 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan-Sen Ting
AstroLLaMA-Chat: Scaling AstroLLaMA with Conversational and Diverse Datasets
Jan 05, 2024
We explore the potential of enhancing LLM performance in astronomy-focused question-answering through targeted, continual pre-training. By employing a compact 7B-parameter LLaMA-2 model and focusing exclusively on a curated set of astronomy corpora -- comprising abstracts, introductions, and conclusions -- we achieve notable improvements in specialized topic comprehension. While general LLMs like GPT-4 excel in broader question-answering scenarios due to superior reasoning capabilities, our findings suggest that continual pre-training with limited resources can still enhance model performance on specialized topics. Additionally, we present an extension of AstroLLaMA: the fine-tuning of the 7B LLaMA model on a domain-specific conversational dataset, culminating in the release of the chat-enabled AstroLLaMA for community use. Comprehensive quantitative benchmarking is currently in progress and will be detailed in an upcoming full paper. The model, AstroLLaMA-Chat, is now available at https://huggingface.co/universeTBD, providing the first open-source conversational AI tool tailored for the astronomy community.
Astroconformer: The Prospects of Analyzing Stellar Light Curves with Transformer-Based Deep Learning Models
Sep 28, 2023Light curves of stars encapsulate a wealth of information about stellar oscillations and granulation, thereby offering key insights into the internal structure and evolutionary state of stars. Conventional asteroseismic techniques have been largely confined to power spectral analysis, neglecting the valuable phase information contained within light curves. While recent machine learning applications in asteroseismology utilizing Convolutional Neural Networks (CNNs) have successfully inferred stellar attributes from light curves, they are often limited by the local feature extraction inherent in convolutional operations. To circumvent these constraints, we present $\textit{Astroconformer}$, a Transformer-based deep learning framework designed to capture long-range dependencies in stellar light curves. Our empirical analysis, which focuses on estimating surface gravity ($\log g$), is grounded in a carefully curated dataset derived from $\textit{Kepler}$ light curves. These light curves feature asteroseismic $\log g$ values spanning from 0.2 to 4.4. Our results underscore that, in the regime where the training data is abundant, $\textit{Astroconformer}$ attains a root-mean-square-error (RMSE) of 0.017 dex around $\log g \approx 3 $. Even in regions where training data are sparse, the RMSE can reach 0.1 dex. It outperforms not only the K-nearest neighbor-based model ($\textit{The SWAN}$) but also state-of-the-art CNNs. Ablation studies confirm that the efficacy of the models in this particular task is strongly influenced by the size of their receptive fields, with larger receptive fields correlating with enhanced performance. Moreover, we find that the attention mechanisms within $\textit{Astroconformer}$ are well-aligned with the inherent characteristics of stellar oscillations and granulation present in the light curves.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023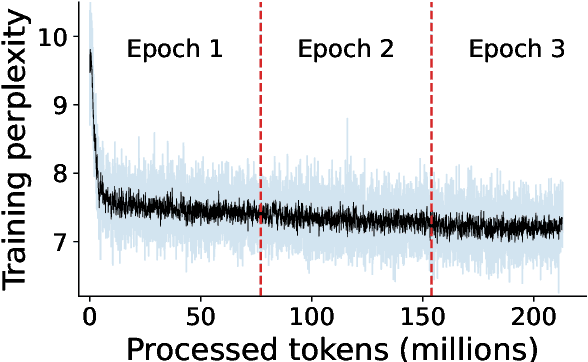

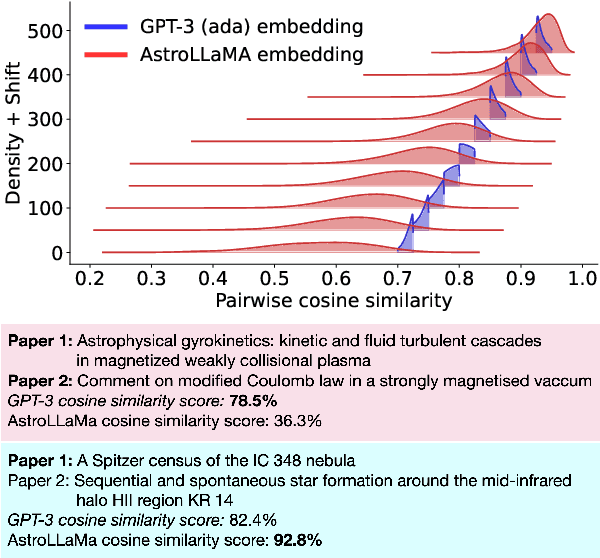
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Adversarial Fine-Tuning of Language Models: An Iterative Optimisation Approach for the Generation and Detection of Problematic Content
Aug 26, 2023In this paper, we tackle the emerging challenge of unintended harmful content generation in Large Language Models (LLMs) with a novel dual-stage optimisation technique using adversarial fine-tuning. Our two-pronged approach employs an adversarial model, fine-tuned to generate potentially harmful prompts, and a judge model, iteratively optimised to discern these prompts. In this adversarial cycle, the two models seek to outperform each other in the prompting phase, generating a dataset of rich examples which are then used for fine-tuning. This iterative application of prompting and fine-tuning allows continuous refinement and improved performance. The performance of our approach is evaluated through classification accuracy on a dataset consisting of problematic prompts not detected by GPT-4, as well as a selection of contentious but unproblematic prompts. We show considerable increase in classification accuracy of the judge model on this challenging dataset as it undergoes the optimisation process. Furthermore, we show that a rudimentary model \texttt{ada} can achieve 13\% higher accuracy on the hold-out test set than GPT-4 after only a few rounds of this process, and that this fine-tuning improves performance in parallel tasks such as toxic comment identification.
Steering Language Generation: Harnessing Contrastive Expert Guidance and Negative Prompting for Coherent and Diverse Synthetic Data Generation
Aug 17, 2023



