 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYipeng Qin
LATUP-Net: A Lightweight 3D Attention U-Net with Parallel Convolutions for Brain Tumor Segmentation
Apr 09, 2024
Early-stage 3D brain tumor segmentation from magnetic resonance imaging (MRI) scans is crucial for prompt and effective treatment. However, this process faces the challenge of precise delineation due to the tumors' complex heterogeneity. Moreover, energy sustainability targets and resource limitations, especially in developing countries, require efficient and accessible medical imaging solutions. The proposed architecture, a Lightweight 3D ATtention U-Net with Parallel convolutions, LATUP-Net, addresses these issues. It is specifically designed to reduce computational requirements significantly while maintaining high segmentation performance. By incorporating parallel convolutions, it enhances feature representation by capturing multi-scale information. It further integrates an attention mechanism to refine segmentation through selective feature recalibration. LATUP-Net achieves promising segmentation performance: the average Dice scores for the whole tumor, tumor core, and enhancing tumor on the BraTS2020 dataset are 88.41%, 83.82%, and 73.67%, and on the BraTS2021 dataset, they are 90.29%, 89.54%, and 83.92%, respectively. Hausdorff distance metrics further indicate its improved ability to delineate tumor boundaries. With its significantly reduced computational demand using only 3.07 M parameters, about 59 times fewer than other state-of-the-art models, and running on a single V100 GPU, LATUP-Net stands out as a promising solution for real-world clinical applications, particularly in settings with limited resources. Investigations into the model's interpretability, utilizing gradient-weighted class activation mapping and confusion matrices, reveal that while attention mechanisms enhance the segmentation of small regions, their impact is nuanced. Achieving the most accurate tumor delineation requires carefully balancing local and global features.
NeRF-HuGS: Improved Neural Radiance Fields in Non-static Scenes Using Heuristics-Guided Segmentation
Mar 26, 2024

