 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiming Chen
Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
Mar 19, 2024

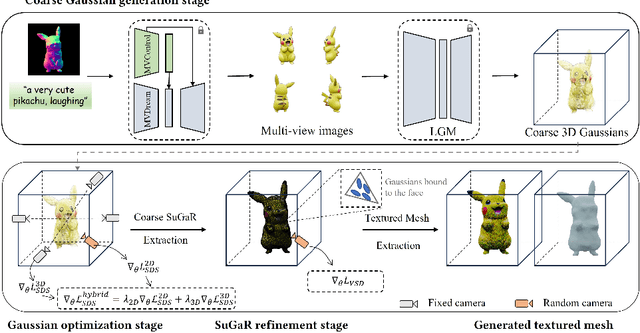

While text-to-3D and image-to-3D generation tasks have received considerable attention, one important but under-explored field between them is controllable text-to-3D generation, which we mainly focus on in this work. To address this task, 1) we introduce Multi-view ControlNet (MVControl), a novel neural network architecture designed to enhance existing pre-trained multi-view diffusion models by integrating additional input conditions, such as edge, depth, normal, and scribble maps. Our innovation lies in the introduction of a conditioning module that controls the base diffusion model using both local and global embeddings, which are computed from the input condition images and camera poses. Once trained, MVControl is able to offer 3D diffusion guidance for optimization-based 3D generation. And, 2) we propose an efficient multi-stage 3D generation pipeline that leverages the benefits of recent large reconstruction models and score distillation algorithm. Building upon our MVControl architecture, we employ a unique hybrid diffusion guidance method to direct the optimization process. In pursuit of efficiency, we adopt 3D Gaussians as our representation instead of the commonly used implicit representations. We also pioneer the use of SuGaR, a hybrid representation that binds Gaussians to mesh triangle faces. This approach alleviates the issue of poor geometry in 3D Gaussians and enables the direct sculpting of fine-grained geometry on the mesh. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content.
A Comprehensive Analysis of the Effectiveness of Large Language Models as Automatic Dialogue Evaluators
Dec 24, 2023Automatic evaluation is an integral aspect of dialogue system research. The traditional reference-based NLG metrics are generally found to be unsuitable for dialogue assessment. Consequently, recent studies have suggested various unique, reference-free neural metrics that better align with human evaluations. Notably among them, large language models (LLMs), particularly the instruction-tuned variants like ChatGPT, are shown to be promising substitutes for human judges. Yet, existing works on utilizing LLMs for automatic dialogue evaluation are limited in their scope in terms of the number of meta-evaluation datasets, mode of evaluation, coverage of LLMs, etc. Hence, it remains inconclusive how effective these LLMs are. To this end, we conduct a comprehensive study on the application of LLMs for automatic dialogue evaluation. Specifically, we analyze the multi-dimensional evaluation capability of 30 recently emerged LLMs at both turn and dialogue levels, using a comprehensive set of 12 meta-evaluation datasets. Additionally, we probe the robustness of the LLMs in handling various adversarial perturbations at both turn and dialogue levels. Finally, we explore how model-level and dimension-level ensembles impact the evaluation performance. All resources are available at https://github.com/e0397123/comp-analysis.
Progressive Poisoned Data Isolation for Training-time Backdoor Defense
Dec 20, 2023Deep Neural Networks (DNN) are susceptible to backdoor attacks where malicious attackers manipulate the model's predictions via data poisoning. It is hence imperative to develop a strategy for training a clean model using a potentially poisoned dataset. Previous training-time defense mechanisms typically employ an one-time isolation process, often leading to suboptimal isolation outcomes. In this study, we present a novel and efficacious defense method, termed Progressive Isolation of Poisoned Data (PIPD), that progressively isolates poisoned data to enhance the isolation accuracy and mitigate the risk of benign samples being misclassified as poisoned ones. Once the poisoned portion of the dataset has been identified, we introduce a selective training process to train a clean model. Through the implementation of these techniques, we ensure that the trained model manifests a significantly diminished attack success rate against the poisoned data. Extensive experiments on multiple benchmark datasets and DNN models, assessed against nine state-of-the-art backdoor attacks, demonstrate the superior performance of our PIPD method for backdoor defense. For instance, our PIPD achieves an average True Positive Rate (TPR) of 99.95% and an average False Positive Rate (FPR) of 0.06% for diverse attacks over CIFAR-10 dataset, markedly surpassing the performance of state-of-the-art methods.
