 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiting Zhang
Knowledge Graph Large Language Model (KG-LLM) for Link Prediction
Mar 19, 2024
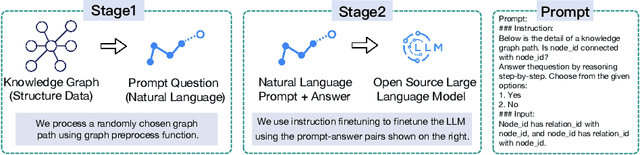
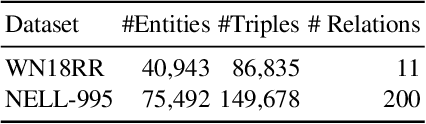
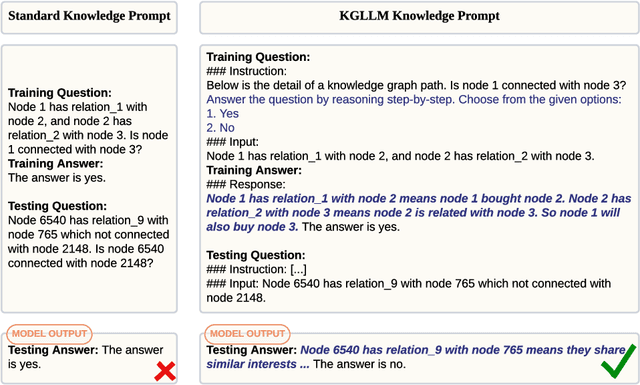
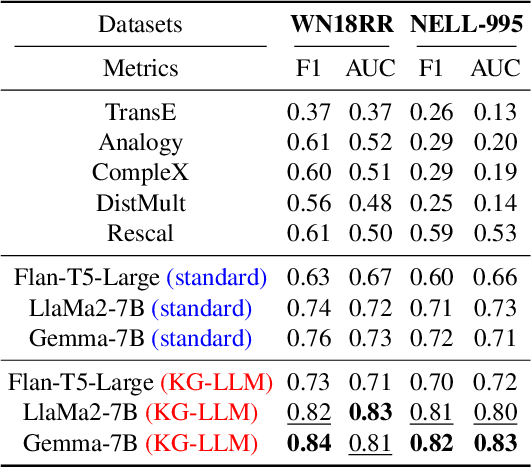
The task of predicting multiple links within knowledge graphs (KGs) stands as a challenge in the field of knowledge graph analysis, a challenge increasingly resolvable due to advancements in natural language processing (NLP) and KG embedding techniques. This paper introduces a novel methodology, the Knowledge Graph Large Language Model Framework (KG-LLM), which leverages pivotal NLP paradigms, including chain-of-thought (CoT) prompting and in-context learning (ICL), to enhance multi-hop link prediction in KGs. By converting the KG to a CoT prompt, our framework is designed to discern and learn the latent representations of entities and their interrelations. To show the efficacy of the KG-LLM Framework, we fine-tune three leading Large Language Models (LLMs) within this framework, employing both non-ICL and ICL tasks for a comprehensive evaluation. Further, we explore the framework's potential to provide LLMs with zero-shot capabilities for handling previously unseen prompts. Our experimental findings discover that integrating ICL and CoT not only augments the performance of our approach but also significantly boosts the models' generalization capacity, thereby ensuring more precise predictions in unfamiliar scenarios.
Bayesian Federated Learning Via Expectation Maximization and Turbo Deep Approximate Message Passing
Feb 12, 2024Federated learning (FL) is a machine learning paradigm where the clients possess decentralized training data and the central server handles aggregation and scheduling. Typically, FL algorithms involve clients training their local models using stochastic gradient descent (SGD), which carries drawbacks such as slow convergence and being prone to getting stuck in suboptimal solutions. In this work, we propose a message passing based Bayesian federated learning (BFL) framework to avoid these drawbacks.Specifically, we formulate the problem of deep neural network (DNN) learning and compression and as a sparse Bayesian inference problem, in which group sparse prior is employed to achieve structured model compression. Then, we propose an efficient BFL algorithm called EMTDAMP, where expectation maximization (EM) and turbo deep approximate message passing (TDAMP) are combined to achieve distributed learning and compression. The central server aggregates local posterior distributions to update global posterior distributions and update hyperparameters based on EM to accelerate convergence. The clients perform TDAMP to achieve efficient approximate message passing over DNN with joint prior distribution. We detail the application of EMTDAMP to Boston housing price prediction and handwriting recognition, and present extensive numerical results to demonstrate the advantages of EMTDAMP.