 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunhong Wang
LSP Framework: A Compensatory Model for Defeating Trigger Reverse Engineering via Label Smoothing Poisoning
Apr 19, 2024
Deep neural networks are vulnerable to backdoor attacks. Among the existing backdoor defense methods, trigger reverse engineering based approaches, which reconstruct the backdoor triggers via optimizations, are the most versatile and effective ones compared to other types of methods. In this paper, we summarize and construct a generic paradigm for the typical trigger reverse engineering process. Based on this paradigm, we propose a new perspective to defeat trigger reverse engineering by manipulating the classification confidence of backdoor samples. To determine the specific modifications of classification confidence, we propose a compensatory model to compute the lower bound of the modification. With proper modifications, the backdoor attack can easily bypass the trigger reverse engineering based methods. To achieve this objective, we propose a Label Smoothing Poisoning (LSP) framework, which leverages label smoothing to specifically manipulate the classification confidences of backdoor samples. Extensive experiments demonstrate that the proposed work can defeat the state-of-the-art trigger reverse engineering based methods, and possess good compatibility with a variety of existing backdoor attacks.
AED-PADA:Improving Generalizability of Adversarial Example Detection via Principal Adversarial Domain Adaptation
Apr 19, 2024Adversarial example detection, which can be conveniently applied in many scenarios, is important in the area of adversarial defense. Unfortunately, existing detection methods suffer from poor generalization performance, because their training process usually relies on the examples generated from a single known adversarial attack and there exists a large discrepancy between the training and unseen testing adversarial examples. To address this issue, we propose a novel method, named Adversarial Example Detection via Principal Adversarial Domain Adaptation (AED-PADA). Specifically, our approach identifies the Principal Adversarial Domains (PADs), i.e., a combination of features of the adversarial examples from different attacks, which possesses large coverage of the entire adversarial feature space. Then, we pioneer to exploit multi-source domain adaptation in adversarial example detection with PADs as source domains. Experiments demonstrate the superior generalization ability of our proposed AED-PADA. Note that this superiority is particularly achieved in challenging scenarios characterized by employing the minimal magnitude constraint for the perturbations.
YOLC: You Only Look Clusters for Tiny Object Detection in Aerial Images
Apr 09, 2024Detecting objects from aerial images poses significant challenges due to the following factors: 1) Aerial images typically have very large sizes, generally with millions or even hundreds of millions of pixels, while computational resources are limited. 2) Small object size leads to insufficient information for effective detection. 3) Non-uniform object distribution leads to computational resource wastage. To address these issues, we propose YOLC (You Only Look Clusters), an efficient and effective framework that builds on an anchor-free object detector, CenterNet. To overcome the challenges posed by large-scale images and non-uniform object distribution, we introduce a Local Scale Module (LSM) that adaptively searches cluster regions for zooming in for accurate detection. Additionally, we modify the regression loss using Gaussian Wasserstein distance (GWD) to obtain high-quality bounding boxes. Deformable convolution and refinement methods are employed in the detection head to enhance the detection of small objects. We perform extensive experiments on two aerial image datasets, including Visdrone2019 and UAVDT, to demonstrate the effectiveness and superiority of our proposed approach.
Generic Knowledge Boosted Pre-training For Remote Sensing Images
Jan 21, 2024Deep learning models are essential for scene classification, change detection, land cover segmentation, and other remote sensing image understanding tasks. Most backbones of existing remote sensing deep learning models are typically initialized by pre-trained weights obtained from ImageNet pre-training (IMP). However, domain gaps exist between remote sensing images and natural images (e.g., ImageNet), making deep learning models initialized by pre-trained weights of IMP perform poorly for remote sensing image understanding. Although some pre-training methods are studied in the remote sensing community, current remote sensing pre-training methods face the problem of vague generalization by only using remote sensing images. In this paper, we propose a novel remote sensing pre-training framework, Generic Knowledge Boosted Remote Sensing Pre-training (GeRSP), to learn robust representations from remote sensing and natural images for remote sensing understanding tasks. GeRSP contains two pre-training branches: (1) A self-supervised pre-training branch is adopted to learn domain-related representations from unlabeled remote sensing images. (2) A supervised pre-training branch is integrated into GeRSP for general knowledge learning from labeled natural images. Moreover, GeRSP combines two pre-training branches using a teacher-student architecture to simultaneously learn representations with general and special knowledge, which generates a powerful pre-trained model for deep learning model initialization. Finally, we evaluate GeRSP and other remote sensing pre-training methods on three downstream tasks, i.e., object detection, semantic segmentation, and scene classification. The extensive experimental results consistently demonstrate that GeRSP can effectively learn robust representations in a unified manner, improving the performance of remote sensing downstream tasks.
