dataset containing over 90k text descriptions spanning a dense distribution of gaze and head poses. We further propose a gaze-controllable text-to-face method. Our method contains a sketch-conditioned face diffusion module and a model-based sketch diffusion module. We define a face sketch based on facial landmarks and eye segmentation map. The face diffusion module generates face images from the face sketch, and the sketch diffusion module employs a 3D face model to generate face sketch from text description. Experiments on the FFHQ dataset show the effectiveness of our method. We will release our dataset and code for future research.
What Do You See in Vehicle? Comprehensive Vision Solution for In-Vehicle Gaze Estimation
Mar 23, 2024
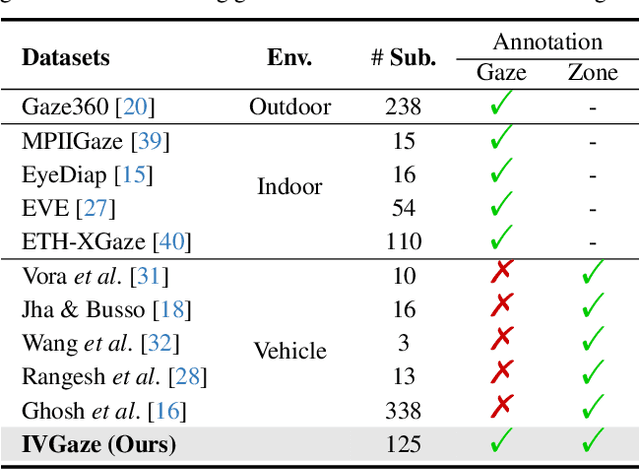

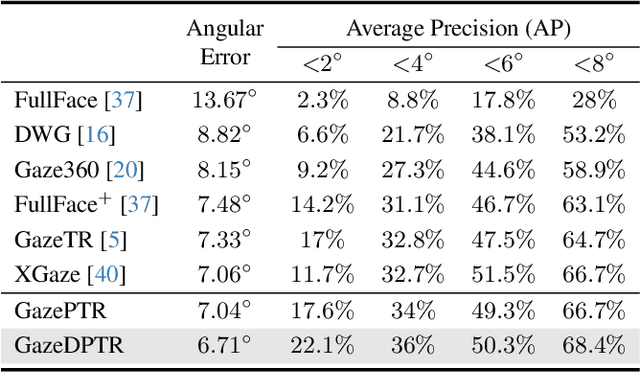
Driver's eye gaze holds a wealth of cognitive and intentional cues crucial for intelligent vehicles. Despite its significance, research on in-vehicle gaze estimation remains limited due to the scarcity of comprehensive and well-annotated datasets in real driving scenarios. In this paper, we present three novel elements to advance in-vehicle gaze research. Firstly, we introduce IVGaze, a pioneering dataset capturing in-vehicle gaze, collected from 125 subjects and covering a large range of gaze and head poses within vehicles. Conventional gaze collection systems are inadequate for in-vehicle use. In this dataset, we propose a new vision-based solution for in-vehicle gaze collection, introducing a refined gaze target calibration method to tackle annotation challenges. Second, our research focuses on in-vehicle gaze estimation leveraging the IVGaze. In-vehicle face images often suffer from low resolution, prompting our introduction of a gaze pyramid transformer that leverages transformer-based multilevel features integration. Expanding upon this, we introduce the dual-stream gaze pyramid transformer (GazeDPTR). Employing perspective transformation, we rotate virtual cameras to normalize images, utilizing camera pose to merge normalized and original images for accurate gaze estimation. GazeDPTR shows state-of-the-art performance on the IVGaze dataset. Thirdly, we explore a novel strategy for gaze zone classification by extending the GazeDPTR. A foundational tri-plane and project gaze onto these planes are newly defined. Leveraging both positional features from the projection points and visual attributes from images, we achieve superior performance compared to relying solely on visual features, substantiating the advantage of gaze estimation. Our project is available at https://yihua.zone/work/ivgaze.
Chatterbox: Robust Transport for LLM Token Streaming under Unstable Network
Jan 23, 2024To render each generated token in real time, the LLM server generates response tokens one by one and streams each generated token (or group of a few tokens) through the network to the user right after it is generated, which we refer to as LLM token streaming. However, under unstable network conditions, the LLM token streaming experience could suffer greatly from stalls since one packet loss could block the rendering of tokens contained in subsequent packets even if they arrive on time. With a real-world measurement study, we show that current applications including ChatGPT, Claude, and Bard all suffer from increased stall under unstable network. For this emerging token streaming problem in LLM Chatbots, we propose a novel transport layer scheme, called Chatterbox, which puts new generated tokens as well as currently unacknowledged tokens in the next outgoing packet. This ensures that each packet contains some new tokens and can be independently rendered when received, thus avoiding aforementioned stalls caused by missing packets. Through simulation under various network conditions, we show Chatterbox reduces stall ratio (proportion of token rendering wait time) by 71.0% compared to the token streaming method commonly used by real chatbot applications and by 31.6% compared to a custom packet duplication scheme. By tailoring Chatterbox to fit the token-by-token generation of LLM, we enable the Chatbots to respond like an eloquent speaker for users to better enjoy pervasive AI.
Multi-Modal Gaze Following in Conversational Scenarios
Nov 09, 2023Gaze following estimates gaze targets of in-scene person by understanding human behavior and scene information. Existing methods usually analyze scene images for gaze following. However, compared with visual images, audio also provides crucial cues for determining human behavior.This suggests that we can further improve gaze following considering audio cues. In this paper, we explore gaze following tasks in conversational scenarios. We propose a novel multi-modal gaze following framework based on our observation ``audiences tend to focus on the speaker''. We first leverage the correlation between audio and lips, and classify speakers and listeners in a scene. We then use the identity information to enhance scene images and propose a gaze candidate estimation network. The network estimates gaze candidates from enhanced scene images and we use MLP to match subjects with candidates as classification tasks. Existing gaze following datasets focus on visual images while ignore audios.To evaluate our method, we collect a conversational dataset, VideoGazeSpeech (VGS), which is the first gaze following dataset including images and audio. Our method significantly outperforms existing methods in VGS datasets. The visualization result also prove the advantage of audio cues in gaze following tasks. Our work will inspire more researches in multi-modal gaze following estimation.
CacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023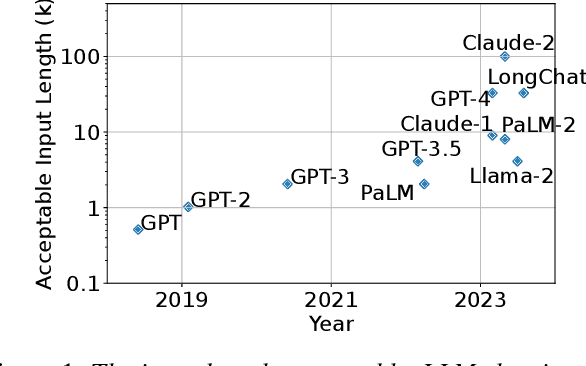