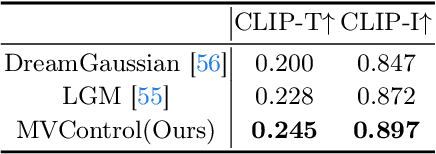
MVControl: Adding Conditional Control to Multi-view Diffusion for Controllable Text-to-3D Generation
Nov 27, 2023We introduce MVControl, a novel neural network architecture that enhances existing pre-trained multi-view 2D diffusion models by incorporating additional input conditions, e.g. edge maps. Our approach enables the generation of controllable multi-view images and view-consistent 3D content. To achieve controllable multi-view image generation, we leverage MVDream as our base model, and train a new neural network module as additional plugin for end-to-end task-specific condition learning. To precisely control the shapes and views of generated images, we innovatively propose a new conditioning mechanism that predicts an embedding encapsulating the input spatial and view conditions, which is then injected to the network globally. Once MVControl is trained, score-distillation (SDS) loss based optimization can be performed to generate 3D content, in which process we propose to use a hybrid diffusion prior. The hybrid prior relies on a pre-trained Stable-Diffusion network and our trained MVControl for additional guidance. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content. Code available at https://github.com/WU-CVGL/MVControl/.
ET3D: Efficient Text-to-3D Generation via Multi-View Distillation
Nov 27, 2023Recent breakthroughs in text-to-image generation has shown encouraging results via large generative models. Due to the scarcity of 3D assets, it is hardly to transfer the success of text-to-image generation to that of text-to-3D generation. Existing text-to-3D generation methods usually adopt the paradigm of DreamFusion, which conducts per-asset optimization by distilling a pretrained text-to-image diffusion model. The generation speed usually ranges from several minutes to tens of minutes per 3D asset, which degrades the user experience and also imposes a burden to the service providers due to the high computational budget. In this work, we present an efficient text-to-3D generation method, which requires only around 8 $ms$ to generate a 3D asset given the text prompt on a consumer graphic card. The main insight is that we exploit the images generated by a large pre-trained text-to-image diffusion model, to supervise the training of a text conditioned 3D generative adversarial network. Once the network is trained, we are able to efficiently generate a 3D asset via a single forward pass. Our method requires no 3D training data and provides an alternative approach for efficient text-to-3D generation by distilling pre-trained image diffusion models.
