 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYimin Jiang
Scene-Adaptive Person Search via Bilateral Modulations
May 05, 2024
Person search aims to localize specific a target person from a gallery set of images with various scenes. As the scene of moving pedestrian changes, the captured person image inevitably bring in lots of background noise and foreground noise on the person feature, which are completely unrelated to the person identity, leading to severe performance degeneration. To address this issue, we present a Scene-Adaptive Person Search (SEAS) model by introducing bilateral modulations to simultaneously eliminate scene noise and maintain a consistent person representation to adapt to various scenes. In SEAS, a Background Modulation Network (BMN) is designed to encode the feature extracted from the detected bounding box into a multi-granularity embedding, which reduces the input of background noise from multiple levels with norm-aware. Additionally, to mitigate the effect of foreground noise on the person feature, SEAS introduces a Foreground Modulation Network (FMN) to compute the clutter reduction offset for the person embedding based on the feature map of the scene image. By bilateral modulations on both background and foreground within an end-to-end manner, SEAS obtains consistent feature representations without scene noise. SEAS can achieve state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU with 97.1\% mAP and PRW with 60.5\% mAP. The code is available at https://github.com/whbdmu/SEAS.
Adaptive Gating in Mixture-of-Experts based Language Models
Oct 11, 2023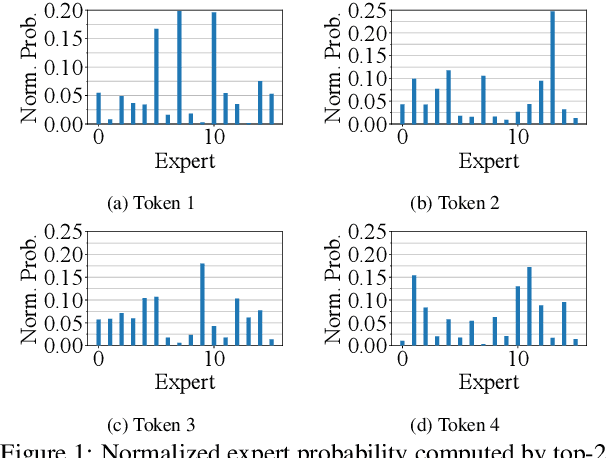


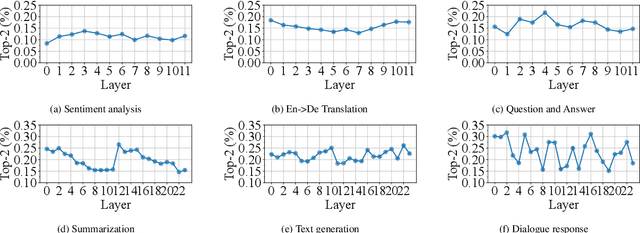
Large language models, such as OpenAI's ChatGPT, have demonstrated exceptional language understanding capabilities in various NLP tasks. Sparsely activated mixture-of-experts (MoE) has emerged as a promising solution for scaling models while maintaining a constant number of computational operations. Existing MoE model adopts a fixed gating network where each token is computed by the same number of experts. However, this approach contradicts our intuition that the tokens in each sequence vary in terms of their linguistic complexity and, consequently, require different computational costs. Little is discussed in prior research on the trade-off between computation per token and model performance. This paper introduces adaptive gating in MoE, a flexible training strategy that allows tokens to be processed by a variable number of experts based on expert probability distribution. The proposed framework preserves sparsity while improving training efficiency. Additionally, curriculum learning is leveraged to further reduce training time. Extensive experiments on diverse NLP tasks show that adaptive gating reduces at most 22.5% training time while maintaining inference quality. Moreover, we conduct a comprehensive analysis of the routing decisions and present our insights when adaptive gating is used.