 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunshan Zhong
Learning Image Demoireing from Unpaired Real Data
Jan 05, 2024
This paper focuses on addressing the issue of image demoireing. Unlike the large volume of existing studies that rely on learning from paired real data, we attempt to learn a demoireing model from unpaired real data, i.e., moire images associated with irrelevant clean images. The proposed method, referred to as Unpaired Demoireing (UnDeM), synthesizes pseudo moire images from unpaired datasets, generating pairs with clean images for training demoireing models. To achieve this, we divide real moire images into patches and group them in compliance with their moire complexity. We introduce a novel moire generation framework to synthesize moire images with diverse moire features, resembling real moire patches, and details akin to real moire-free images. Additionally, we introduce an adaptive denoise method to eliminate the low-quality pseudo moire images that adversely impact the learning of demoireing models. We conduct extensive experiments on the commonly-used FHDMi and UHDM datasets. Results manifest that our UnDeM performs better than existing methods when using existing demoireing models such as MBCNN and ESDNet-L. Code: https://github.com/zysxmu/UnDeM
I&S-ViT: An Inclusive & Stable Method for Pushing the Limit of Post-Training ViTs Quantization
Nov 16, 2023Albeit the scalable performance of vision transformers (ViTs), the dense computational costs (training & inference) undermine their position in industrial applications. Post-training quantization (PTQ), tuning ViTs with a tiny dataset and running in a low-bit format, well addresses the cost issue but unluckily bears more performance drops in lower-bit cases. In this paper, we introduce I&S-ViT, a novel method that regulates the PTQ of ViTs in an inclusive and stable fashion. I&S-ViT first identifies two issues in the PTQ of ViTs: (1) Quantization inefficiency in the prevalent log2 quantizer for post-Softmax activations; (2) Rugged and magnified loss landscape in coarse-grained quantization granularity for post-LayerNorm activations. Then, I&S-ViT addresses these issues by introducing: (1) A novel shift-uniform-log2 quantizer (SULQ) that incorporates a shift mechanism followed by uniform quantization to achieve both an inclusive domain representation and accurate distribution approximation; (2) A three-stage smooth optimization strategy (SOS) that amalgamates the strengths of channel-wise and layer-wise quantization to enable stable learning. Comprehensive evaluations across diverse vision tasks validate I&S-ViT' superiority over existing PTQ of ViTs methods, particularly in low-bit scenarios. For instance, I&S-ViT elevates the performance of 3-bit ViT-B by an impressive 50.68%.
Spatial Re-parameterization for N:M Sparsity
Jun 09, 2023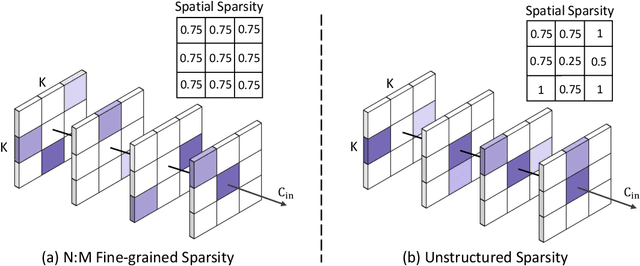
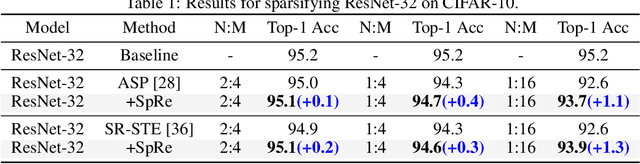


This paper presents a Spatial Re-parameterization (SpRe) method for the N:M sparsity in CNNs. SpRe is stemmed from an observation regarding the restricted variety in spatial sparsity present in N:M sparsity compared with unstructured sparsity. Particularly, N:M sparsity exhibits a fixed sparsity rate within the spatial domains due to its distinctive pattern that mandates N non-zero components among M successive weights in the input channel dimension of convolution filters. On the contrary, we observe that unstructured sparsity displays a substantial divergence in sparsity across the spatial domains, which we experimentally verified to be very crucial for its robust performance retention compared with N:M sparsity. Therefore, SpRe employs the spatial-sparsity distribution of unstructured sparsity to assign an extra branch in conjunction with the original N:M branch at training time, which allows the N:M sparse network to sustain a similar distribution of spatial sparsity with unstructured sparsity. During inference, the extra branch can be further re-parameterized into the main N:M branch, without exerting any distortion on the sparse pattern or additional computation costs. SpRe has achieved a commendable feat by matching the performance of N:M sparsity methods with state-of-the-art unstructured sparsity methods across various benchmarks. Code and models are anonymously available at \url{https://github.com/zyxxmu/SpRe}.
