 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Xiang
Mining Invariance from Nonlinear Multi-Environment Data: Binary Classification
Apr 23, 2024
Making predictions in an unseen environment given data from multiple training environments is a challenging task. We approach this problem from an invariance perspective, focusing on binary classification to shed light on general nonlinear data generation mechanisms. We identify a unique form of invariance that exists solely in a binary setting that allows us to train models invariant over environments. We provide sufficient conditions for such invariance and show it is robust even when environmental conditions vary greatly. Our formulation admits a causal interpretation, allowing us to compare it with various frameworks. Finally, we propose a heuristic prediction method and conduct experiments using real and synthetic datasets.
Training-Conditional Coverage Bounds for Uniformly Stable Learning Algorithms
Apr 21, 2024The training-conditional coverage performance of the conformal prediction is known to be empirically sound. Recently, there have been efforts to support this observation with theoretical guarantees. The training-conditional coverage bounds for jackknife+ and full-conformal prediction regions have been established via the notion of $(m,n)$-stability by Liang and Barber~[2023]. Although this notion is weaker than uniform stability, it is not clear how to evaluate it for practical models. In this paper, we study the training-conditional coverage bounds of full-conformal, jackknife+, and CV+ prediction regions from a uniform stability perspective which is known to hold for empirical risk minimization over reproducing kernel Hilbert spaces with convex regularization. We derive coverage bounds for finite-dimensional models by a concentration argument for the (estimated) predictor function, and compare the bounds with existing ones under ridge regression.
Deep Dependency Networks and Advanced Inference Schemes for Multi-Label Classification
Apr 17, 2024We present a unified framework called deep dependency networks (DDNs) that combines dependency networks and deep learning architectures for multi-label classification, with a particular emphasis on image and video data. The primary advantage of dependency networks is their ease of training, in contrast to other probabilistic graphical models like Markov networks. In particular, when combined with deep learning architectures, they provide an intuitive, easy-to-use loss function for multi-label classification. A drawback of DDNs compared to Markov networks is their lack of advanced inference schemes, necessitating the use of Gibbs sampling. To address this challenge, we propose novel inference schemes based on local search and integer linear programming for computing the most likely assignment to the labels given observations. We evaluate our novel methods on three video datasets (Charades, TACoS, Wetlab) and three image datasets (MS-COCO, PASCAL VOC, NUS-WIDE), comparing their performance with (a) basic neural architectures and (b) neural architectures combined with Markov networks equipped with advanced inference and learning techniques. Our results demonstrate the superiority of our new DDN methods over the two competing approaches.
Causal Discovery from Poisson Branching Structural Causal Model Using High-Order Cumulant with Path Analysis
Mar 25, 2024Count data naturally arise in many fields, such as finance, neuroscience, and epidemiology, and discovering causal structure among count data is a crucial task in various scientific and industrial scenarios. One of the most common characteristics of count data is the inherent branching structure described by a binomial thinning operator and an independent Poisson distribution that captures both branching and noise. For instance, in a population count scenario, mortality and immigration contribute to the count, where survival follows a Bernoulli distribution, and immigration follows a Poisson distribution. However, causal discovery from such data is challenging due to the non-identifiability issue: a single causal pair is Markov equivalent, i.e., $X\rightarrow Y$ and $Y\rightarrow X$ are distributed equivalent. Fortunately, in this work, we found that the causal order from $X$ to its child $Y$ is identifiable if $X$ is a root vertex and has at least two directed paths to $Y$, or the ancestor of $X$ with the most directed path to $X$ has a directed path to $Y$ without passing $X$. Specifically, we propose a Poisson Branching Structure Causal Model (PB-SCM) and perform a path analysis on PB-SCM using high-order cumulants. Theoretical results establish the connection between the path and cumulant and demonstrate that the path information can be obtained from the cumulant. With the path information, causal order is identifiable under some graphical conditions. A practical algorithm for learning causal structure under PB-SCM is proposed and the experiments demonstrate and verify the effectiveness of the proposed method.