Understanding Heterophily for Graph Neural Networks
Jan 17, 2024Graphs with heterophily have been regarded as challenging scenarios for Graph Neural Networks (GNNs), where nodes are connected with dissimilar neighbors through various patterns. In this paper, we present theoretical understandings of the impacts of different heterophily patterns for GNNs by incorporating the graph convolution (GC) operations into fully connected networks via the proposed Heterophilous Stochastic Block Models (HSBM), a general random graph model that can accommodate diverse heterophily patterns. Firstly, we show that by applying a GC operation, the separability gains are determined by two factors, i.e., the Euclidean distance of the neighborhood distributions and $\sqrt{\mathbb{E}\left[\operatorname{deg}\right]}$, where $\mathbb{E}\left[\operatorname{deg}\right]$ is the averaged node degree. It reveals that the impact of heterophily on classification needs to be evaluated alongside the averaged node degree. Secondly, we show that the topological noise has a detrimental impact on separability, which is equivalent to degrading $\mathbb{E}\left[\operatorname{deg}\right]$. Finally, when applying multiple GC operations, we show that the separability gains are determined by the normalized distance of the $l$-powered neighborhood distributions. It indicates that the nodes still possess separability as $l$ goes to infinity in a wide range of regimes. Extensive experiments on both synthetic and real-world data verify the effectiveness of our theory.
Towards Generalizable Referring Image Segmentation via Target Prompt and Visual Coherence
Dec 01, 2023Referring image segmentation (RIS) aims to segment objects in an image conditioning on free-from text descriptions. Despite the overwhelming progress, it still remains challenging for current approaches to perform well on cases with various text expressions or with unseen visual entities, limiting its further application. In this paper, we present a novel RIS approach, which substantially improves the generalization ability by addressing the two dilemmas mentioned above. Specially, to deal with unconstrained texts, we propose to boost a given expression with an explicit and crucial prompt, which complements the expression in a unified context, facilitating target capturing in the presence of linguistic style changes. Furthermore, we introduce a multi-modal fusion aggregation module with visual guidance from a powerful pretrained model to leverage spatial relations and pixel coherences to handle the incomplete target masks and false positive irregular clumps which often appear on unseen visual entities. Extensive experiments are conducted in the zero-shot cross-dataset settings and the proposed approach achieves consistent gains compared to the state-of-the-art, e.g., 4.15\%, 5.45\%, and 4.64\% mIoU increase on RefCOCO, RefCOCO+ and ReferIt respectively, demonstrating its effectiveness. Additionally, the results on GraspNet-RIS show that our approach also generalizes well to new scenarios with large domain shifts.
DUA-DA: Distillation-based Unbiased Alignment for Domain Adaptive Object Detection
Nov 17, 2023Though feature-alignment based Domain Adaptive Object Detection (DAOD) have achieved remarkable progress, they ignore the source bias issue, i.e. the aligned features are more favorable towards the source domain, leading to a sub-optimal adaptation. Furthermore, the presence of domain shift between the source and target domains exacerbates the problem of inconsistent classification and localization in general detection pipelines. To overcome these challenges, we propose a novel Distillation-based Unbiased Alignment (DUA) framework for DAOD, which can distill the source features towards a more balanced position via a pre-trained teacher model during the training process, alleviating the problem of source bias effectively. In addition, we design a Target-Relevant Object Localization Network (TROLN), which can mine target-related knowledge to produce two classification-free metrics (IoU and centerness). Accordingly, we implement a Domain-aware Consistency Enhancing (DCE) strategy that utilizes these two metrics to further refine classification confidences, achieving a harmonization between classification and localization in cross-domain scenarios. Extensive experiments have been conducted to manifest the effectiveness of this method, which consistently improves the strong baseline by large margins, outperforming existing alignment-based works.
ActiveDC: Distribution Calibration for Active Finetuning
Nov 15, 2023The pretraining-finetuning paradigm has gained popularity in various computer vision tasks. In this paradigm, the emergence of active finetuning arises due to the abundance of large-scale data and costly annotation requirements. Active finetuning involves selecting a subset of data from an unlabeled pool for annotation, facilitating subsequent finetuning. However, the use of a limited number of training samples can lead to a biased distribution, potentially resulting in model overfitting. In this paper, we propose a new method called ActiveDC for the active finetuning tasks. Firstly, we select samples for annotation by optimizing the distribution similarity between the subset to be selected and the entire unlabeled pool in continuous space. Secondly, we calibrate the distribution of the selected samples by exploiting implicit category information in the unlabeled pool. The feature visualization provides an intuitive sense of the effectiveness of our approach to distribution calibration. We conducted extensive experiments on three image classification datasets with different sampling ratios. The results indicate that ActiveDC consistently outperforms the baseline performance in all image classification tasks. The improvement is particularly significant when the sampling ratio is low, with performance gains of up to 10%. Our code will be released.