MultiQuant: A Novel Multi-Branch Topology Method for Arbitrary Bit-width Network Quantization
May 14, 2023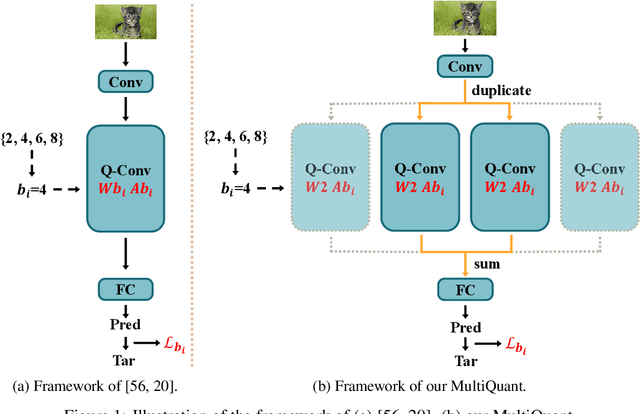

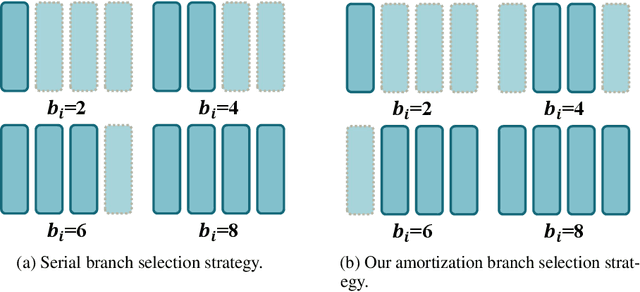
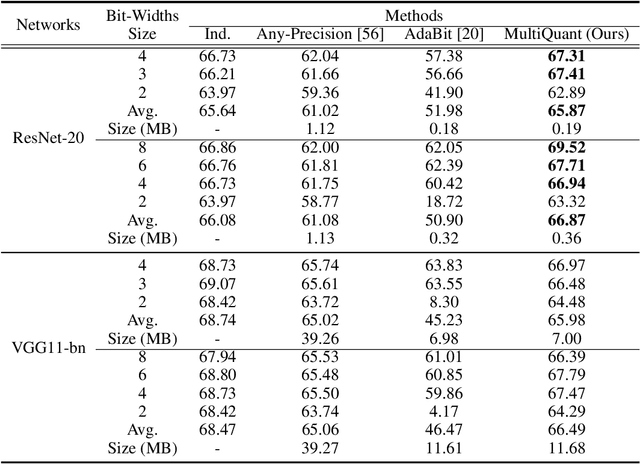
Arbitrary bit-width network quantization has received significant attention due to its high adaptability to various bit-width requirements during runtime. However, in this paper, we investigate existing methods and observe a significant accumulation of quantization errors caused by frequent bit-width switching of weights and activations, leading to limited performance. To address this issue, we propose MultiQuant, a novel method that utilizes a multi-branch topology for arbitrary bit-width quantization. MultiQuant duplicates the network body into multiple independent branches and quantizes the weights of each branch to a fixed 2-bit while retaining the input activations in the expected bit-width. This approach maintains the computational cost as the same while avoiding the switching of weight bit-widths, thereby substantially reducing errors in weight quantization. Additionally, we introduce an amortization branch selection strategy to distribute quantization errors caused by activation bit-width switching among branches to enhance performance. Finally, we design an in-place distillation strategy that facilitates guidance between branches to further enhance MultiQuant's performance. Extensive experiments demonstrate that MultiQuant achieves significant performance gains compared to existing arbitrary bit-width quantization methods. Code is at \url{https://github.com/zysxmu/MultiQuant}.