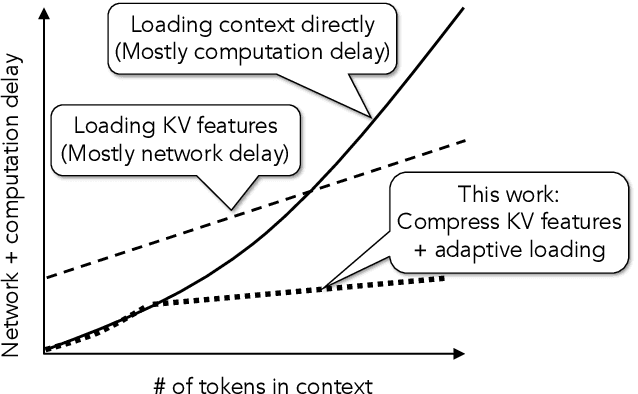
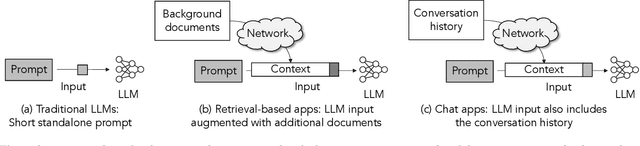
As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.
High-Fidelity Eye Animatable Neural Radiance Fields for Human Face
Aug 22, 2023



Face rendering using neural radiance fields (NeRF) is a rapidly developing research area in computer vision. While recent methods primarily focus on controlling facial attributes such as identity and expression, they often overlook the crucial aspect of modeling eyeball rotation, which holds importance for various downstream tasks. In this paper, we aim to learn a face NeRF model that is sensitive to eye movements from multi-view images. We address two key challenges in eye-aware face NeRF learning: how to effectively capture eyeball rotation for training and how to construct a manifold for representing eyeball rotation. To accomplish this, we first fit FLAME, a well-established parametric face model, to the multi-view images considering multi-view consistency. Subsequently, we introduce a new Dynamic Eye-aware NeRF (DeNeRF). DeNeRF transforms 3D points from different views into a canonical space to learn a unified face NeRF model. We design an eye deformation field for the transformation, including rigid transformation, e.g., eyeball rotation, and non-rigid transformation. Through experiments conducted on the ETH-XGaze dataset, we demonstrate that our model is capable of generating high-fidelity images with accurate eyeball rotation and non-rigid periocular deformation, even under novel viewing angles. Furthermore, we show that utilizing the rendered images can effectively enhance gaze estimation performance.
DVGaze: Dual-View Gaze Estimation
Aug 20, 2023