MultiGripperGrasp: A Dataset for Robotic Grasping from Parallel Jaw Grippers to Dexterous Hands
Mar 14, 2024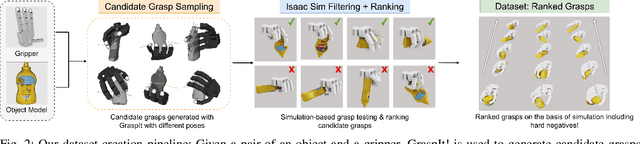

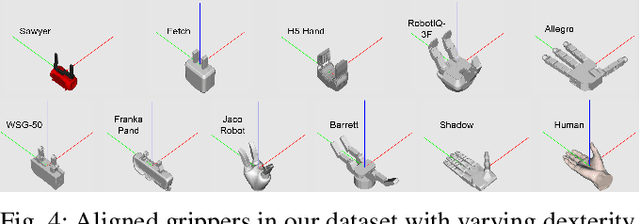

We introduce a large-scale dataset named MultiGripperGrasp for robotic grasping. Our dataset contains 30.4M grasps from 11 grippers for 345 objects. These grippers range from two-finger grippers to five-finger grippers, including a human hand. All grasps in the dataset are verified in Isaac Sim to classify them as successful and unsuccessful grasps. Additionally, the object fall-off time for each grasp is recorded as a grasp quality measurement. Furthermore, the grippers in our dataset are aligned according to the orientation and position of their palms, allowing us to transfer grasps from one gripper to another. The grasp transfer significantly increases the number of successful grasps for each gripper in the dataset. Our dataset is useful to study generalized grasp planning and grasp transfer across different grippers.
Grasping Trajectory Optimization with Point Clouds
Mar 08, 2024

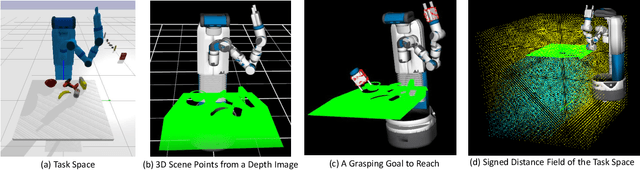
We introduce a new trajectory optimization method for robotic grasping based on a point-cloud representation of robots and task spaces. In our method, robots are represented by 3D points on their link surfaces. The task space of a robot is represented by a point cloud that can be obtained from depth sensors. Using the point-cloud representation, goal reaching in grasping can be formulated as point matching, while collision avoidance can be efficiently achieved by querying the signed distance values of the robot points in the signed distance field of the scene points. Consequently, a constrained non-linear optimization problem is formulated to solve the joint motion and grasp planning problem. The advantage of our method is that the point-cloud representation is general to be used with any robot in any environment. We demonstrate the effectiveness of our method by conducting experiments on a tabletop scene and a shelf scene for grasping with a Fetch mobile manipulator and a Franka Panda arm.
RISeg: Robot Interactive Object Segmentation via Body Frame-Invariant Features
Mar 04, 2024
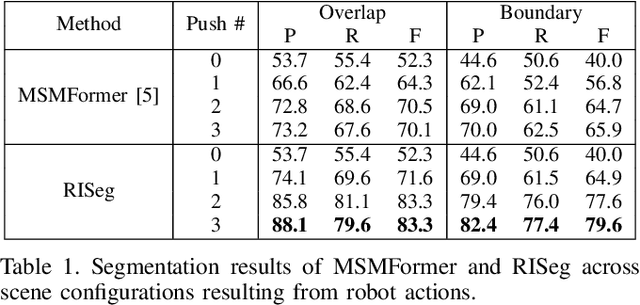
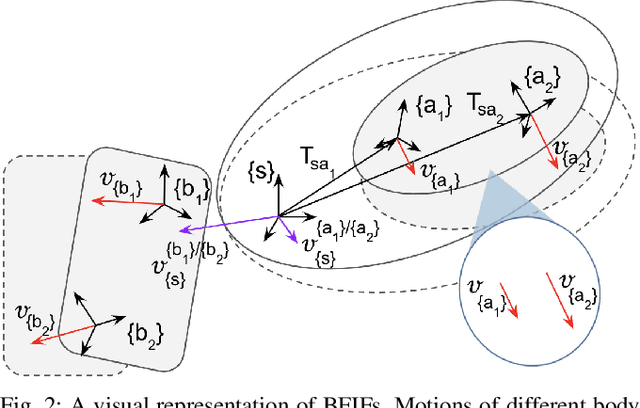
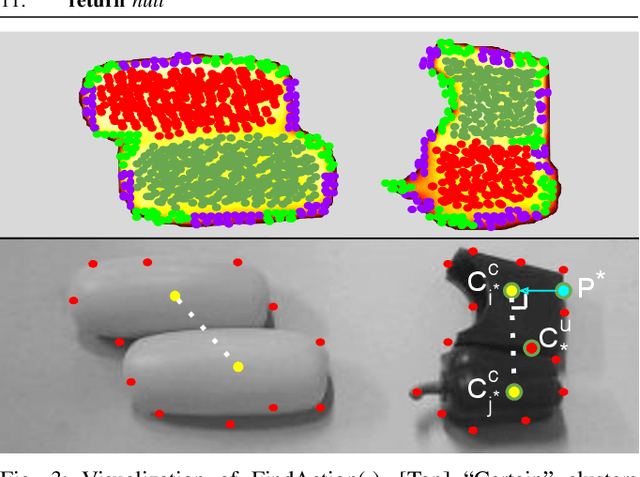
In order to successfully perform manipulation tasks in new environments, such as grasping, robots must be proficient in segmenting unseen objects from the background and/or other objects. Previous works perform unseen object instance segmentation (UOIS) by training deep neural networks on large-scale data to learn RGB/RGB-D feature embeddings, where cluttered environments often result in inaccurate segmentations. We build upon these methods and introduce a novel approach to correct inaccurate segmentation, such as under-segmentation, of static image-based UOIS masks by using robot interaction and a designed body