 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYujuan Ding
FashionReGen: LLM-Empowered Fashion Report Generation
Mar 11, 2024


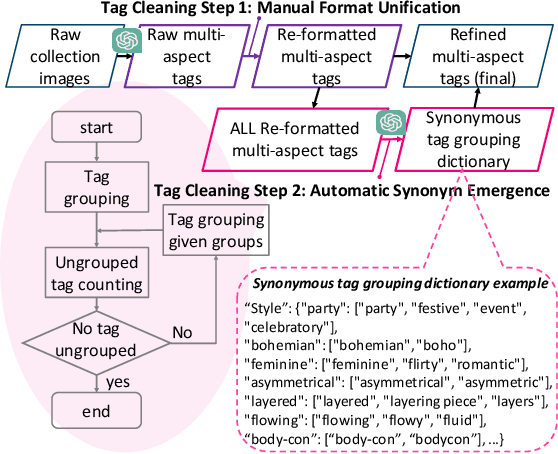
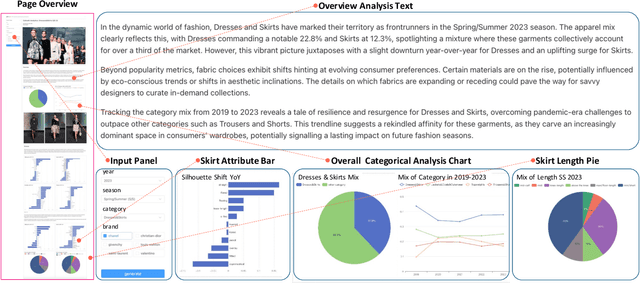
Fashion analysis refers to the process of examining and evaluating trends, styles, and elements within the fashion industry to understand and interpret its current state, generating fashion reports. It is traditionally performed by fashion professionals based on their expertise and experience, which requires high labour cost and may also produce biased results for relying heavily on a small group of people. In this paper, to tackle the Fashion Report Generation (FashionReGen) task, we propose an intelligent Fashion Analyzing and Reporting system based the advanced Large Language Models (LLMs), debbed as GPT-FAR. Specifically, it tries to deliver FashionReGen based on effective catwalk analysis, which is equipped with several key procedures, namely, catwalk understanding, collective organization and analysis, and report generation. By posing and exploring such an open-ended, complex and domain-specific task of FashionReGen, it is able to test the general capability of LLMs in fashion domain. It also inspires the explorations of more high-level tasks with industrial significance in other domains. Video illustration and more materials of GPT-FAR can be found in https://github.com/CompFashion/FashionReGen.
Non-Autoregressive Sentence Ordering
Oct 19, 2023
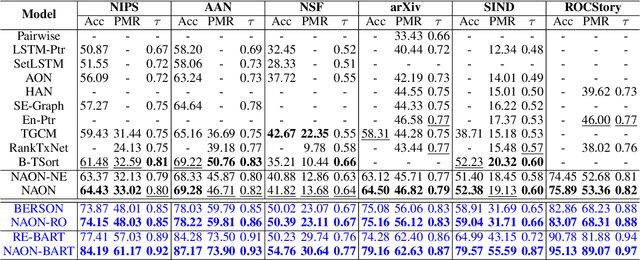
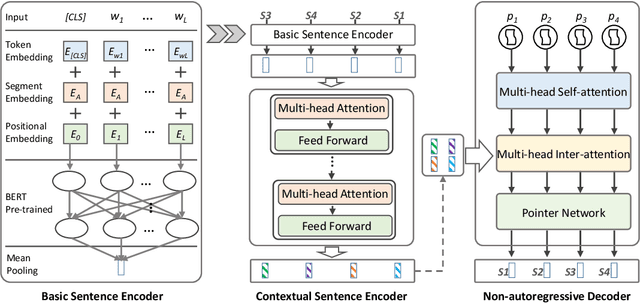
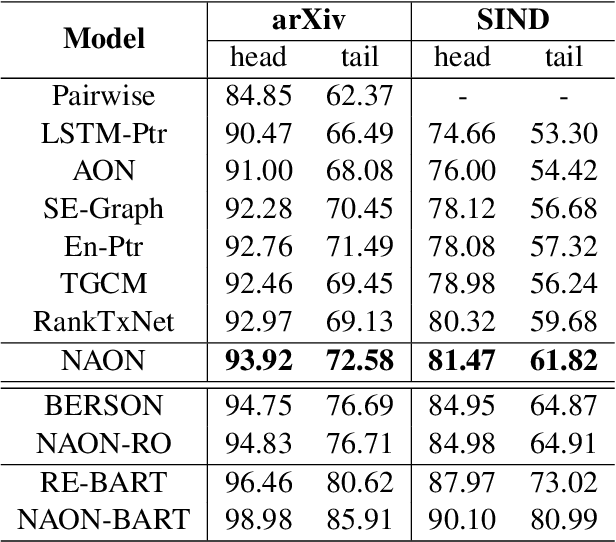
Existing sentence ordering approaches generally employ encoder-decoder frameworks with the pointer net to recover the coherence by recurrently predicting each sentence step-by-step. Such an autoregressive manner only leverages unilateral dependencies during decoding and cannot fully explore the semantic dependency between sentences for ordering. To overcome these limitations, in this paper, we propose a novel Non-Autoregressive Ordering Network, dubbed \textit{NAON}, which explores bilateral dependencies between sentences and predicts the sentence for each position in parallel. We claim that the non-autoregressive manner is not just