 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuji Cao
Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
Mar 30, 2024
With extensive pre-trained knowledge and high-level general capabilities, large language models (LLMs) emerge as a promising avenue to augment reinforcement learning (RL) in aspects such as multi-task learning, sample efficiency, and task planning. In this survey, we provide a comprehensive review of the existing literature in $\textit{LLM-enhanced RL}$ and summarize its characteristics compared to conventional RL methods, aiming to clarify the research scope and directions for future studies. Utilizing the classical agent-environment interaction paradigm, we propose a structured taxonomy to systematically categorize LLMs' functionalities in RL, including four roles: information processor, reward designer, decision-maker, and generator. Additionally, for each role, we summarize the methodologies, analyze the specific RL challenges that are mitigated, and provide insights into future directions. Lastly, potential applications, prospective opportunities and challenges of the $\textit{LLM-enhanced RL}$ are discussed.
Understanding Semantics from Speech Through Pre-training
Sep 24, 2019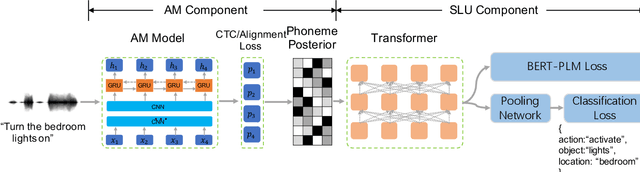
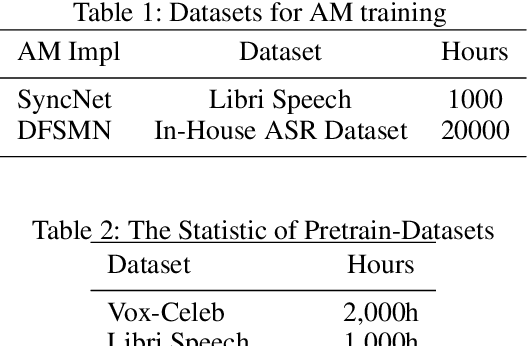
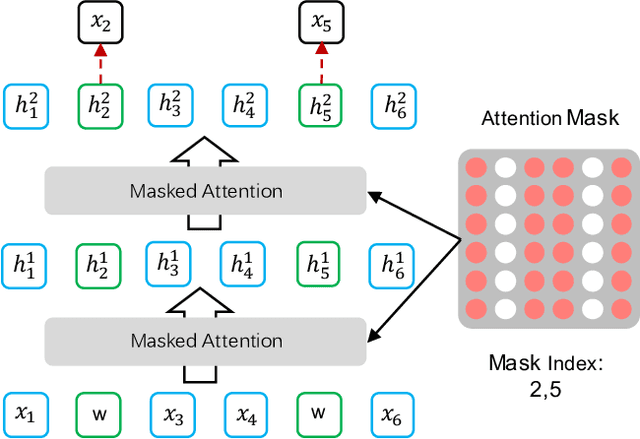
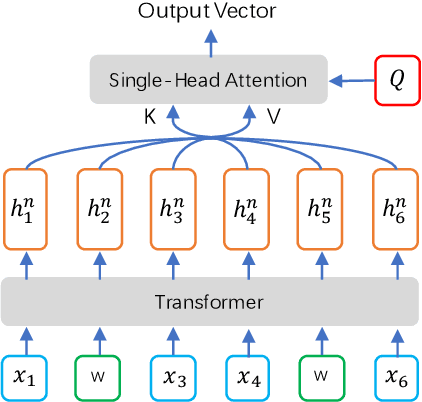
End-to-end Spoken Language Understanding (SLU) is proposed to infer the semantic meaning directly from audio features without intermediate text representation. Although the acoustic model component of an end-to-end SLU system can be pre-trained with Automatic Speech Recognition (ASR) targets, the SLU component can only learn semantic features from limited task-specific training data. In this paper, for the first time we propose to do large-scale unsupervised pre-training for the SLU component of an end-to-end SLU system, so that the SLU component may preserve semantic features from massive unlabeled audio data. As the output of the acoustic model component, i.e. phoneme posterior sequences, has much different characteristic from text sequences, we propose a novel pre-training model called BERT-PLM, which stands for Bidirectional Encoder Representations from Transformers through Permutation Language Modeling. BERT-PLM trains the SLU component on unlabeled data through a regression objective equivalent to the partial permutation language modeling objective, while leverages full bi-directional context information with BERT networks. The experiment results show that our approach out-perform the state-of-the-art end-to-end systems with over 12.5% error reduction.