 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYixiao Li
DBPF: A Framework for Efficient and Robust Dynamic Bin-Picking
Mar 25, 2024




Efficiency and reliability are critical in robotic bin-picking as they directly impact the productivity of automated industrial processes. However, traditional approaches, demanding static objects and fixed collisions, lead to deployment limitations, operational inefficiencies, and process unreliability. This paper introduces a Dynamic Bin-Picking Framework (DBPF) that challenges traditional static assumptions. The DBPF endows the robot with the reactivity to pick multiple moving arbitrary objects while avoiding dynamic obstacles, such as the moving bin. Combined with scene-level pose generation, the proposed pose selection metric leverages the Tendency-Aware Manipulability Network optimizing suction pose determination. Heuristic task-specific designs like velocity-matching, dynamic obstacle avoidance, and the resight policy, enhance the picking success rate and reliability. Empirical experiments demonstrate the importance of these components. Our method achieves an average 84% success rate, surpassing the 60% of the most comparable baseline, crucially, with zero collisions. Further evaluations under diverse dynamic scenarios showcase DBPF's robust performance in dynamic bin-picking. Results suggest that our framework offers a promising solution for efficient and reliable robotic bin-picking under dynamics.
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
Oct 23, 2023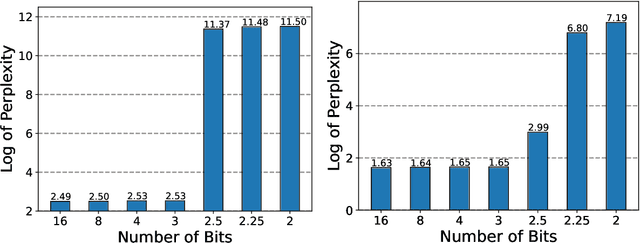
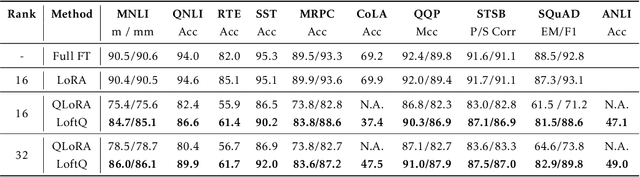
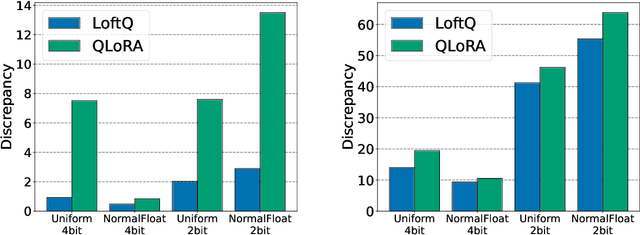
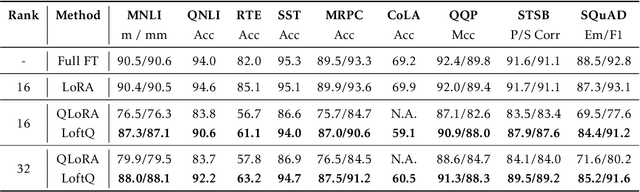
Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work we focus on the scenario where quantization and LoRA fine-tuning are applied together on a pre-trained model. In such cases it is common to observe a consistent gap in the performance on downstream tasks between full fine-tuning and quantization plus LoRA fine-tuning approach. In response, we propose LoftQ (LoRA-Fine-Tuning-aware Quantization), a novel quantization framework that simultaneously quantizes an LLM and finds a proper low-rank initialization for LoRA fine-tuning. Such an initialization alleviates the discrepancy between the quantized and full-precision model and significantly improves the generalization in downstream tasks. We evaluate our method on natural language understanding, question answering, summarization, and natural language generation tasks. Experiments show that our method is highly effective and outperforms existing quantization methods, especially in the challenging 2-bit and 2/4-bit mixed precision regimes. We will release our code.
Deep Reinforcement Learning from Hierarchical Weak Preference Feedback
Sep 06, 2023