frame-invariant feature. We demonstrate that the relative linear and rotational velocities of frames randomly attached to rigid bodies due to robot interactions can be used to identify objects and accumulate corrected object-level segmentation masks. By introducing motion to regions of segmentation uncertainty, we are able to drastically improve segmentation accuracy in an uncertainty-driven manner with minimal, non-disruptive interactions (ca. 2-3 per scene). We demonstrate the effectiveness of our proposed interactive perception pipeline in accurately segmenting cluttered scenes by achieving an average object segmentation accuracy rate of 80.7%, an increase of 28.2% when compared with other state-of-the-art UOIS methods.
Low-Rank Approximation of Structural Redundancy for Self-Supervised Learning
Feb 10, 2024We study the data-generating mechanism for reconstructive SSL to shed light on its effectiveness. With an infinite amount of labeled samples, we provide a sufficient and necessary condition for perfect linear approximation. The condition reveals a full-rank component that preserves the label classes of Y, along with a redundant component. Motivated by the condition, we propose to approximate the redundant component by a low-rank factorization and measure the approximation quality by introducing a new quantity $\epsilon_s$, parameterized by the rank of factorization s. We incorporate $\epsilon_s$ into the excess risk analysis under both linear regression and ridge regression settings, where the latter regularization approach is to handle scenarios when the dimension of the learned features is much larger than the number of labeled samples n for downstream tasks. We design three stylized experiments to compare SSL with supervised learning under different settings to support our theoretical findings.
CaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning
Segment Every Out-of-Distribution Object
Nov 27, 2023Semantic segmentation models, while effective for in-distribution categories, face challenges in real-world deployment due to encountering out-of-distribution (OoD) objects. Detecting these OoD objects is crucial for safety-critical applications. Existing methods rely on anomaly scores, but choosing a suitable threshold for generating masks presents difficulties and can lead to fragmentation and inaccuracy. This paper introduces a method to convert anomaly Score To segmentation Mask, called S2M, a simple and effective framework for OoD detection in semantic segmentation. Unlike assigning anomaly scores to pixels, S2M directly segments the entire OoD object. By transforming anomaly scores into prompts for a promptable segmentation model, S2M eliminates the need for threshold selection. Extensive experiments demonstrate that S2M outperforms the state-of-the-art by approximately 10\% in IoU and 30\% in mean F1 score, on average, across various benchmarks including Fishyscapes, Segment-Me-If-You-Can, and RoadAnomaly datasets.