Gaze estimation methods estimate gaze from facial appearance with a single camera. However, due to the limited view of a single camera, the captured facial appearance cannot provide complete facial information and thus complicate the gaze estimation problem. Recently, camera devices are rapidly updated. Dual cameras are affordable for users and have been integrated in many devices. This development suggests that we can further improve gaze estimation performance with dual-view gaze estimation. In this paper, we propose a dual-view gaze estimation network (DV-Gaze). DV-Gaze estimates dual-view gaze directions from a pair of images. We first propose a dual-view interactive convolution (DIC) block in DV-Gaze. DIC blocks exchange dual-view information during convolution in multiple feature scales. It fuses dual-view features along epipolar lines and compensates for the original feature with the fused feature. We further propose a dual-view transformer to estimate gaze from dual-view features. Camera poses are encoded to indicate the position information in the transformer. We also consider the geometric relation between dual-view gaze directions and propose a dual-view gaze consistency loss for DV-Gaze. DV-Gaze achieves state-of-the-art performance on ETH-XGaze and EVE datasets. Our experiments also prove the potential of dual-view gaze estimation. We release codes in https://github.com/yihuacheng/DVGaze.
Grace++: Loss-Resilient Real-Time Video Communication under High Network Latency
May 21, 2023



In real-time videos, resending any packets, especially in networks with high latency, can lead to stuttering, poor video quality, and user frustration. Despite extensive research, current real-time video systems still use redundancy to handle packet loss, thus compromising on quality in the the absence of packet loss. Since predicting packet loss is challenging, these systems only enhance their resilience to packet loss after it occurs, leaving some frames insufficiently protected against burst packet losses. They may also add too much redundancy even after the packet loss has subsided. We present Grace++, a new real-time video communication system. With Grace++, (i) a video frame can be decoded, as long as any non-empty subset of its packets are received, and (ii) the quality gracefully degrades as more packets are lost, and (iii) approximates that of a standard codec (like H.265) in absence of packet loss. To achieve this, Grace++ encodes and decodes frames by using neural networks (NNs). It uses a new packetization scheme that makes packet loss appear to have the same effect as randomly masking (zeroing) a subset of elements in the NN-encoded output, and the NN encoder and decoder are specially trained to achieve decent quality if a random subset of elements in the NN-encoded output are masked. Using various test videos and real network traces, we show that the quality of Grace++ is slightly lower than H.265 when no packets are lost, but significantly reduces the 95th percentile of frame delay (between encoding a frame and its decoding) by 2x when packet loss occurs compared to other loss-resilient schemes while achieving comparable quality. This is because Grace++ does not require retransmission of packets (unless all packets are lost) or skipping of frames.
Gaze Estimation using Transformer
May 30, 2021



Recent work has proven the effectiveness of transformers in many computer vision tasks. However, the performance of transformers in gaze estimation is still unexplored. In this paper, we employ transformers and assess their effectiveness for gaze estimation. We consider two forms of vision transformer which are pure transformers and hybrid transformers. We first follow the popular ViT and employ a pure transformer to estimate gaze from images. On the other hand, we preserve the convolutional layers and integrate CNNs as well as transformers. The transformer serves as a component to complement CNNs. We compare the performance of the two transformers in gaze estimation. The Hybrid transformer significantly outperforms the pure transformer in all evaluation datasets with less parameters. We further conduct experiments to assess the effectiveness of the hybrid transformer and explore the advantage of self-attention mechanism. Experiments show the hybrid transformer can achieve state-of-the-art performance in all benchmarks with pre-training.To facilitate further research, we release codes and models in https://github.com/yihuacheng/GazeTR.
Appearance-based Gaze Estimation With Deep Learning: A Review and Benchmark
Apr 26, 2021



Gaze estimation reveals where a person is looking. It is an important clue for understanding human intention. The recent development of deep learning has revolutionized many computer vision tasks, the appearance-based gaze estimation is no exception. However, it lacks a guideline for designing deep learning algorithms for gaze estimation tasks. In this paper, we present a comprehensive review of the appearance-based gaze estimation methods with deep learning. We summarize the processing pipeline and discuss these methods from four perspectives: deep feature extraction, deep neural network architecture design, personal calibration as well as device and platform. Since the data pre-processing and post-processing methods are crucial for gaze estimation, we also survey face/eye detection method, data rectification method, 2D/3D gaze conversion method, and gaze origin conversion method. To fairly compare the performance of various gaze estimation approaches, we characterize all the publicly available gaze estimation datasets and collect the code of typical gaze estimation algorithms. We implement these codes and set up a benchmark of converting the results of different methods into the same evaluation metrics. This paper not only serves as a reference to develop deep learning-based gaze estimation methods but also a guideline for future gaze estimation research. Implemented methods and data processing codes are available at http://phi-ai.org/GazeHub.