 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYinsong Xu
EviPrompt: A Training-Free Evidential Prompt Generation Method for Segment Anything Model in Medical Images
Nov 10, 2023
Medical image segmentation has immense clinical applicability but remains a challenge despite advancements in deep learning. The Segment Anything Model (SAM) exhibits potential in this field, yet the requirement for expertise intervention and the domain gap between natural and medical images poses significant obstacles. This paper introduces a novel training-free evidential prompt generation method named EviPrompt to overcome these issues. The proposed method, built on the inherent similarities within medical images, requires only a single reference image-annotation pair, making it a training-free solution that significantly reduces the need for extensive labeling and computational resources. First, to automatically generate prompts for SAM in medical images, we introduce an evidential method based on uncertainty estimation without the interaction of clinical experts. Then, we incorporate the human prior into the prompts, which is vital for alleviating the domain gap between natural and medical images and enhancing the applicability and usefulness of SAM in medical scenarios. EviPrompt represents an efficient and robust approach to medical image segmentation, with evaluations across a broad range of tasks and modalities confirming its efficacy.
Incorporating Pre-training Data Matters in Unsupervised Domain Adaptation
Aug 06, 2023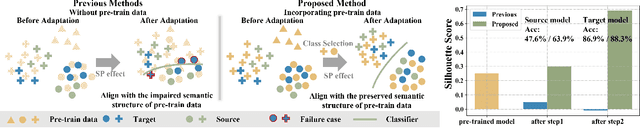

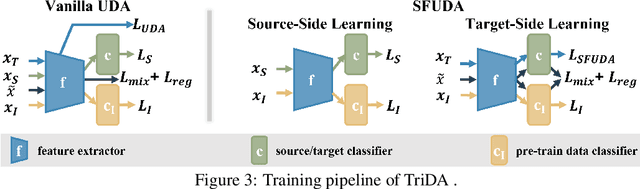
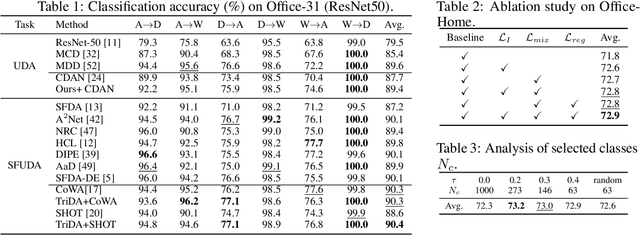
Unsupervised domain adaptation(UDA) and Source-free UDA(SFUDA) methods formulate the problem involving two domains: source and target. They typically employ a standard training approach that begins with models pre-trained on large-scale datasets e.g., ImageNet, while rarely discussing its effect. Recognizing this gap, we investigate the following research questions: (1) What is the correlation among ImageNet, the source, and the target domain? (2) How does pre-training on ImageNet influence the target risk? To answer the first question, we empirically observed an interesting Spontaneous Pulling (SP) Effect in fine-tuning where the discrepancies between any two of the three domains (ImageNet, Source, Target) decrease but at the cost of the impaired semantic structure of the pre-train domain. For the second question, we put forward a theory to explain SP and quantify that the target risk is bound by gradient disparities among the three domains. Our observations reveal a key limitation of existing methods: it hinders the adaptation performance if the semantic cluster structure of the pre-train dataset (i.e.ImageNet) is impaired. To address it, we incorporate ImageNet as the third domain and redefine the UDA/SFUDA as a three-player game. Specifically, inspired by the theory and empirical findings, we present a novel framework termed TriDA which additionally preserves the semantic structure of the pre-train dataset during fine-tuning. Experimental results demonstrate that it achieves state-of-the-art performance across various UDA and SFUDA benchmarks.
Delving into the Continuous Domain Adaptation
Aug 28, 2022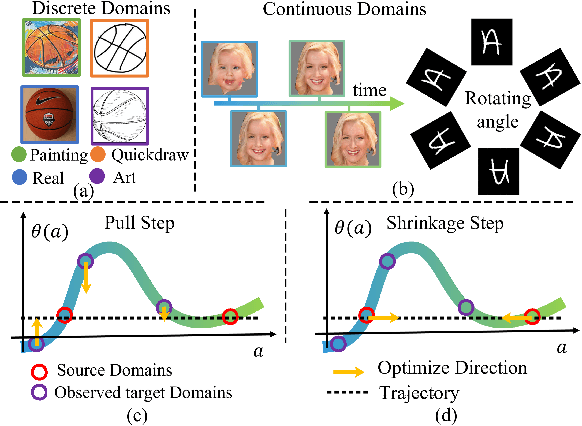

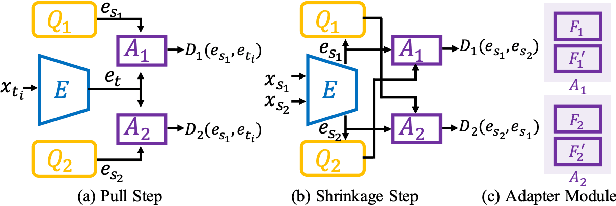
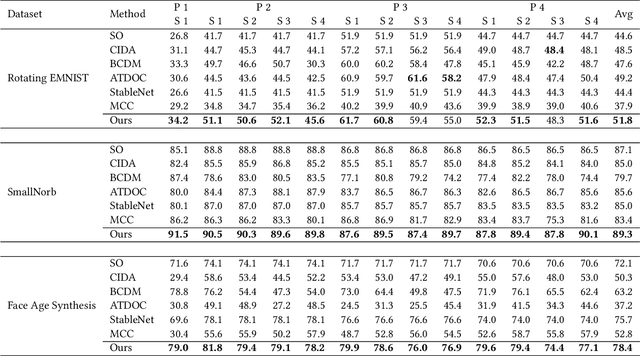
Existing domain adaptation methods assume that domain discrepancies are caused by a few discrete attributes and variations, e.g., art, real, painting, quickdraw, etc. We argue that this is not realistic as it is implausible to define the real-world datasets using a few discrete attributes. Therefore, we propose to investigate a new problem namely the Continuous Domain Adaptation (CDA) through the lens where infinite domains are formed by continuously varying attributes. Leveraging knowledge of two labeled source domains and several observed unlabeled target domains data, the objective of CDA is to learn a generalized model for whole data distribution with the continuous attribute. Besides the contributions of formulating a new problem, we also propose a novel approach as a strong CDA baseline. To be specific, firstly we propose a novel alternating training strategy to reduce discrepancies among multiple domains meanwhile generalize to unseen target domains. Secondly, we propose a continuity constraint when estimating the cross-domain divergence measurement. Finally, to decouple the discrepancy from the mini-batch size, we design a domain-specific queue to maintain the global view of the source domain that further boosts the adaptation performances. Our method is proven to achieve the state-of-the-art in CDA problem using extensive experiments. The code is available at https://github.com/SPIresearch/CDA.