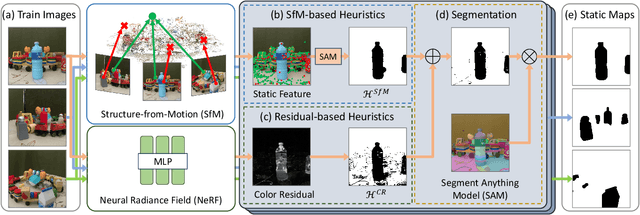

Neural Radiance Field (NeRF) has been widely recognized for its excellence in novel view synthesis and 3D scene reconstruction. However, their effectiveness is inherently tied to the assumption of static scenes, rendering them susceptible to undesirable artifacts when confronted with transient distractors such as moving objects or shadows. In this work, we propose a novel paradigm, namely "Heuristics-Guided Segmentation" (HuGS), which significantly enhances the separation of static scenes from transient distractors by harmoniously combining the strengths of hand-crafted heuristics and state-of-the-art segmentation models, thus significantly transcending the limitations of previous solutions. Furthermore, we delve into the meticulous design of heuristics, introducing a seamless fusion of Structure-from-Motion (SfM)-based heuristics and color residual heuristics, catering to a diverse range of texture profiles. Extensive experiments demonstrate the superiority and robustness of our method in mitigating transient distractors for NeRFs trained in non-static scenes. Project page: https://cnhaox.github.io/NeRF-HuGS/.
Deep Generative Model based Rate-Distortion for Image Downscaling Assessment
Mar 22, 2024In this paper, we propose Image Downscaling Assessment by Rate-Distortion (IDA-RD), a novel measure to quantitatively evaluate image downscaling algorithms. In contrast to image-based methods that measure the quality of downscaled images, ours is process-based that draws ideas from rate-distortion theory to measure the distortion incurred during downscaling. Our main idea is that downscaling and super-resolution (SR) can be viewed as the encoding and decoding processes in the rate-distortion model, respectively, and that a downscaling algorithm that preserves more details in the resulting low-resolution (LR) images should lead to less distorted high-resolution (HR) images in SR. In other words, the distortion should increase as the downscaling algorithm deteriorates. However, it is non-trivial to measure this distortion as it requires the SR algorithm to be blind and stochastic. Our key insight is that such requirements can be met by recent SR algorithms based on deep generative models that can find all matching HR images for a given LR image on their learned image manifolds. Extensive experimental results show the effectiveness of our IDA-RD measure.
PICTURE: PhotorealistIC virtual Try-on from UnconstRained dEsigns
Dec 07, 2023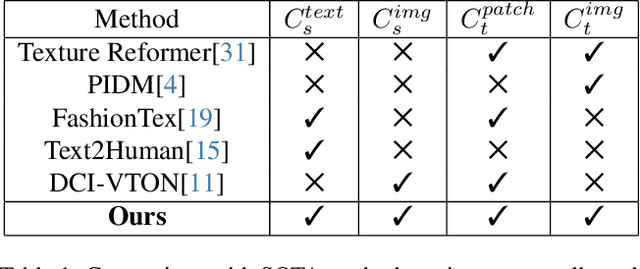
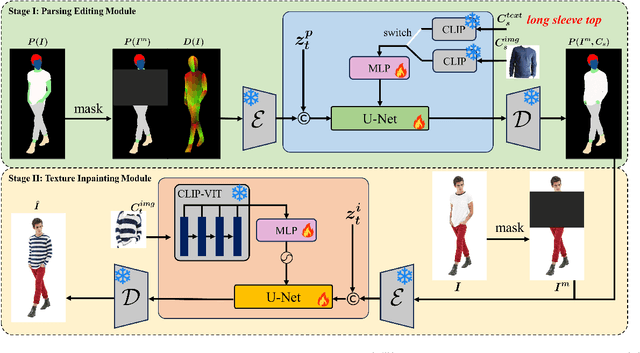
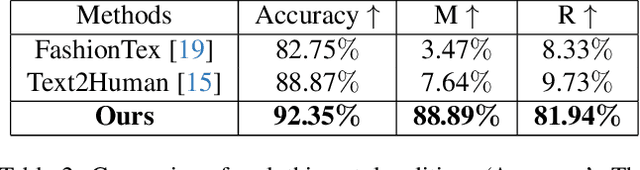
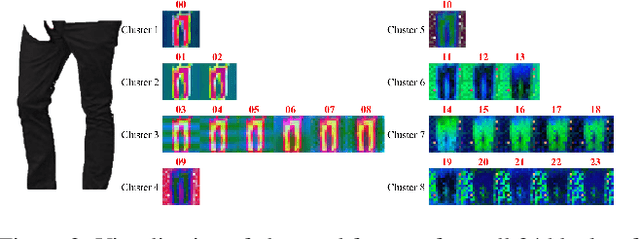
In this paper, we propose a novel virtual try-on from unconstrained designs (ucVTON) task to enable photorealistic synthesis of personalized composite clothing on input human images. Unlike prior arts constrained by specific input types, our method allows flexible specification of style (text or image) and texture (full garment, cropped sections, or texture patches) conditions. To address the entanglement challenge when using full garment images as conditions, we develop a two-stage pipeline with explicit disentanglement of style and texture. In the first stage, we generate a human parsing map reflecting the desired style conditioned on the input. In the second stage, we composite textures onto the parsing map areas based on the texture input. To represent complex and non-stationary textures that have never been achieved in previous fashion editing works, we first propose extracting hierarchical and balanced CLIP features and applying position encoding in VTON. Experiments demonstrate superior synthesis quality and personalization enabled by our method. The flexible control over style and texture mixing brings virtual try-on to a new level of user experience for online shopping and fashion design.
Feature Proliferation -- the "Cancer" in StyleGAN and its Treatments
Oct 13, 2023
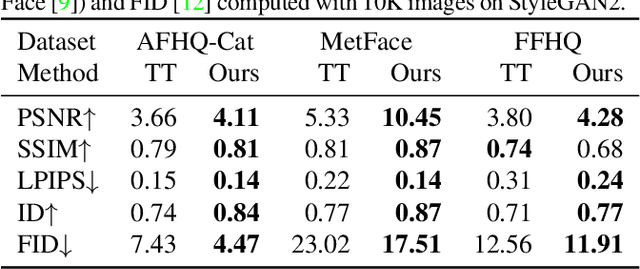
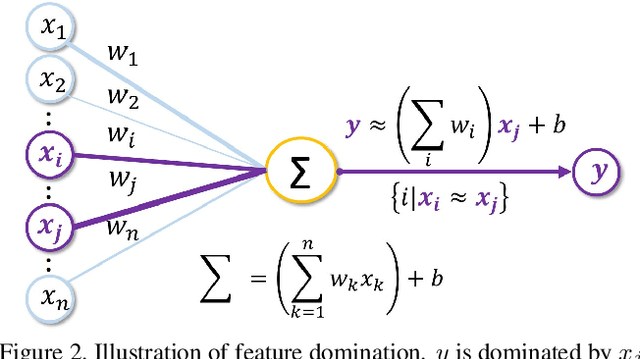
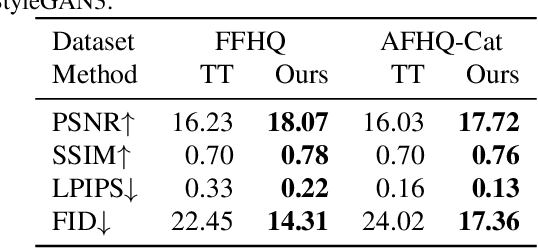
Despite the success of StyleGAN in image synthesis, the images it synthesizes are not always perfect and the well-known truncation trick has become a standard post-processing technique for StyleGAN to synthesize high-quality images. Although effective, it has long been noted that the truncation trick tends to reduce the diversity of synthesized images and unnecessarily sacrifices many distinct image features. To address this issue, in this paper, we first delve into the StyleGAN image synthesis mechanism and discover an important phenomenon, namely Feature Proliferation, which demonstrates how specific features reproduce with forward propagation. Then, we show how the occurrence of Feature Proliferation results in StyleGAN image artifacts. As an analogy, we refer to it as the" cancer" in StyleGAN from its proliferating and malignant nature. Finally, we propose a novel feature rescaling method that identifies and modulates risky features to mitigate feature proliferation. Thanks to our discovery of Feature Proliferation, the proposed feature rescaling method is less destructive and retains more useful image features than the truncation trick, as it is more fine-grained and works in a lower-level feature space rather than a high-level latent space. Experimental results justify the validity of our claims and the effectiveness of the proposed feature rescaling method. Our code is available at https://github. com/songc42/Feature-proliferation.
Improved Distribution Matching for Dataset Condensation
Jul 19, 2023