Distribution-Flexible Subset Quantization for Post-Quantizing Super-Resolution Networks
May 12, 2023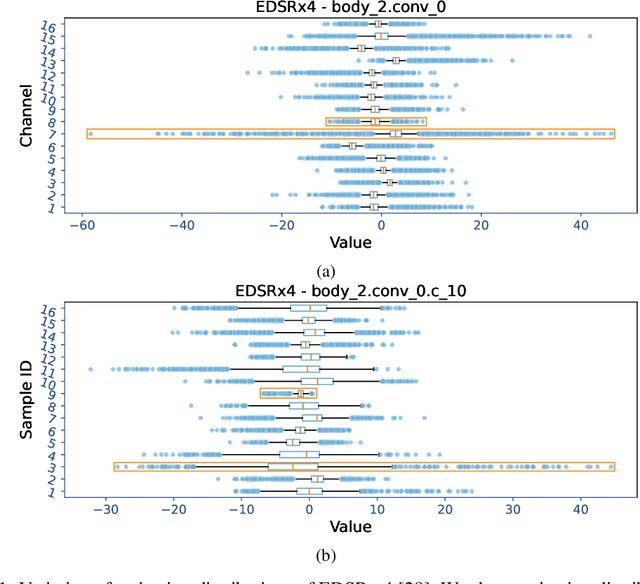
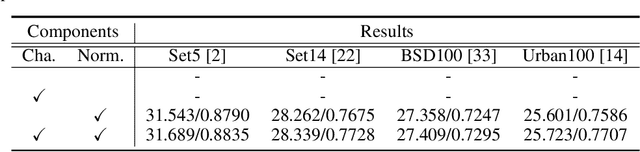
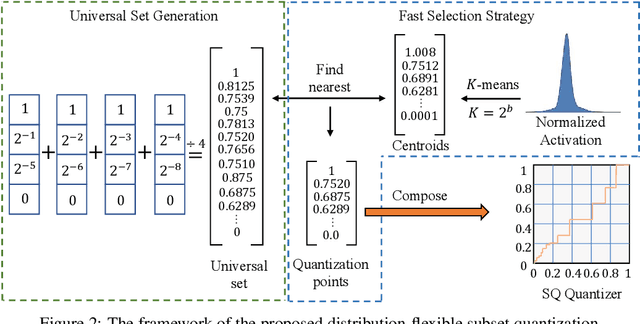
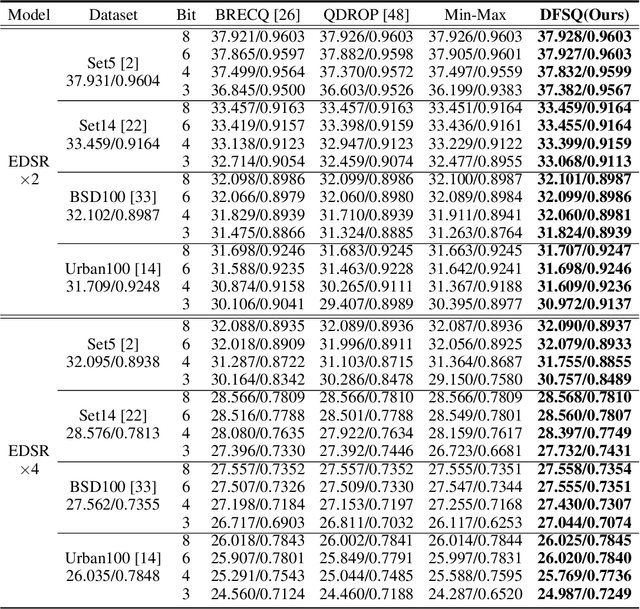
This paper introduces Distribution-Flexible Subset Quantization (DFSQ), a post-training quantization method for super-resolution networks. Our motivation for developing DFSQ is based on the distinctive activation distributions of current super-resolution models, which exhibit significant variance across samples and channels. To address this issue, DFSQ conducts channel-wise normalization of the activations and applies distribution-flexible subset quantization (SQ), wherein the quantization points are selected from a universal set consisting of multi-word additive log-scale values. To expedite the selection of quantization points in SQ, we propose a fast quantization points selection strategy that uses K-means clustering to select the quantization points closest to the centroids. Compared to the common iterative exhaustive search algorithm, our strategy avoids the enumeration of all possible combinations in the universal set, reducing the time complexity from exponential to linear. Consequently, the constraint of time costs on the size of the universal set is greatly relaxed. Extensive evaluations of various super-resolution models show that DFSQ effectively retains performance even without fine-tuning. For example, when quantizing EDSRx2 on the Urban benchmark, DFSQ achieves comparable performance to full-precision counterparts on 6- and 8-bit quantization, and incurs only a 0.1 dB PSNR drop on 4-bit quantization. Code is at \url{https://github.com/zysxmu/DFSQ}