Rethinking Image Forgery Detection via Contrastive Learning and Unsupervised Clustering
Aug 18, 2023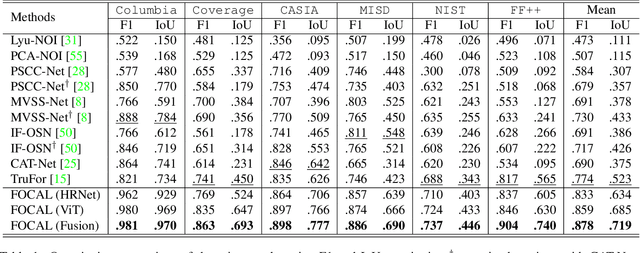

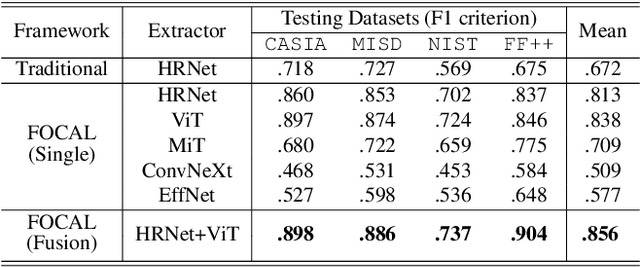
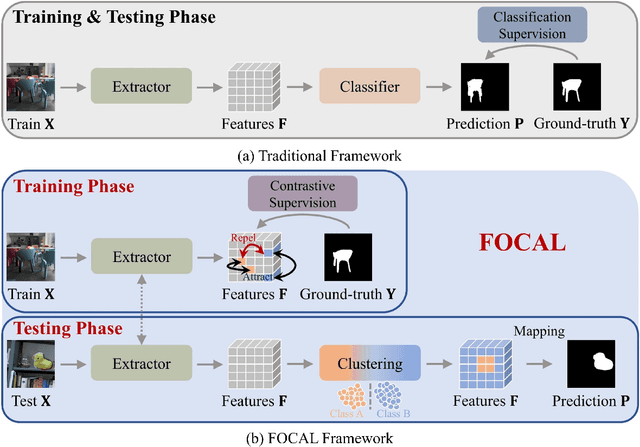
Image forgery detection aims to detect and locate forged regions in an image. Most existing forgery detection algorithms formulate classification problems to classify pixels into forged or pristine. However, the definition of forged and pristine pixels is only relative within one single image, e.g., a forged region in image A is actually a pristine one in its source image B (splicing forgery). Such a relative definition has been severely overlooked by existing methods, which unnecessarily mix forged (pristine) regions across different images into the same category. To resolve this dilemma, we propose the FOrensic ContrAstive cLustering (FOCAL) method, a novel, simple yet very effective paradigm based on contrastive learning and unsupervised clustering for the image forgery detection. Specifically, FOCAL 1) utilizes pixel-level contrastive learning to supervise the high-level forensic feature extraction in an image-by-image manner, explicitly reflecting the above relative definition; 2) employs an on-the-fly unsupervised clustering algorithm (instead of a trained one) to cluster the learned features into forged/pristine categories, further suppressing the cross-image influence from training data; and 3) allows to further boost the detection performance via simple feature-level concatenation without the need of retraining. Extensive experimental results over six public testing datasets demonstrate that our proposed FOCAL significantly outperforms the state-of-the-art competing algorithms by big margins: +24.3% on Coverage, +18.6% on Columbia, +17.5% on FF++, +14.2% on MISD, +13.5% on CASIA and +10.3% on NIST in terms of IoU. The paradigm of FOCAL could bring fresh insights and serve as a novel benchmark for the image forgery detection task. The code is available at https://github.com/HighwayWu/FOCAL.
TL-nvSRAM-CIM: Ultra-High-Density Three-Level ReRAM-Assisted Computing-in-nvSRAM with DC-Power Free Restore and Ternary MAC Operations
Jul 06, 2023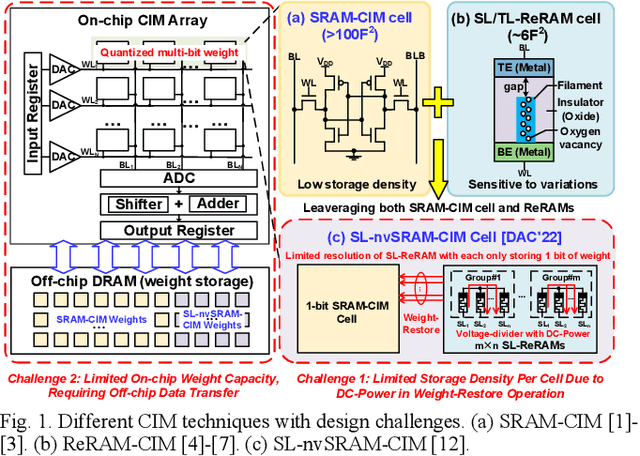
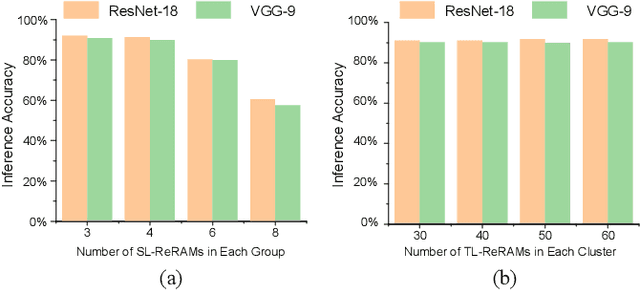