Large Language Models (LLMs) hold immense potential to generate synthetic data of high quality and utility, which has numerous applications from downstream model training to practical data utilisation. However, contemporary models, despite their impressive capacities, consistently struggle to produce both coherent and diverse data. To address the coherency issue, we introduce contrastive expert guidance, where the difference between the logit distributions of fine-tuned and base language models is emphasised to ensure domain adherence. In order to ensure diversity, we utilise existing real and synthetic examples as negative prompts to the model. We deem this dual-pronged approach to logit reshaping as STEER: Semantic Text Enhancement via Embedding Repositioning. STEER operates at inference-time and systematically guides the LLMs to strike a balance between adherence to the data distribution (ensuring semantic fidelity) and deviation from prior synthetic examples or existing real datasets (ensuring diversity and authenticity). This delicate balancing act is achieved by dynamically moving towards or away from chosen representations in the latent space. STEER demonstrates improved performance over previous synthetic data generation techniques, exhibiting better balance between data diversity and coherency across three distinct tasks: hypothesis generation, toxic and non-toxic comment generation, and commonsense reasoning task generation. We demonstrate how STEER allows for fine-tuned control over the diversity-coherency trade-off via its hyperparameters, highlighting its versatility.
Harnessing the Power of Adversarial Prompting and Large Language Models for Robust Hypothesis Generation in Astronomy
Jun 20, 2023


This study investigates the application of Large Language Models (LLMs), specifically GPT-4, within Astronomy. We employ in-context prompting, supplying the model with up to 1000 papers from the NASA Astrophysics Data System, to explore the extent to which performance can be improved by immersing the model in domain-specific literature. Our findings point towards a substantial boost in hypothesis generation when using in-context prompting, a benefit that is further accentuated by adversarial prompting. We illustrate how adversarial prompting empowers GPT-4 to extract essential details from a vast knowledge base to produce meaningful hypotheses, signaling an innovative step towards employing LLMs for scientific research in Astronomy.
Galactic ChitChat: Using Large Language Models to Converse with Astronomy Literature
Apr 12, 2023
We demonstrate the potential of the state-of-the-art OpenAI GPT-4 large language model to engage in meaningful interactions with Astronomy papers using in-context prompting. To optimize for efficiency, we employ a distillation technique that effectively reduces the size of the original input paper by 50\%, while maintaining the paragraph structure and overall semantic integrity. We then explore the model's responses using a multi-document context (ten distilled documents). Our findings indicate that GPT-4 excels in the multi-document domain, providing detailed answers contextualized within the framework of related research findings. Our results showcase the potential of large language models for the astronomical community, offering a promising avenue for further exploration, particularly the possibility of utilizing the models for hypothesis generation.
Astroconformer: Inferring Surface Gravity of Stars from Stellar Light Curves with Transformer
Jul 06, 2022