applicable but also particularly suitable to the sentence ordering task because of two peculiar characteristics of the task: 1) each generation target is in deterministic length, and 2) the sentences and positions should match exclusively. Furthermore, to address the repetition issue of the naive non-autoregressive Transformer, we introduce an exclusive loss to constrain the exclusiveness between positions and sentences. To verify the effectiveness of the proposed model, we conduct extensive experiments on several common-used datasets and the experimental results show that our method outperforms all the autoregressive approaches and yields competitive performance compared with the state-of-the-arts. The codes are available at: \url{https://github.com/steven640pixel/nonautoregressive-sentence-ordering}.
Solving Math Word Problems with Reexamination
Oct 14, 2023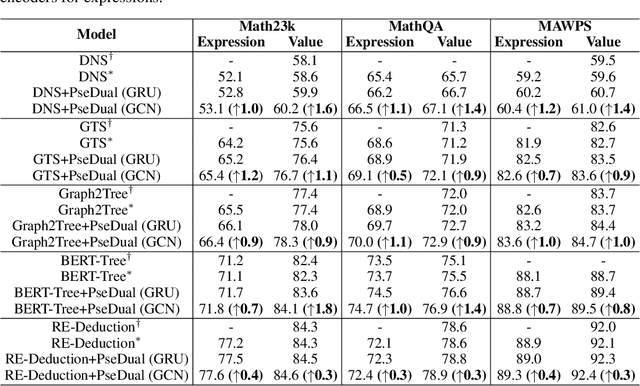
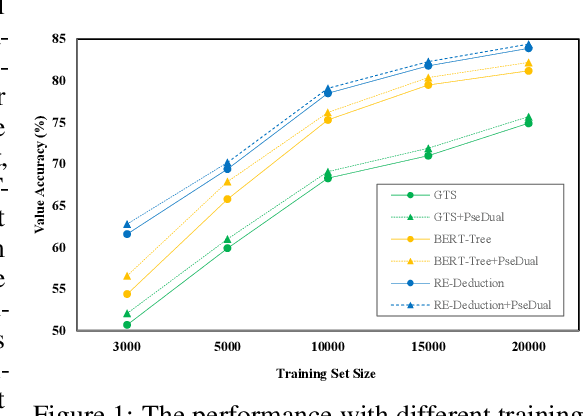
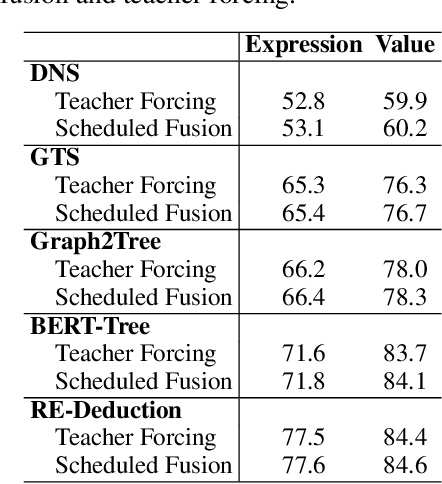
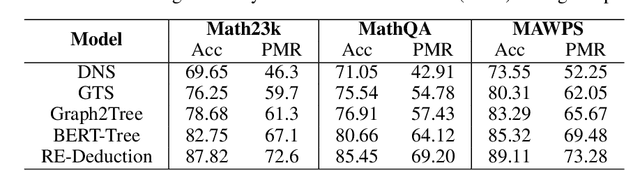
Math word problem (MWP) solving aims to understand the descriptive math problem and calculate the result, for which previous efforts are mostly devoted to upgrade different technical modules. This paper brings a different perspective of \textit{reexamination process} during training by introducing a pseudo-dual task to enhance the MWP solving. We propose a pseudo-dual (PseDual) learning scheme to model such process, which is model-agnostic thus can be adapted to any existing MWP solvers. The pseudo-dual task is specifically defined as filling the numbers in the expression back into the original word problem with numbers masked. To facilitate the effective joint learning of the two tasks, we further design a scheduled fusion strategy for the number infilling task, which smoothly switches the input from the ground-truth math expressions to the predicted ones. Our pseudo-dual learning scheme has been tested and proven effective when being equipped in several representative MWP solvers through empirical studies. \textit{The codes and trained models are available at:} \url{https://github.com/steven640pixel/PsedualMWP}. \end{abstract}
Computational Technologies for Fashion Recommendation: A Survey
Jun 06, 2023