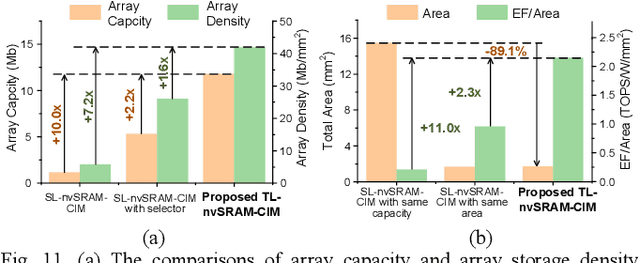
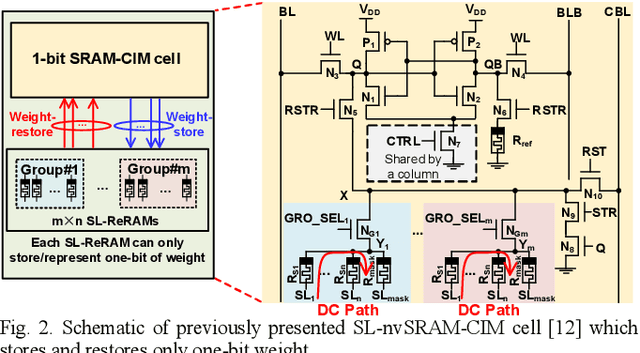
Accommodating all the weights on-chip for large-scale NNs remains a great challenge for SRAM based computing-in-memory (SRAM-CIM) with limited on-chip capacity. Previous non-volatile SRAM-CIM (nvSRAM-CIM) addresses this issue by integrating high-density single-level ReRAMs on the top of high-efficiency SRAM-CIM for weight storage to eliminate the off-chip memory access. However, previous SL-nvSRAM-CIM suffers from poor scalability for an increased number of SL-ReRAMs and limited computing efficiency. To overcome these challenges, this work proposes an ultra-high-density three-level ReRAMs-assisted computing-in-nonvolatile-SRAM (TL-nvSRAM-CIM) scheme for large NN models. The clustered n-selector-n-ReRAM (cluster-nSnRs) is employed for reliable weight-restore with eliminated DC power. Furthermore, a ternary SRAM-CIM mechanism with differential computing scheme is proposed for energy-efficient ternary MAC operations while preserving high NN accuracy. The proposed TL-nvSRAM-CIM achieves 7.8x higher storage density, compared with the state-of-art works. Moreover, TL-nvSRAM-CIM shows up to 2.9x and 1.9x enhanced energy-efficiency, respectively, compared to the baseline designs of SRAM-CIM and ReRAM-CIM, respectively.
Enhancing Black-Box Few-Shot Text Classification with Prompt-Based Data Augmentation
May 23, 2023
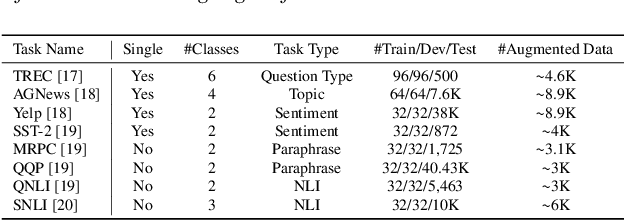
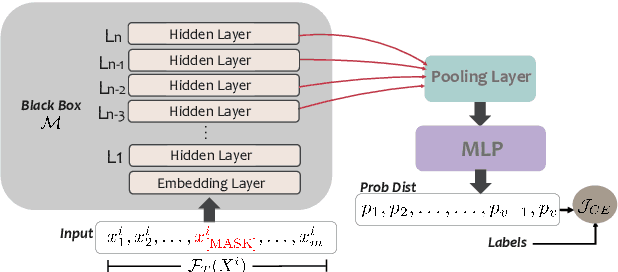
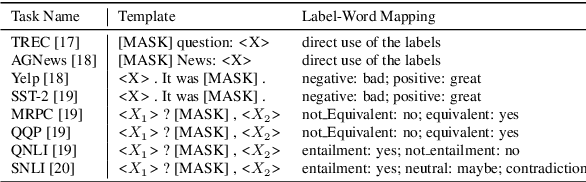
Training or finetuning large-scale language models (LLMs) such as GPT-3 requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One practical area of research is to treat these models as black boxes and interact with them through their inference APIs. In this paper, we investigate how to optimize few-shot text classification without accessing the gradients of the LLMs. To achieve this, we treat the black-box model as a feature extractor and train a classifier with the augmented text data. Data augmentation is performed using prompt-based finetuning on an auxiliary language model with a much smaller parameter size than the black-box model. Through extensive experiments on eight text classification datasets, we show that our approach, dubbed BT-Classifier, significantly outperforms state-of-the-art black-box few-shot learners and performs on par with methods that rely on full-model tuning.