We introduce Astroconformer, a Transformer-based model to analyze stellar light curves from the Kepler mission. We demonstrate that Astrconformer can robustly infer the stellar surface gravity as a supervised task. Importantly, as Transformer captures long-range information in the time series, it outperforms the state-of-the-art data-driven method in the field, and the critical role of self-attention is proved through ablation experiments. Furthermore, the attention map from Astroconformer exemplifies the long-range correlation information learned by the model, leading to a more interpretable deep learning approach for asteroseismology. Besides data from Kepler, we also show that the method can generalize to sparse cadence light curves from the Rubin Observatory, paving the way for the new era of asteroseismology, harnessing information from long-cadence ground-based observations.
Uncertainty-Aware Learning for Improvements in Image Quality of the Canada-France-Hawaii Telescope
Jun 30, 2021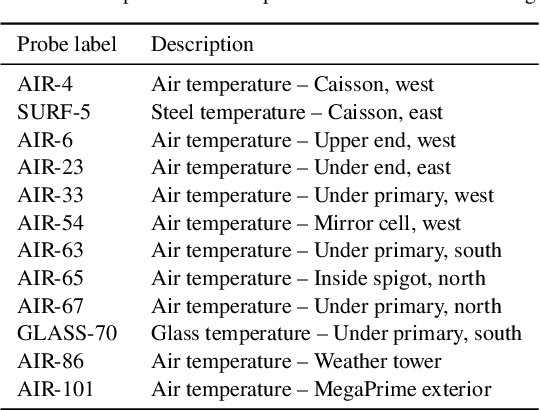
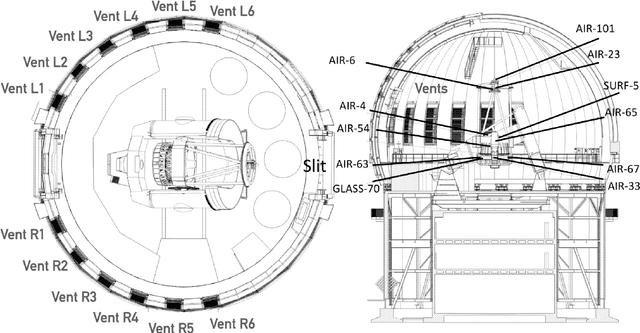
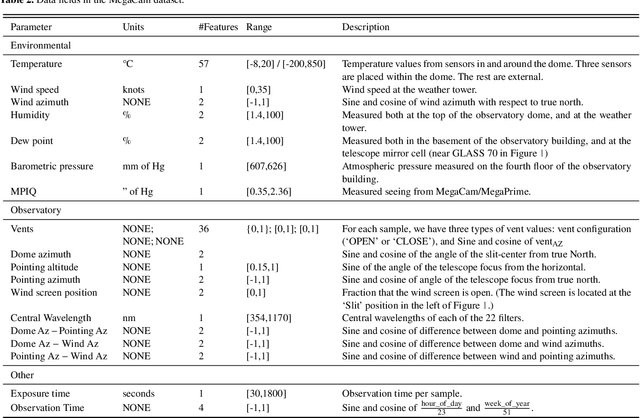
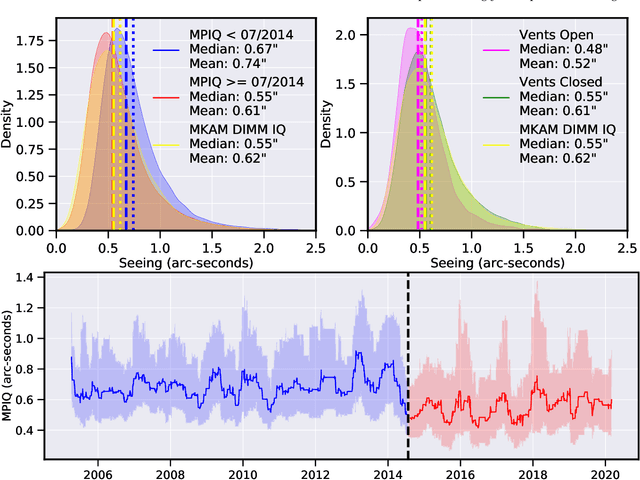
We leverage state-of-the-art machine learning methods and a decade's worth of archival data from the Canada-France-Hawaii Telescope (CFHT) to predict observatory image quality (IQ) from environmental conditions and observatory operating parameters. Specifically, we develop accurate and interpretable models of the complex dependence between data features and observed IQ for CFHT's wide field camera, MegaCam. Our contributions are several-fold. First, we collect, collate and reprocess several disparate data sets gathered by CFHT scientists. Second, we predict probability distribution functions (PDFs) of IQ, and achieve a mean absolute error of $\sim0.07''$ for the predicted medians. Third, we explore data-driven actuation of the 12 dome ``vents'', installed in 2013-14 to accelerate the flushing of hot air from the dome. We leverage epistemic and aleatoric uncertainties in conjunction with probabilistic generative modeling to identify candidate vent adjustments that are in-distribution (ID) and, for the optimal configuration for each ID sample, we predict the reduction in required observing time to achieve a fixed SNR. On average, the reduction is $\sim15\%$. Finally, we rank sensor data features by Shapley values to identify the most predictive variables for each observation. Our long-term goal is to construct reliable and real-time models that can forecast optimal observatory operating parameters for optimization of IQ. Such forecasts can then be fed into scheduling protocols and predictive maintenance routines. We anticipate that such approaches will become standard in automating observatory operations and maintenance by the time CFHT's successor, the Maunakea Spectroscopic Explorer (MSE), is installed in the next decade.
Interpreting Stellar Spectra with Unsupervised Domain Adaptation
Jul 06, 2020



We discuss how to achieve mapping from large sets of imperfect simulations and observational data with unsupervised domain adaptation. Under the hypothesis that simulated and observed data distributions share a common underlying representation, we show how it is possible to transfer between simulated and observed domains. Driven by an application to interpret stellar spectroscopic sky surveys, we construct the domain transfer pipeline from two adversarial autoencoders on each domains with a disentangling latent space, and a cycle-consistency constraint. We then construct a differentiable pipeline from physical stellar parameters to realistic observed spectra, aided by a supplementary generative surrogate physics emulator network. We further exemplify the potential of the method on the reconstructed spectra quality and to discover new spectral features associated to elemental abundances.