Fashion recommendation is a key research field in computational fashion research and has attracted considerable interest in the computer vision, multimedia, and information retrieval communities in recent years. Due to the great demand for applications, various fashion recommendation tasks, such as personalized fashion product recommendation, complementary (mix-and-match) recommendation, and outfit recommendation, have been posed and explored in the literature. The continuing research attention and advances impel us to look back and in-depth into the field for a better understanding. In this paper, we comprehensively review recent research efforts on fashion recommendation from a technological perspective. We first introduce fashion recommendation at a macro level and analyse its characteristics and differences with general recommendation tasks. We then clearly categorize different fashion recommendation efforts into several sub-tasks and focus on each sub-task in terms of its problem formulation, research focus, state-of-the-art methods, and limitations. We also summarize the datasets proposed in the literature for use in fashion recommendation studies to give readers a brief illustration. Finally, we discuss several promising directions for future research in this field. Overall, this survey systematically reviews the development of fashion recommendation research. It also discusses the current limitations and gaps between academic research and the real needs of the fashion industry. In the process, we offer a deep insight into how the fashion industry could benefit from fashion recommendation technologies. the computational technologies of fashion recommendation.
Modeling Field-level Factor Interactions for Fashion Recommendation
Apr 08, 2022



Personalized fashion recommendation aims to explore patterns from historical interactions between users and fashion items and thereby predict the future ones. It is challenging due to the sparsity of the interaction data and the diversity of user preference in fashion. To tackle the challenge, this paper investigates multiple factor fields in fashion domain, such as colour, style, brand, and tries to specify the implicit user-item interaction into field level. Specifically, an attentional factor field interaction graph (AFFIG) approach is proposed which models both the user-factor interactions and cross-field factors interactions for predicting the recommendation probability at specific field. In addition, an attention mechanism is equipped to aggregate the cross-field factor interactions for each field. Extensive experiments have been conducted on three E-Commerce fashion datasets and the results demonstrate the effectiveness of the proposed method for fashion recommendation. The influence of various factor fields on recommendation in fashion domain is also discussed through experiments.
Leveraging Two Types of Global Graph for Sequential Fashion Recommendation
May 30, 2021



Sequential fashion recommendation is of great significance in online fashion shopping, which accounts for an increasing portion of either fashion retailing or online e-commerce. The key to building an effective sequential fashion recommendation model lies in capturing two types of patterns: the personal fashion preference of users and the transitional relationships between adjacent items. The two types of patterns are usually related to user-item interaction and item-item transition modeling respectively. However, due to the large sets of users and items as well as the sparse historical interactions, it is difficult to train an effective and efficient sequential fashion recommendation model. To tackle these problems, we propose to leverage two types of global graph, i.e., the user-item interaction graph and item-item transition graph, to obtain enhanced user and item representations by incorporating higher-order connections over the graphs. In addition, we adopt the graph kernel of LightGCN for the information propagation in both graphs and propose a new design for item-item transition graph. Extensive experiments on two established sequential fashion recommendation datasets validate the effectiveness and efficiency of our approach.
Reproducibility Companion Paper: Knowledge Enhanced Neural Fashion Trend Forecasting
May 25, 2021