Reward design is a fundamental, yet challenging aspect of practical reinforcement learning (RL). For simple tasks, researchers typically handcraft the reward function, e.g., using a linear combination of several reward factors. However, such reward engineering is subject to approximation bias, incurs large tuning cost, and often cannot provide the granularity required for complex tasks. To avoid these difficulties, researchers have turned to reinforcement learning from human feedback (RLHF), which learns a reward function from human preferences between pairs of trajectory sequences. By leveraging preference-based reward modeling, RLHF learns complex rewards that are well aligned with human preferences, allowing RL to tackle increasingly difficult problems. Unfortunately, the applicability of RLHF is limited due to the high cost and difficulty of obtaining human preference data. In light of this cost, we investigate learning reward functions for complex tasks with less human effort; simply by ranking the importance of the reward factors. More specifically, we propose a new RL framework -- HERON, which compares trajectories using a hierarchical decision tree induced by the given ranking. These comparisons are used to train a preference-based reward model, which is then used for policy learning. We find that our framework can not only train high performing agents on a variety of difficult tasks, but also provide additional benefits such as improved sample efficiency and robustness. Our code is available at https://github.com/abukharin3/HERON.
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation
Jun 26, 2023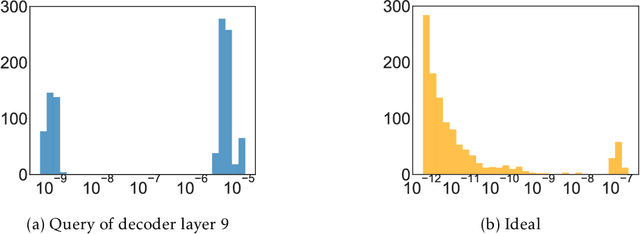

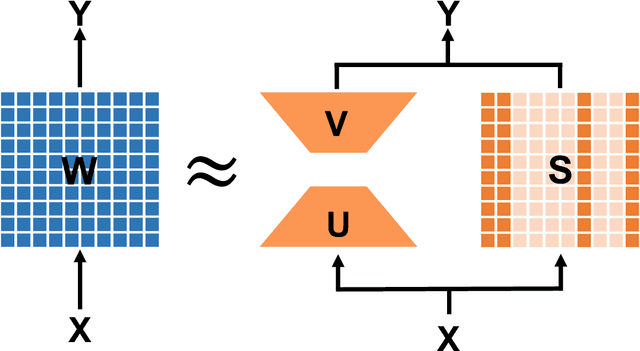
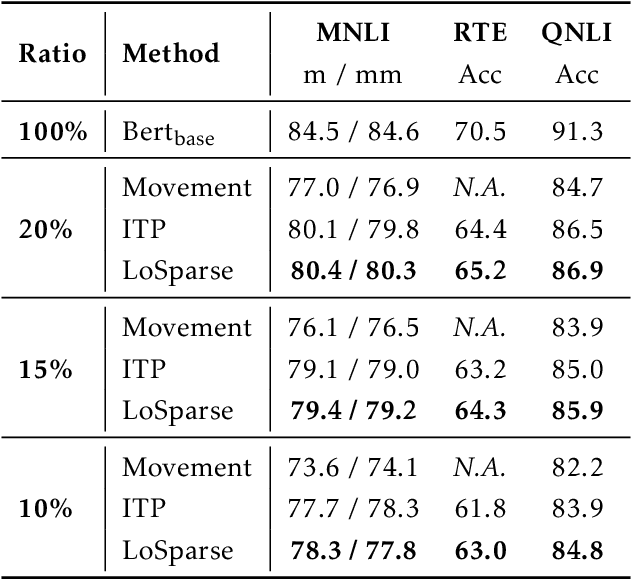
Transformer models have achieved remarkable results in various natural language tasks, but they are often prohibitively large, requiring massive memories and computational resources. To reduce the size and complexity of these models, we propose LoSparse (Low-Rank and Sparse approximation), a novel model compression technique that approximates a weight matrix by the sum of a low-rank matrix and a sparse matrix. Our method combines the advantages of both low-rank approximations and pruning, while avoiding their limitations. Low-rank approximation compresses the coherent and expressive parts in neurons, while pruning removes the incoherent and non-expressive parts in neurons. Pruning enhances the diversity of low-rank approximations, and low-rank approximation prevents pruning from losing too many expressive neurons. We evaluate our method on natural language understanding, question answering, and natural language generation tasks. We show that it significantly outperforms existing compression methods.
A Review of Changepoint Detection Models
Aug 20, 2019The objective of the change-point detection is to discover the abrupt property changes lying behind the time-series data. In this paper, we firstly summarize the definition and in-depth implication of the changepoint detection. The next stage is to elaborate traditional and some alternative model-based changepoint detection algorithms. Finally, we try to go a bit further in the theory and look into future research directions.