Bi-directional Masks for Efficient N:M Sparse Training
Feb 13, 2023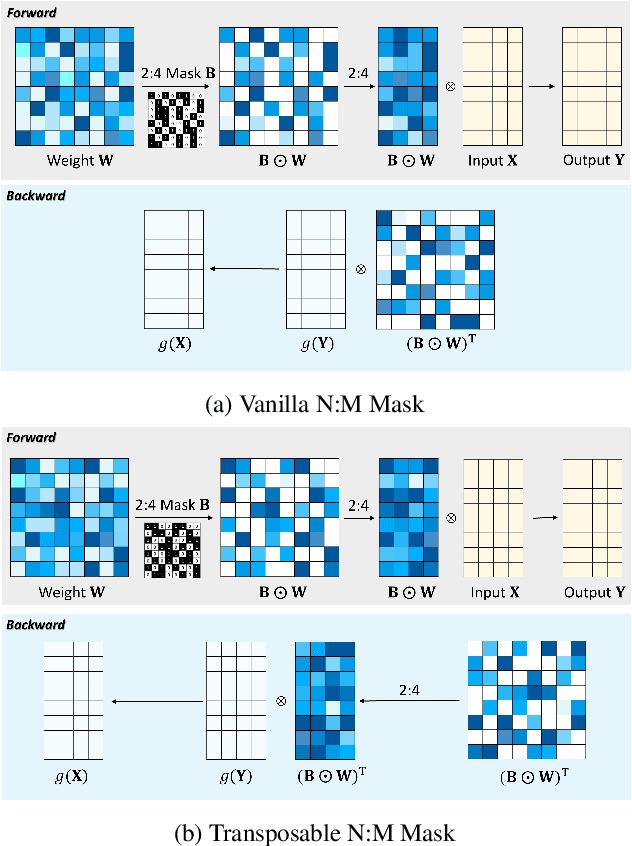

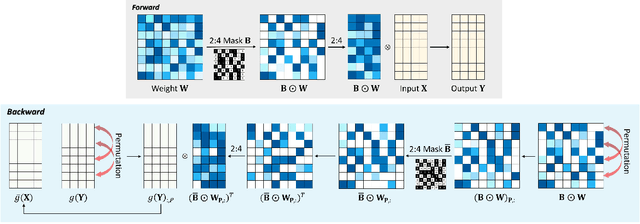
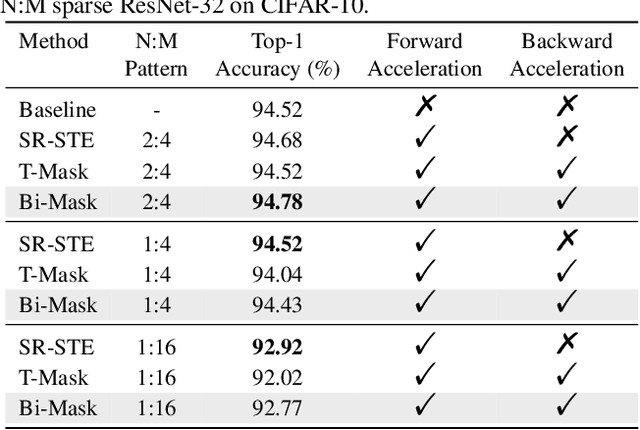
We focus on addressing the dense backward propagation issue for training efficiency of N:M fine-grained sparsity that preserves at most N out of M consecutive weights and achieves practical speedups supported by the N:M sparse tensor core. Therefore, we present a novel method of Bi-directional Masks (Bi-Mask) with its two central innovations in: 1) Separate sparse masks in the two directions of forward and backward propagation to obtain training acceleration. It disentangles the forward and backward weight sparsity and overcomes the very dense gradient computation. 2) An efficient weight row permutation method to maintain performance. It picks up the permutation candidate with the most eligible N:M weight blocks in the backward to minimize the gradient gap between traditional uni-directional masks and our bi-directional masks. Compared with existing uni-directional scenario that applies a transposable mask and enables backward acceleration, our Bi-Mask is experimentally demonstrated to be more superior in performance. Also, our Bi-Mask performs on par with or even better than methods that fail to achieve backward acceleration. Project of this paper is available at \url{https://github.com/zyxxmu/Bi-Mask}.
