 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoung-Jun Lee
Large Language Models can Share Images, Too!
Oct 23, 2023
This paper explores the image-sharing capability of Large Language Models (LLMs), such as InstructGPT, ChatGPT, and GPT-4, in a zero-shot setting, without the help of visual foundation models. Inspired by the two-stage process of image-sharing in human dialogues, we propose a two-stage framework that allows LLMs to predict potential image-sharing turns and generate related image descriptions using our effective restriction-based prompt template. With extensive experiments, we unlock the \textit{image-sharing} capability of LLMs in zero-shot prompting, with GPT-4 achieving the best performance. Additionally, we uncover the emergent \textit{image-sharing} ability in zero-shot prompting, demonstrating the effectiveness of restriction-based prompts in both stages of our framework. Based on this framework, we augment the PhotoChat dataset with images generated by Stable Diffusion at predicted turns, namely PhotoChat++. To our knowledge, this is the first study to assess the image-sharing ability of LLMs in a zero-shot setting without visual foundation models. The source code and the dataset will be released after publication.
DialogCC: Large-Scale Multi-Modal Dialogue Dataset
Dec 08, 2022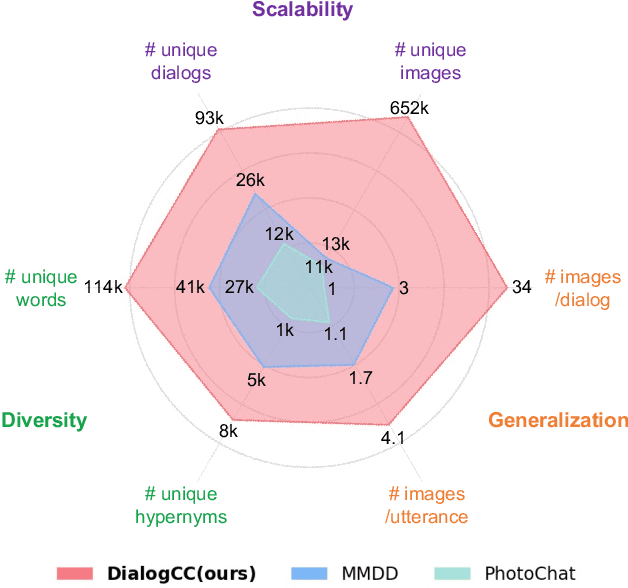
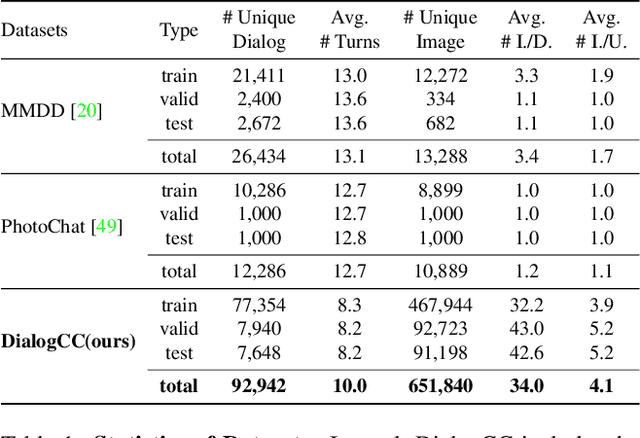
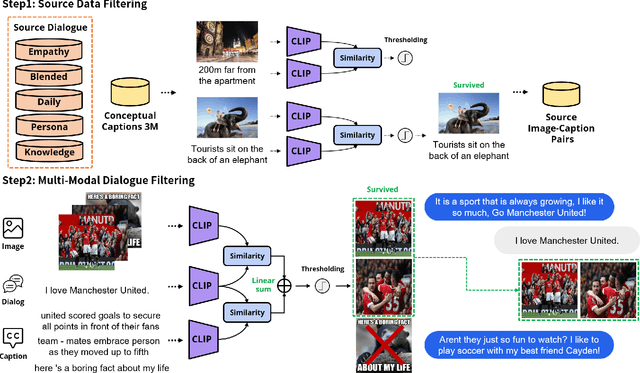
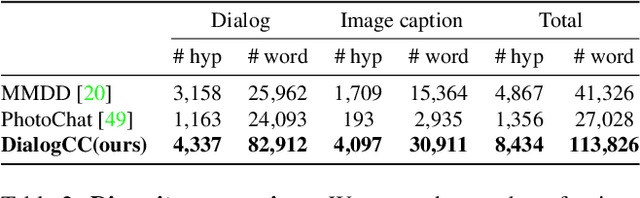
As sharing images in an instant message is a crucial factor, there has been active research on learning a image-text multi-modal dialogue model. However, training a well-generalized multi-modal dialogue model is challenging because existing multi-modal dialogue datasets contain a small number of data, limited topics, and a restricted variety of images per dialogue. In this paper, we present a multi-modal dialogue dataset creation pipeline that involves matching large-scale images to dialogues based on CLIP similarity. Using this automatic pipeline, we propose a large-scale multi-modal dialogue dataset, DialogCC, which covers diverse real-world topics and various images per dialogue. With extensive experiments, we demonstrate that training a multi-modal dialogue model with our dataset can improve generalization performance. Additionally, existing models trained with our dataset achieve state-of-the-art performance on image and text retrieval tasks. The source code and the dataset will be released after publication.
Empirical Study of Drone Sound Detection in Real-Life Environment with Deep Neural Networks
Jan 20, 2017



This work aims to investigate the use of deep neural network to detect commercial hobby drones in real-life environments by analyzing their sound data. The purpose of work is to contribute to a system for detecting drones used for malicious purposes, such as for terrorism. Specifically, we present a method capable of detecting the presence of commercial hobby drones as a binary classification problem based on sound event detection. We recorded the sound produced by a few popular commercial hobby drones, and then augmented this data with diverse environmental sound data to remedy the scarcity of drone sound data in diverse environments. We investigated the effectiveness of state-of-the-art event sound classification methods, i.e., a Gaussian Mixture Model (GMM), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN), for drone sound detection. Our empirical results, which were obtained with a testing dataset collected on an urban street, confirmed the effectiveness of these models for operating in a real environment. In summary, our RNN models showed the best detection performance with an F-Score of 0.8009 with 240 ms of input audio with a short processing time, indicating their applicability to real-time detection systems.