 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYizhao Zhang
Post-Training Attribute Unlearning in Recommender Systems
Mar 11, 2024


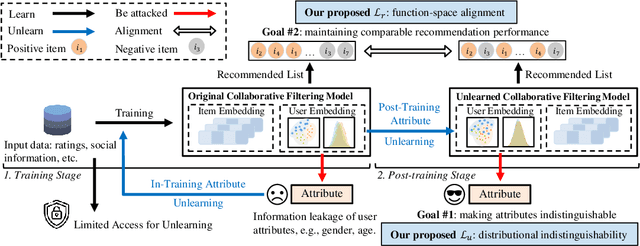
With the growing privacy concerns in recommender systems, recommendation unlearning is getting increasing attention. Existing studies predominantly use training data, i.e., model inputs, as unlearning target. However, attackers can extract private information from the model even if it has not been explicitly encountered during training. We name this unseen information as \textit{attribute} and treat it as unlearning target. To protect the sensitive attribute of users, Attribute Unlearning (AU) aims to make target attributes indistinguishable. In this paper, we focus on a strict but practical setting of AU, namely Post-Training Attribute Unlearning (PoT-AU), where unlearning can only be performed after the training of the recommendation model is completed. To address the PoT-AU problem in recommender systems, we propose a two-component loss function. The first component is distinguishability loss, where we design a distribution-based measurement to make attribute labels indistinguishable from attackers. We further extend this measurement to handle multi-class attribute cases with efficient computational overhead. The second component is regularization loss, where we explore a function-space measurement that effectively maintains recommendation performance compared to parameter-space regularization. We use stochastic gradient descent algorithm to optimize our proposed loss. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposed methods.
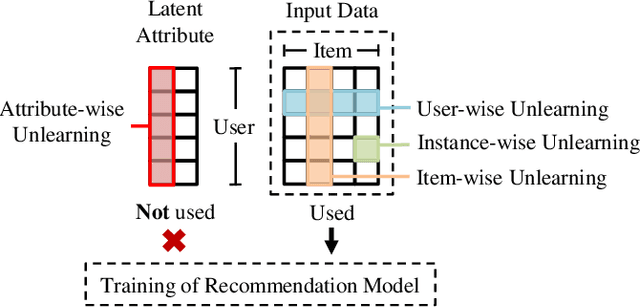
Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems
Oct 06, 2023With the growing privacy concerns in recommender systems, recommendation unlearning, i.e., forgetting the impact of specific learned targets, is getting increasing attention. Existing studies predominantly use training data, i.e., model inputs, as the unlearning target. However, we find that attackers can extract private information, i.e., gender, race, and age, from a trained model even if it has not been explicitly encountered during training. We name this unseen information as attribute and treat it as the unlearning target. To protect the sensitive attribute of users, Attribute Unlearning (AU) aims to degrade attacking performance and make target attributes indistinguishable. In this paper, we focus on a strict but practical setting of AU, namely Post-Training Attribute Unlearning (PoT-AU), where unlearning can only be performed after the training of the recommendation model is completed. To address the PoT-AU problem in recommender systems, we design a two-component loss function that consists of i) distinguishability loss: making attribute labels indistinguishable from attackers, and ii) regularization loss: preventing drastic changes in the model that result in a negative impact on recommendation performance. Specifically, we investigate two types of distinguishability measurements, i.e., user-to-user and distribution-to-distribution. We use the stochastic gradient descent algorithm to optimize our proposed loss. Extensive experiments on three real-world datasets demonstrate the effectiveness of our proposed methods.
Selective and Collaborative Influence Function for Efficient Recommendation Unlearning
Apr 20, 2023



Recent regulations on the Right to be Forgotten have greatly influenced the way of running a recommender system, because users now have the right to withdraw their private data. Besides simply deleting the target data in the database, unlearning the associated data lineage e.g., the learned personal features and preferences in the model, is also necessary for data withdrawal. Existing unlearning methods are mainly devised for generalized machine learning models in classification tasks. In this paper, we first identify two main disadvantages of directly applying existing unlearning methods in the context of recommendation, i.e., (i) unsatisfactory efficiency for large-scale recommendation models and (ii) destruction of collaboration across users and items. To tackle the above issues, we propose an extra-efficient recommendation unlearning method based on Selective and Collaborative Influence Function (SCIF). Our proposed method can (i) avoid any kind of retraining which is computationally prohibitive for large-scale systems, (ii) further enhance efficiency by selectively updating user embedding and (iii) preserve the collaboration across the remaining users and items. Furthermore, in order to evaluate the unlearning completeness, we define a Membership Inference Oracle (MIO), which can justify whether the unlearned data points were in the training set of the model, i.e., whether a data point was completely unlearned. Extensive experiments on two benchmark datasets demonstrate that our proposed method can not only greatly enhance unlearning efficiency, but also achieve adequate unlearning completeness. More importantly, our proposed method outperforms the state-of-the-art unlearning method regarding comprehensive recommendation metrics.