Shadow Removal by High-Quality Shadow Synthesis
Dec 08, 2022
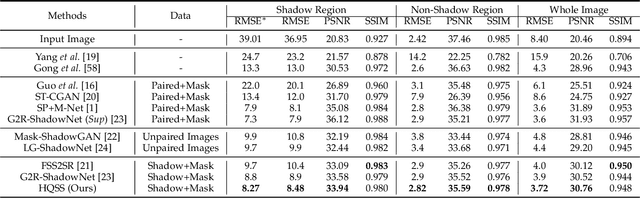
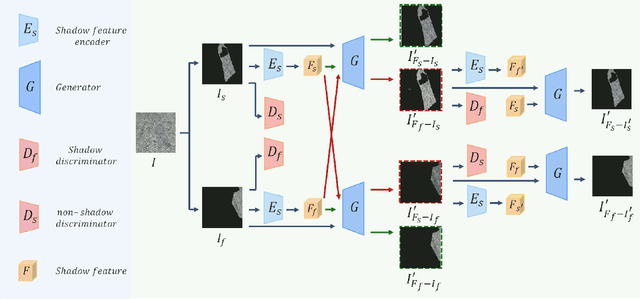
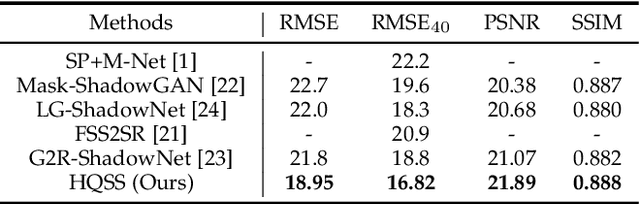
Most shadow removal methods rely on the invasion of training images associated with laborious and lavish shadow region annotations, leading to the increasing popularity of shadow image synthesis. However, the poor performance also stems from these synthesized images since they are often shadow-inauthentic and details-impaired. In this paper, we present a novel generation framework, referred to as HQSS, for high-quality pseudo shadow image synthesis. The given image is first decoupled into a shadow region identity and a non-shadow region identity. HQSS employs a shadow feature encoder and a generator to synthesize pseudo images. Specifically, the encoder extracts the shadow feature of a region identity which is then paired with another region identity to serve as the generator input to synthesize a pseudo image. The pseudo image is expected to have the shadow feature as its input shadow feature and as well as a real-like image detail as its input region identity. To fulfill this goal, we design three learning objectives. When the shadow feature and input region identity are from the same region identity, we propose a self-reconstruction loss that guides the generator to reconstruct an identical pseudo image as its input. When the shadow feature and input region identity are from different identities, we introduce an inter-reconstruction loss and a cycle-reconstruction loss to make sure that shadow characteristics and detail information can be well retained in the synthesized images. Our HQSS is observed to outperform the state-of-the-art methods on ISTD dataset, Video Shadow Removal dataset, and SRD dataset. The code is available at https://github.com/zysxmu/HQSS.
