 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYufeng Hao
The implementation of a Deep Recurrent Neural Network Language Model on a Xilinx FPGA
Nov 16, 2017
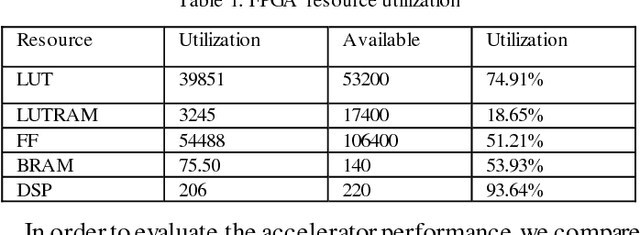
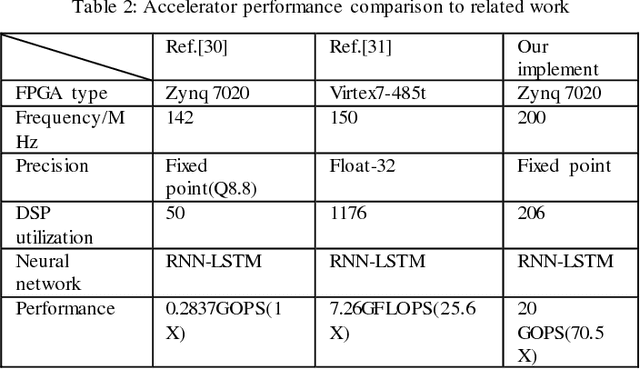
Recently, FPGA has been increasingly applied to problems such as speech recognition, machine learning, and cloud computation such as the Bing search engine used by Microsoft. This is due to FPGAs great parallel computation capacity as well as low power consumption compared to general purpose processors. However, these applications mainly focus on large scale FPGA clusters which have an extreme processing power for executing massive matrix or convolution operations but are unsuitable for portable or mobile applications. This paper describes research on single-FPGA platform to explore the applications of FPGAs in these fields. In this project, we design a Deep Recurrent Neural Network (DRNN) Language Model (LM) and implement a hardware accelerator with AXI Stream interface on a PYNQ board which is equipped with a XILINX ZYNQ SOC XC7Z020 1CLG400C. The PYNQ has not only abundant programmable logic resources but also a flexible embedded operation system, which makes it suitable to be applied in the natural language processing field. We design the DRNN language model with Python and Theano, train the model on a CPU platform, and deploy the model on a PYNQ board to validate the model with Jupyter notebook. Meanwhile, we design the hardware accelerator with Overlay, which is a kind of hardware library on PYNQ, and verify the acceleration effect on the PYNQ board. Finally, we have found that the DRNN language model can be deployed on the embedded system smoothly and the Overlay accelerator with AXI Stream interface performs at 20 GOPS processing throughput, which constitutes a 70.5X and 2.75X speed up compared to the work in Ref.30 and Ref.31 respectively.
A General Neural Network Hardware Architecture on FPGA
Nov 06, 2017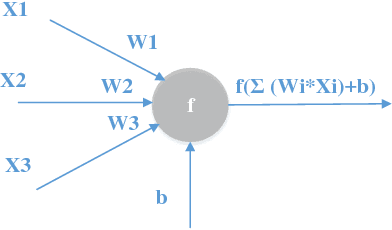
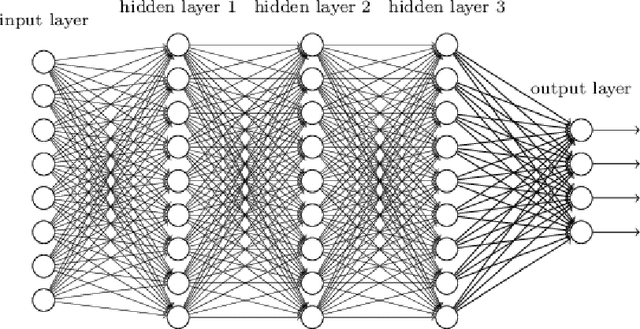
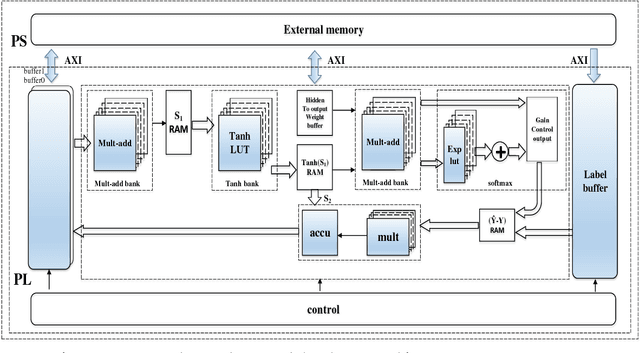
Field Programmable Gate Arrays (FPGAs) plays an increasingly important role in data sampling and processing industries due to its highly parallel architecture, low power consumption, and flexibility in custom algorithms. Especially, in the artificial intelligence field, for training and implement the neural networks and machine learning algorithms, high energy efficiency hardware implement and massively parallel computing capacity are heavily demanded. Therefore, many global companies have applied FPGAs into AI and Machine learning fields such as autonomous driving and Automatic Spoken Language Recognition (Baidu) [1] [2] and Bing search (Microsoft) [3]. Considering the FPGAs great potential in these fields, we tend to implement a general neural network hardware architecture on XILINX ZU9CG System On Chip (SOC) platform [4], which contains abundant hardware resource and powerful processing capacity. The general neural network architecture on the FPGA SOC platform can perform forward and backward algorithms in deep neural networks (DNN) with high performance and easily be adjusted according to the type and scale of the neural networks.