 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoungjoong Kwon
DELIFFAS: Deformable Light Fields for Fast Avatar Synthesis
Oct 17, 2023
Generating controllable and photorealistic digital human avatars is a long-standing and important problem in Vision and Graphics. Recent methods have shown great progress in terms of either photorealism or inference speed while the combination of the two desired properties still remains unsolved. To this end, we propose a novel method, called DELIFFAS, which parameterizes the appearance of the human as a surface light field that is attached to a controllable and deforming human mesh model. At the core, we represent the light field around the human with a deformable two-surface parameterization, which enables fast and accurate inference of the human appearance. This allows perceptual supervision on the full image compared to previous approaches that could only supervise individual pixels or small patches due to their slow runtime. Our carefully designed human representation and supervision strategy leads to state-of-the-art synthesis results and inference time. The video results and code are available at https://vcai.mpi-inf.mpg.de/projects/DELIFFAS.
Neural Image-based Avatars: Generalizable Radiance Fields for Human Avatar Modeling
Apr 10, 2023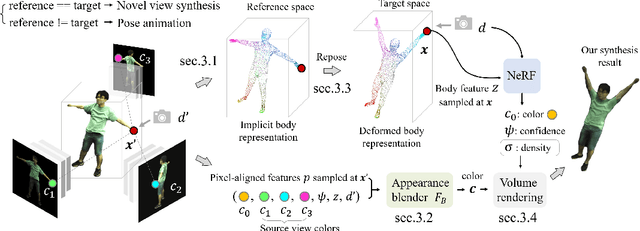
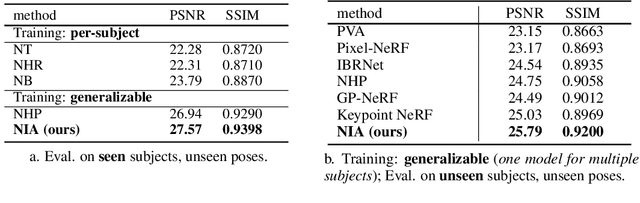


We present a method that enables synthesizing novel views and novel poses of arbitrary human performers from sparse multi-view images. A key ingredient of our method is a hybrid appearance blending module that combines the advantages of the implicit body NeRF representation and image-based rendering. Existing generalizable human NeRF methods that are conditioned on the body model have shown robustness against the geometric variation of arbitrary human performers. Yet they often exhibit blurry results when generalized onto unseen identities. Meanwhile, image-based rendering shows high-quality results when sufficient observations are available, whereas it suffers artifacts in sparse-view settings. We propose Neural Image-based Avatars (NIA) that exploits the best of those two methods: to maintain robustness under new articulations and self-occlusions while directly leveraging the available (sparse) source view colors to preserve appearance details of new subject identities. Our hybrid design outperforms recent methods on both in-domain identity generalization as well as challenging cross-dataset generalization settings. Also, in terms of the pose generalization, our method outperforms even the per-subject optimized animatable NeRF methods. The video results are available at https://youngjoongunc.github.io/nia
Neural Human Performer: Learning Generalizable Radiance Fields for Human Performance Rendering
Sep 15, 2021



In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.