Exploiting the Partly Scratch-off Lottery Ticket for Quantization-Aware Training
Nov 21, 2022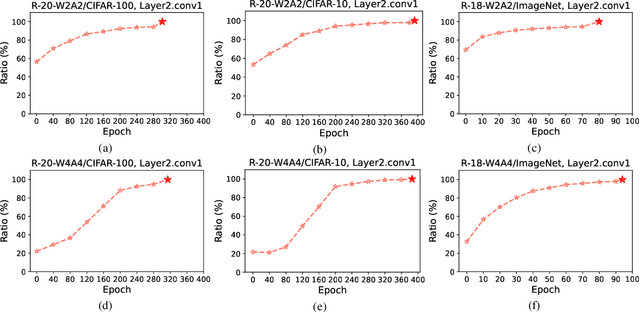
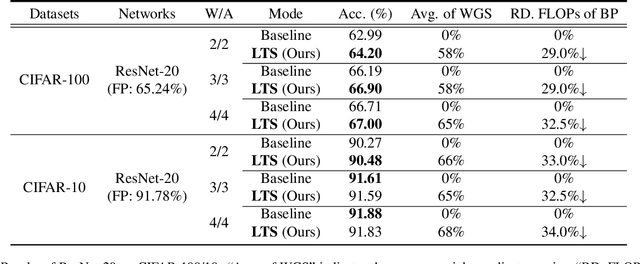
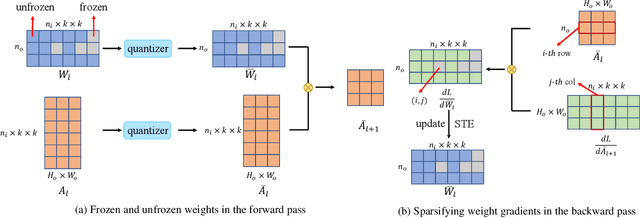
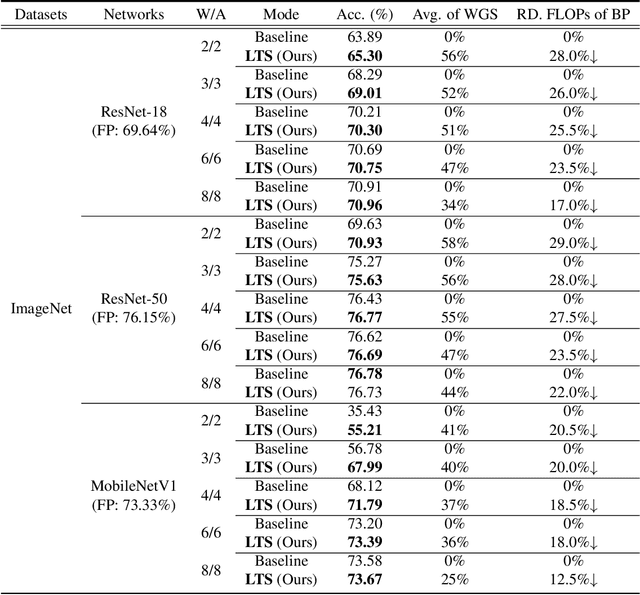
Quantization-aware training (QAT) receives extensive popularity as it well retains the performance of quantized networks. In QAT, the contemporary experience is that all quantized weights are updated for an entire training process. In this paper, this experience is challenged based on an interesting phenomenon we observed. Specifically, a large portion of quantized weights reaches the optimal quantization level after a few training epochs, which we refer to as the partly scratch-off lottery ticket. This straightforward-yet-valuable observation naturally inspires us to zero out gradient calculations of these weights in the remaining training period to avoid meaningless updating. To effectively find the ticket, we develop a heuristic method, dubbed as lottery ticket scratcher (LTS), which freezes a weight once the distance between the full-precision one and its quantization level is smaller than a controllable threshold. Surprisingly, the proposed LTS typically eliminates 30%-60% weight updating and 15%-30% FLOPs of the backward pass, while still resulting on par with or even better performance than the compared baseline. For example, compared with the baseline, LTS improves 2-bit ResNet-18 by 1.41%, eliminating 56% weight updating and 28% FLOPs of the backward pass. Code is at https://github.com/zysxmu/LTS.
Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks
Mar 10, 2022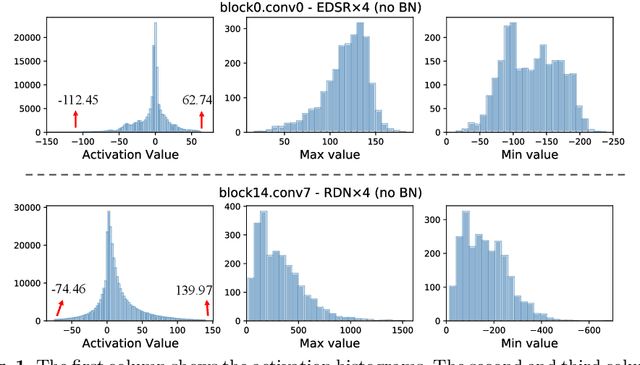
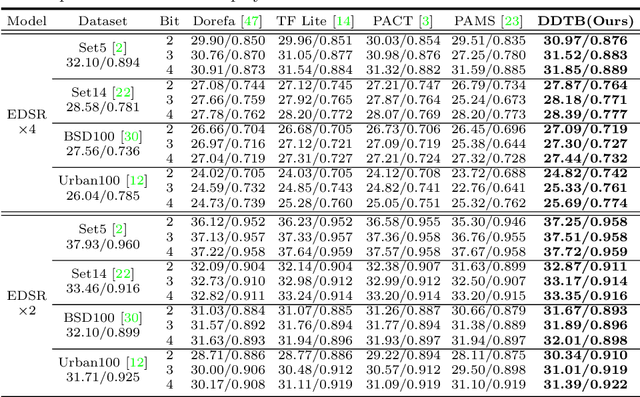
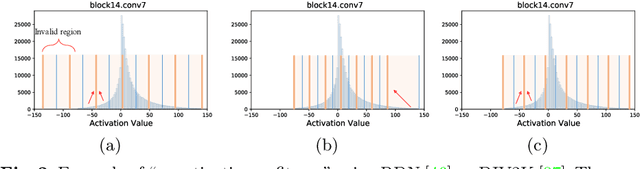
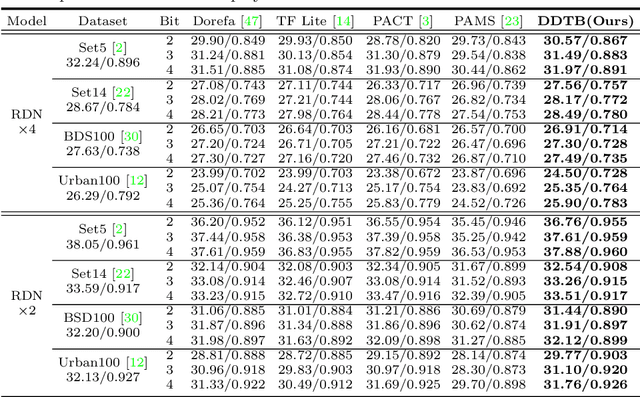
Light-weight super-resolution (SR) models have received considerable attention for their serviceability in mobile devices. Many efforts employ network quantization to compress SR models. However, these methods suffer from severe performance degradation when quantizing the SR models to ultra-low precision (e.g., 2-bit and 3-bit) with the low-cost layer-wise quantizer. In this paper, we identify that the performance drop comes from the contradiction between the layer-wise symmetric quantizer and the highly asymmetric activation distribution in SR models. This discrepancy leads to either a waste on the quantization levels or detail loss in reconstructed images. Therefore, we propose a novel activation quantizer, referred to as Dynamic Dual Trainable Bounds (DDTB), to accommodate the asymmetry of the activations. Specifically, DDTB innovates in: 1) A layer-wise quantizer with trainable upper and lower bounds to tackle the highly asymmetric activations. 2) A dynamic gate controller to adaptively adjust the upper and lower bounds at runtime to overcome the drastically varying activation ranges over different samples.To reduce the extra overhead, the dynamic gate controller is quantized to 2-bit and applied to only part of the SR networks according to the introduced dynamic intensity. Extensive experiments demonstrate that our DDTB exhibits significant performance improvements in ultra-low precision. For example, our DDTB achieves a 0.70dB PSNR increase on Urban100 benchmark when quantizing EDSR to 2-bit and scaling up output images to x4. Code is at \url{https://github.com/zysxmu/DDTB}.