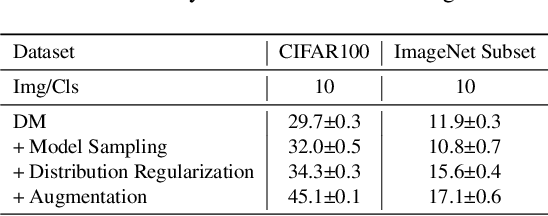
Dataset Condensation aims to condense a large dataset into a smaller one while maintaining its ability to train a well-performing model, thus reducing the storage cost and training effort in deep learning applications. However, conventional dataset condensation methods are optimization-oriented and condense the dataset by performing gradient or parameter matching during model optimization, which is computationally intensive even on small datasets and models. In this paper, we propose a novel dataset condensation method based on distribution matching, which is more efficient and promising. Specifically, we identify two important shortcomings of naive distribution matching (i.e., imbalanced feature numbers and unvalidated embeddings for distance computation) and address them with three novel techniques (i.e., partitioning and expansion augmentation, efficient and enriched model sampling, and class-aware distribution regularization). Our simple yet effective method outperforms most previous optimization-oriented methods with much fewer computational resources, thereby scaling data condensation to larger datasets and models. Extensive experiments demonstrate the effectiveness of our method. Codes are available at https://github.com/uitrbn/IDM
Universal Semi-supervised Model Adaptation via Collaborative Consistency Training
Jul 07, 2023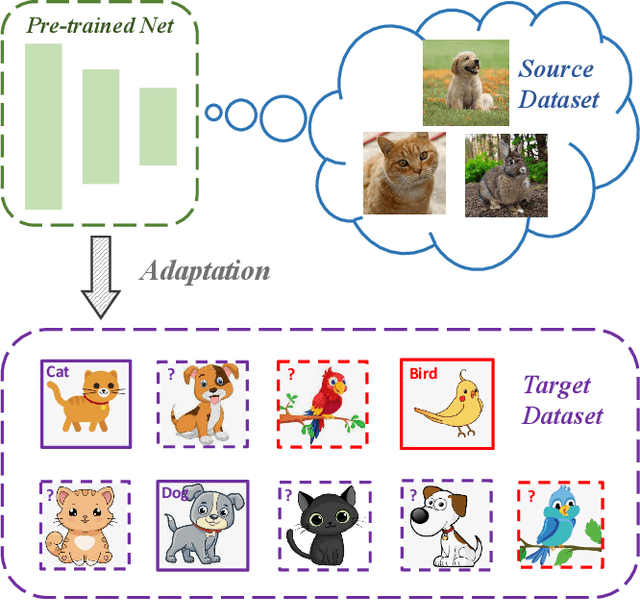
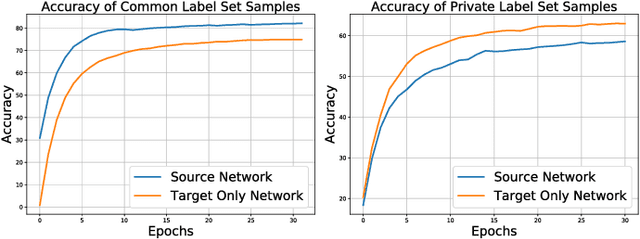