This companion paper supports the replication of the fashion trend forecasting experiments with the KERN (Knowledge Enhanced Recurrent Network) method that we presented in the ICMR 2020. We provide an artifact that allows the replication of the experiments using a Python implementation. The artifact is easy to deploy with simple installation, training and evaluation. We reproduce the experiments conducted in the original paper and obtain similar performance as previously reported. The replication results of the experiments support the main claims in the original paper.
Leveraging Multiple Relations for Fashion Trend Forecasting Based on Social Media
May 11, 2021



Fashion trend forecasting is of great research significance in providing useful suggestions for both fashion companies and fashion lovers. Although various studies have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real complex fashion trends. Moreover, the mainstream solutions for this task are still statistical-based and solely focus on time-series data modeling, which limit the forecast accuracy. Towards insightful fashion trend forecasting, previous work [1] proposed to analyze more fine-grained fashion elements which can informatively reveal fashion trends. Specifically, it focused on detailed fashion element trend forecasting for specific user groups based on social media data. In addition, it proposed a neural network-based method, namely KERN, to address the problem of fashion trend modeling and forecasting. In this work, to extend the previous work, we propose an improved model named Relation Enhanced Attention Recurrent (REAR) network. Compared to KERN, the REAR model leverages not only the relations among fashion elements but also those among user groups, thus capturing more types of correlations among various fashion trends. To further improve the performance of long-range trend forecasting, the REAR method devises a sliding temporal attention mechanism, which is able to capture temporal patterns on future horizons better. Extensive experiments and more analysis have been conducted on the FIT and GeoStyle datasets to evaluate the performance of REAR. Experimental and analytical results demonstrate the effectiveness of the proposed REAR model in fashion trend forecasting, which also show the improvement of REAR compared to the KERN.
* 12 pages, 8 figures
Knowledge Enhanced Neural Fashion Trend Forecasting
May 07, 2020



Fashion trend forecasting is a crucial task for both academia and industry. Although some efforts have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real fashion trends. Towards insightful fashion trend forecasting, this work focuses on investigating fine-grained fashion element trends for specific user groups. We first contribute a large-scale fashion trend dataset (FIT) collected from Instagram with extracted time series fashion element records and user information. Further-more, to effectively model the time series data of fashion elements with rather complex patterns, we propose a Knowledge EnhancedRecurrent Network model (KERN) which takes advantage of the capability of deep recurrent neural networks in modeling time-series data. Moreover, it leverages internal and external knowledge in fashion domain that affects the time-series patterns of fashion element trends. Such incorporation of domain knowledge further enhances the deep learning model in capturing the patterns of specific fashion elements and predicting the future trends. Extensive experiments demonstrate that the proposed KERN model can effectively capture the complicated patterns of objective fashion elements, therefore making preferable fashion trend forecast.
Bilinear Supervised Hashing Based on 2D Image Features
Jan 05, 2019



Hashing has been recognized as an efficient representation learning method to effectively handle big data due to its low computational complexity and memory cost. Most of the existing hashing methods focus on learning the low-dimensional vectorized binary features based on the high-dimensional raw vectorized features. However, studies on how to obtain preferable binary codes from the original 2D image features for retrieval is very limited. This paper proposes a bilinear supervised discrete hashing (BSDH) method based on 2D image features which utilizes bilinear projections to binarize the image matrix features such that the intrinsic characteristics in the 2D image space are preserved in the learned binary codes. Meanwhile, the bilinear projection approximation and vectorization binary codes regression are seamlessly integrated together to formulate the final robust learning framework. Furthermore, a discrete optimization strategy is developed to alternatively update each variable for obtaining the high-quality binary codes. In addition, two 2D image features, traditional SURF-based FVLAD feature and CNN-based AlexConv5 feature are designed for further improving the performance of the proposed BSDH method. Results of extensive experiments conducted on four benchmark datasets show that the proposed BSDH method almost outperforms all competing hashing methods with different input features by different evaluation protocols.