 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYinggui Wang
Privacy-Preserving End-to-End Spoken Language Understanding
Mar 22, 2024
Spoken language understanding (SLU), one of the key enabling technologies for human-computer interaction in IoT devices, provides an easy-to-use user interface. Human speech can contain a lot of user-sensitive information, such as gender, identity, and sensitive content. New types of security and privacy breaches have thus emerged. Users do not want to expose their personal sensitive information to malicious attacks by untrusted third parties. Thus, the SLU system needs to ensure that a potential malicious attacker cannot deduce the sensitive attributes of the users, while it should avoid greatly compromising the SLU accuracy. To address the above challenge, this paper proposes a novel SLU multi-task privacy-preserving model to prevent both the speech recognition (ASR) and identity recognition (IR) attacks. The model uses the hidden layer separation technique so that SLU information is distributed only in a specific portion of the hidden layer, and the other two types of information are removed to obtain a privacy-secure hidden layer. In order to achieve good balance between efficiency and privacy, we introduce a new mechanism of model pre-training, namely joint adversarial training, to further enhance the user privacy. Experiments over two SLU datasets show that the proposed method can reduce the accuracy of both the ASR and IR attacks close to that of a random guess, while leaving the SLU performance largely unaffected.
Adaptive Hybrid Masking Strategy for Privacy-Preserving Face Recognition Against Model Inversion Attack
Mar 14, 2024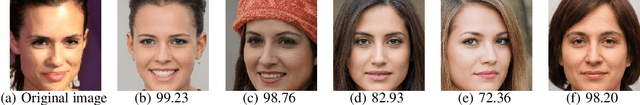

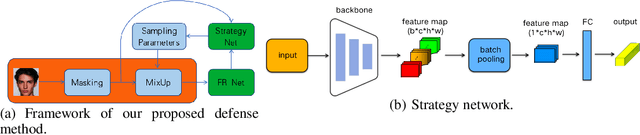
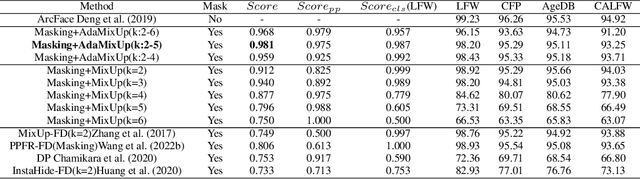
The utilization of personal sensitive data in training face recognition (FR) models poses significant privacy concerns, as adversaries can employ model inversion attacks (MIA) to infer the original training data. Existing defense methods, such as data augmentation and differential privacy, have been employed to mitigate this issue. However, these methods often fail to strike an optimal balance between privacy and accuracy. To address this limitation, this paper introduces an adaptive hybrid masking algorithm against MIA. Specifically, face images are masked in the frequency domain using an adaptive MixUp strategy. Unlike the traditional MixUp algorithm, which is predominantly used for data augmentation, our modified approach incorporates frequency domain mixing. Previous studies have shown that increasing the number of images mixed in MixUp can enhance privacy preservation but at the expense of reduced face recognition accuracy. To overcome this trade-off, we develop an enhanced adaptive MixUp strategy based on reinforcement learning, which enables us to mix a larger number of images while maintaining satisfactory recognition accuracy. To optimize privacy protection, we propose maximizing the reward function (i.e., the loss function of the FR system) during the training of the strategy network. While the loss function of the FR network is minimized in the phase of training the FR network. The strategy network and the face recognition network can be viewed as antagonistic entities in the training process, ultimately reaching a more balanced trade-off. Experimental results demonstrate that our proposed hybrid masking scheme outperforms existing defense algorithms in terms of privacy preservation and recognition accuracy against MIA.
Inference Attacks Against Face Recognition Model without Classification Layers
Jan 24, 2024Face recognition (FR) has been applied to nearly every aspect of daily life, but it is always accompanied by the underlying risk of leaking private information. At present, almost all attack models against FR rely heavily on the presence of a classification layer. However, in practice, the FR model can obtain complex features of the input via the model backbone, and then compare it with the target for inference, which does not explicitly involve the outputs of the classification layer adopting logit or other losses. In this work, we advocate a novel inference attack composed of two stages for practical FR models without a classification layer. The first stage is the membership inference attack. Specifically, We analyze the distances between the intermediate features and batch normalization (BN) parameters. The results indicate that this distance is a critical metric for membership inference. We thus design a simple but effective attack model that can determine whether a face image is from the training dataset or not. The second stage is the model inversion attack, where sensitive private data is reconstructed using a pre-trained generative adversarial network (GAN) guided by the attack model in the first stage. To the best of our knowledge, the proposed attack model is the very first in the literature developed for FR models without a classification layer. We illustrate the application of the proposed attack model in the establishment of privacy-preserving FR techniques.
A Fast, Performant, Secure Distributed Training Framework For Large Language Model
Jan 19, 2024The distributed (federated) LLM is an important method for co-training the domain-specific LLM using siloed data. However, maliciously stealing model parameters and data from the server or client side has become an urgent problem to be solved. In this paper, we propose a secure distributed LLM based on model slicing. In this case, we deploy the Trusted Execution Environment (TEE) on both the client and server side, and put the fine-tuned structure (LoRA or embedding of P-tuning v2) into the TEE. Then, secure communication is executed in the TEE and general environments through lightweight encryption. In order to further reduce the equipment cost as well as increase the model performance and accuracy, we propose a split fine-tuning scheme. In particular, we split the LLM by layers and place the latter layers in a server-side TEE (the client does not need a TEE). We then combine the proposed Sparsification Parameter Fine-tuning (SPF) with the LoRA part to improve the accuracy of the downstream task. Numerous experiments have shown that our method guarantees accuracy while maintaining security.
Flatness-aware Adversarial Attack
Nov 10, 2023The transferability of adversarial examples can be exploited to launch black-box attacks. However, adversarial examples often present poor transferability. To alleviate this issue, by observing that the diversity of inputs can boost transferability, input regularization based methods are proposed, which craft adversarial examples by combining several transformed inputs. We reveal that input regularization based methods make resultant adversarial examples biased towards flat extreme regions. Inspired by this, we propose an attack called flatness-aware adversarial attack (FAA) which explicitly adds a flatness-aware regularization term in the optimization target to promote the resultant adversarial examples towards flat extreme regions. The flatness-aware regularization term involves gradients of samples around the resultant adversarial examples but optimizing gradients requires the evaluation of Hessian matrix in high-dimension spaces which generally is intractable. To address the problem, we derive an approximate solution to circumvent the construction of Hessian matrix, thereby making FAA practical and cheap. Extensive experiments show the transferability of adversarial examples crafted by FAA can be considerably boosted compared with state-of-the-art baselines.
You Can Backdoor Personalized Federated Learning
Jul 29, 2023