In this paper, we introduce a realistic and challenging domain adaptation problem called Universal Semi-supervised Model Adaptation (USMA), which i) requires only a pre-trained source model, ii) allows the source and target domain to have different label sets, i.e., they share a common label set and hold their own private label set, and iii) requires only a few labeled samples in each class of the target domain. To address USMA, we propose a collaborative consistency training framework that regularizes the prediction consistency between two models, i.e., a pre-trained source model and its variant pre-trained with target data only, and combines their complementary strengths to learn a more powerful model. The rationale of our framework stems from the observation that the source model performs better on common categories than the target-only model, while on target-private categories, the target-only model performs better. We also propose a two-perspective, i.e., sample-wise and class-wise, consistency regularization to improve the training. Experimental results demonstrate the effectiveness of our method on several benchmark datasets.
Exploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023



In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
Parametric Implicit Face Representation for Audio-Driven Facial Reenactment
Jun 13, 2023



Audio-driven facial reenactment is a crucial technique that has a range of applications in film-making, virtual avatars and video conferences. Existing works either employ explicit intermediate face representations (e.g., 2D facial landmarks or 3D face models) or implicit ones (e.g., Neural Radiance Fields), thus suffering from the trade-offs between interpretability and expressive power, hence between controllability and quality of the results. In this work, we break these trade-offs with our novel parametric implicit face representation and propose a novel audio-driven facial reenactment framework that is both controllable and can generate high-quality talking heads. Specifically, our parametric implicit representation parameterizes the implicit representation with interpretable parameters of 3D face models, thereby taking the best of both explicit and implicit methods. In addition, we propose several new techniques to improve the three components of our framework, including i) incorporating contextual information into the audio-to-expression parameters encoding; ii) using conditional image synthesis to parameterize the implicit representation and implementing it with an innovative tri-plane structure for efficient learning; iii) formulating facial reenactment as a conditional image inpainting problem and proposing a novel data augmentation technique to improve model generalizability. Extensive experiments demonstrate that our method can generate more realistic results than previous methods with greater fidelity to the identities and talking styles of speakers.
Motion-R3: Fast and Accurate Motion Annotation via Representation-based Representativeness Ranking
Apr 04, 2023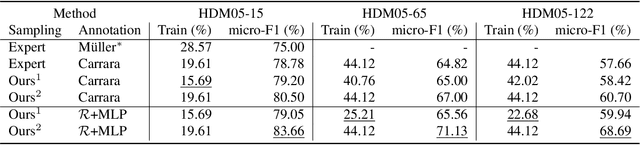

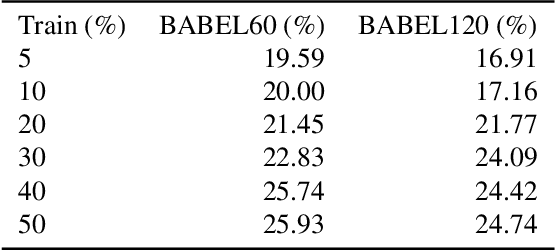
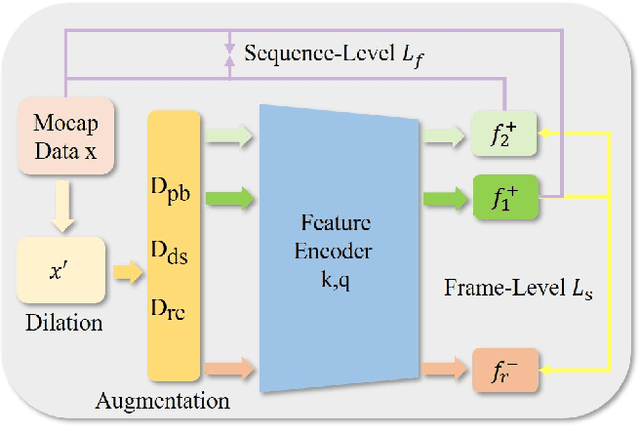
In this paper, we follow a data-centric philosophy and propose a novel motion annotation method based on the inherent representativeness of motion data in a given dataset. Specifically, we propose a Representation-based Representativeness Ranking R3 method that ranks all motion data in a given dataset according to their representativeness in a learned motion representation space. We further propose a novel dual-level motion constrastive learning method to learn the motion representation space in a more informative way. Thanks to its high efficiency, our method is particularly responsive to frequent requirements change and enables agile development of motion annotation models. Experimental results on the HDM05 dataset against state-of-the-art methods demonstrate the superiority of our method.