Learning Historical Status Prompt for Accurate and Robust Visual Tracking
Nov 03, 2023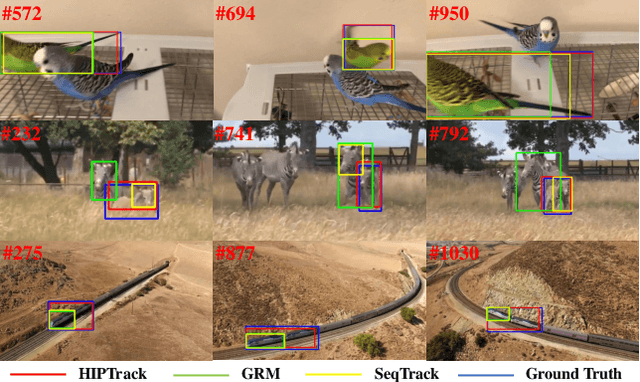
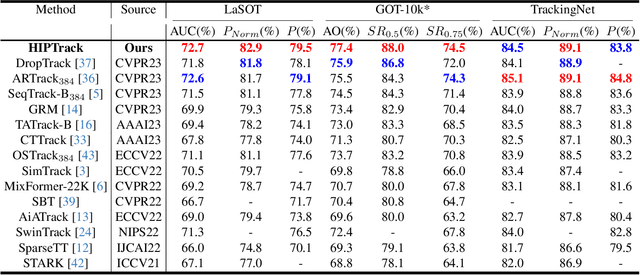
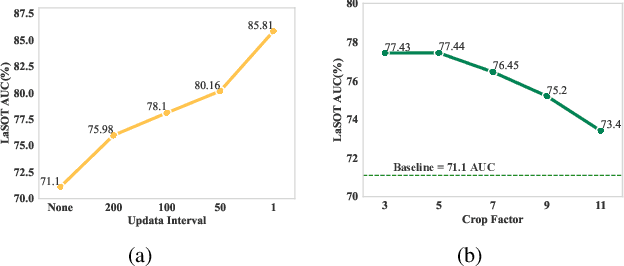

Most trackers perform template and search region similarity matching to find the most similar object to the template during tracking. However, they struggle to make prediction when the target appearance changes due to the limited historical information introduced by roughly cropping the current search region based on the predicted result of previous frame. In this paper, we identify that the central impediment to improving the performance of existing trackers is the incapacity to integrate abundant and effective historical information. To address this issue, we propose a Historical Information Prompter (HIP) to enhance the provision of historical information. We also build HIPTrack upon HIP module. HIP is a plug-and-play module that make full use of search region features to introduce historical appearance information. It also incorporates historical position information by constructing refined mask of the target. HIP is a lightweight module to generate historical information prompts. By integrating historical information prompts, HIPTrack significantly enhances the tracking performance without the need to retrain the backbone. Experimental results demonstrate that our method outperforms all state-of-the-art approaches on LaSOT, LaSOT ext, GOT10k and NfS. Futhermore, HIP module exhibits strong generality and can be seamlessly integrated into trackers to improve tracking performance. The source code and models will be released for further research.
Improving Multi-Person Pose Tracking with A Confidence Network
Oct 29, 2023Human pose estimation and tracking are fundamental tasks for understanding human behaviors in videos. Existing top-down framework-based methods usually perform three-stage tasks: human detection, pose estimation and tracking. Although promising results have been achieved, these methods rely heavily on high-performance detectors and may fail to track persons who are occluded or miss-detected. To overcome these problems, in this paper, we develop a novel keypoint confidence network and a tracking pipeline to improve human detection and pose estimation in top-down approaches. Specifically, the keypoint confidence network is designed to determine whether each keypoint is occluded, and it is incorporated into the pose estimation module. In the tracking pipeline, we propose the Bbox-revision module to reduce missing detection and the ID-retrieve module to correct lost trajectories, improving the performance of the detection stage. Experimental results show that our approach is universal in human detection and pose estimation, achieving state-of-the-art performance on both PoseTrack 2017 and 2018 datasets.