Backdoor attacks pose a significant threat to the security of federated learning systems. However, existing research primarily focuses on backdoor attacks and defenses within the generic FL scenario, where all clients collaborate to train a single global model. \citet{qin2023revisiting} conduct the first study of backdoor attacks in the personalized federated learning (pFL) scenario, where each client constructs a personalized model based on its local data. Notably, the study demonstrates that pFL methods with partial model-sharing can significantly boost robustness against backdoor attacks. In this paper, we whistleblow that pFL methods with partial model-sharing are still vulnerable to backdoor attacks in the absence of any defense. We propose three backdoor attack methods: BapFL, BapFL+, and Gen-BapFL, and we empirically demonstrate that they can effectively attack the pFL methods. Specifically, the key principle of BapFL lies in maintaining clean local parameters while implanting the backdoor into the global parameters. BapFL+ generalizes the attack success to benign clients by introducing Gaussian noise to the local parameters. Furthermore, we assume the collaboration of malicious clients and propose Gen-BapFL, which leverages meta-learning techniques to further enhances attack generalization. We evaluate our proposed attack methods against two classic pFL methods with partial model-sharing, FedPer and LG-FedAvg. Extensive experiments on four FL benchmark datasets demonstrate the effectiveness of our proposed attack methods. Additionally, we assess the defense efficacy of various defense strategies against our proposed attacks and find that Gradient Norm-Clipping is particularly effective. It is crucial to note that pFL method is not always secure in the presence of backdoor attacks, and we hope to inspire further research on attack and defense in pFL scenarios.
UPFL: Unsupervised Personalized Federated Learning towards New Clients
Jul 29, 2023



Personalized federated learning has gained significant attention as a promising approach to address the challenge of data heterogeneity. In this paper, we address a relatively unexplored problem in federated learning. When a federated model has been trained and deployed, and an unlabeled new client joins, providing a personalized model for the new client becomes a highly challenging task. To address this challenge, we extend the adaptive risk minimization technique into the unsupervised personalized federated learning setting and propose our method, FedTTA. We further improve FedTTA with two simple yet effective optimization strategies: enhancing the training of the adaptation model with proxy regularization and early-stopping the adaptation through entropy. Moreover, we propose a knowledge distillation loss specifically designed for FedTTA to address the device heterogeneity. Extensive experiments on five datasets against eleven baselines demonstrate the effectiveness of our proposed FedTTA and its variants. The code is available at: https://github.com/anonymous-federated-learning/code.