Dynamic Transformers Provide a False Sense of Efficiency
May 20, 2023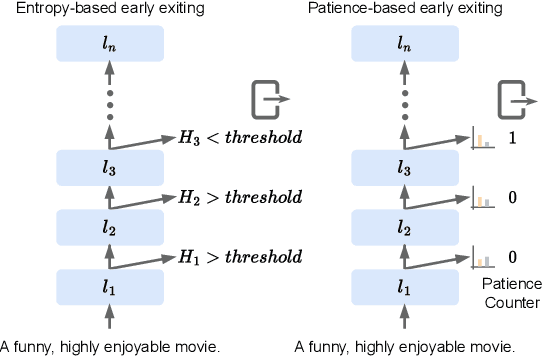
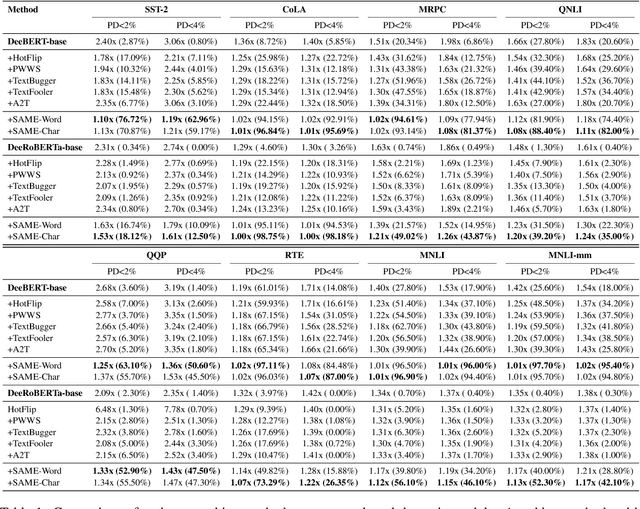
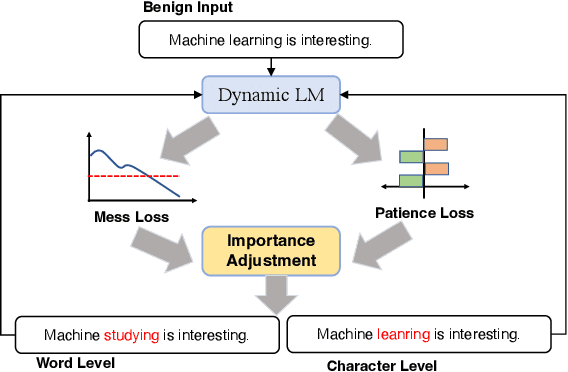
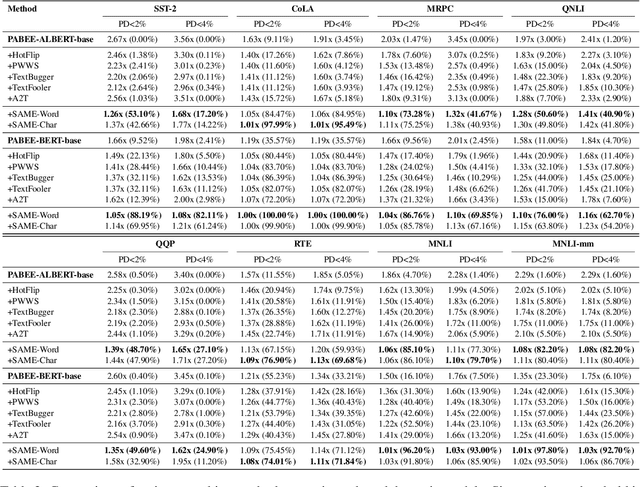
Despite much success in natural language processing (NLP), pre-trained language models typically lead to a high computational cost during inference. Multi-exit is a mainstream approach to address this issue by making a trade-off between efficiency and accuracy, where the saving of computation comes from an early exit. However, whether such saving from early-exiting is robust remains unknown. Motivated by this, we first show that directly adapting existing adversarial attack approaches targeting model accuracy cannot significantly reduce inference efficiency. To this end, we propose a simple yet effective attacking framework, SAME, a novel slowdown attack framework on multi-exit models, which is specially tailored to reduce the efficiency of the multi-exit models. By leveraging the multi-exit models' design characteristics, we utilize all internal predictions to guide the adversarial sample generation instead of merely considering the final prediction. Experiments on the GLUE benchmark show that SAME can effectively diminish the efficiency gain of various multi-exit models by 80% on average, convincingly validating its effectiveness and generalization ability.
Lower Bounds and Accelerated Algorithms in Distributed Stochastic Optimization with Communication Compression
May 12, 2023
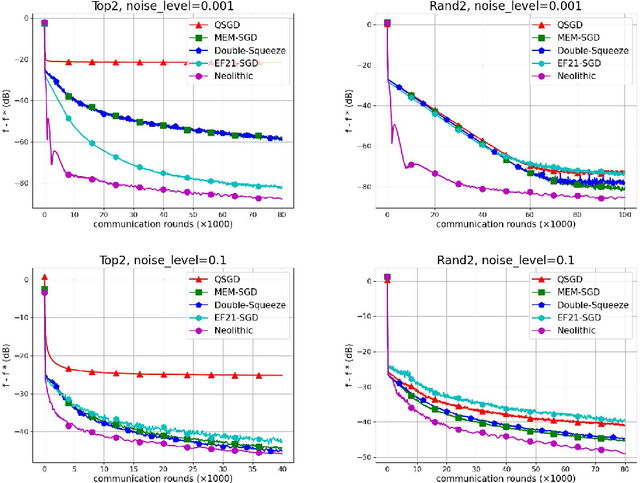

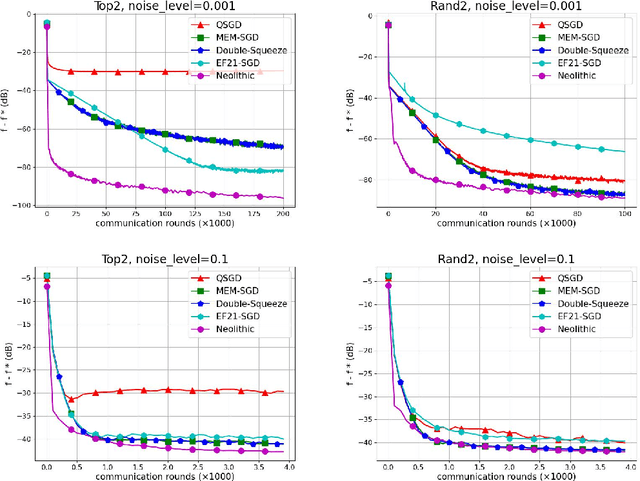
Communication compression is an essential strategy for alleviating communication overhead by reducing the volume of information exchanged between computing nodes in large-scale distributed stochastic optimization. Although numerous algorithms with convergence guarantees have been obtained, the optimal performance limit under communication compression remains unclear. In this paper, we investigate the performance limit of distributed stochastic optimization algorithms employing communication compression. We focus on two main types of compressors, unbiased and contractive, and address the best-possible convergence rates one can obtain with these compressors. We establish the lower bounds for the convergence rates of distributed stochastic optimization in six different settings, combining strongly-convex, generally-convex, or non-convex functions with unbiased or contractive compressor types. To bridge the gap between lower bounds and existing algorithms' rates, we propose NEOLITHIC, a nearly optimal algorithm with compression that achieves the established lower bounds up to logarithmic factors under mild conditions. Extensive experimental results support our theoretical findings. This work provides insights into the theoretical limitations of existing compressors and motivates further research into fundamentally new compressor properties.