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization
Dec 03, 2021
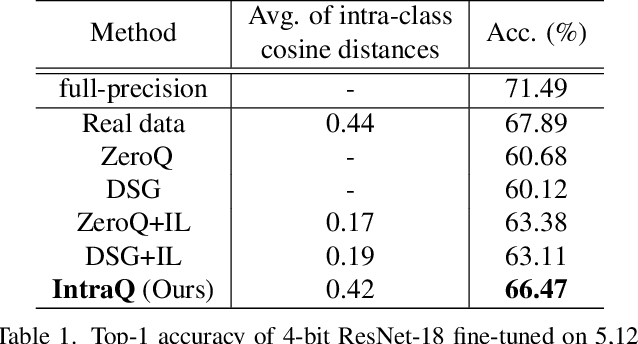
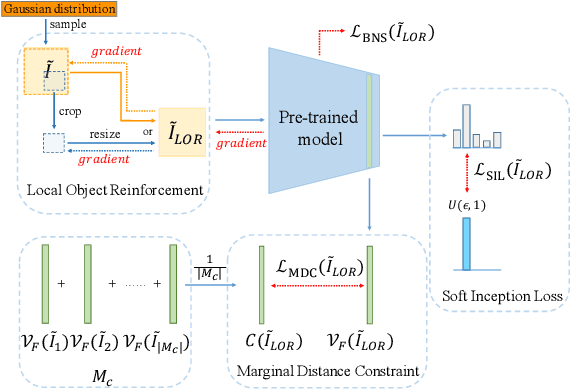
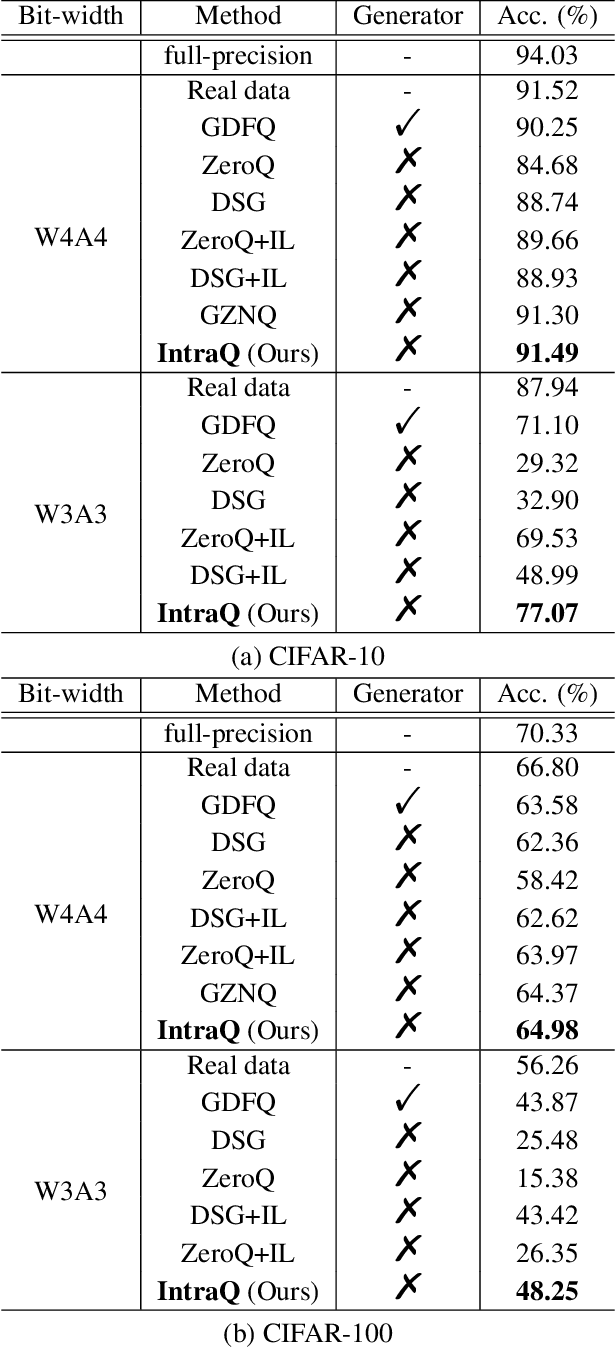
Learning to synthesize data has emerged as a promising direction in zero-shot quantization (ZSQ), which represents neural networks by low-bit integer without accessing any of the real data. In this paper, we observe an interesting phenomenon of intra-class heterogeneity in real data and show that existing methods fail to retain this property in their synthetic images, which causes a limited performance increase. To address this issue, we propose a novel zero-shot quantization method referred to as IntraQ. First, we propose a local object reinforcement that locates the target objects at different scales and positions of the synthetic images. Second, we introduce a marginal distance constraint to form class-related features distributed in a coarse area. Lastly, we devise a soft inception loss which injects a soft prior label to prevent the synthetic images from being overfitting to a fixed object. Our IntraQ is demonstrated to well retain the intra-class heterogeneity in the synthetic images and also observed to perform state-of-the-art. For example, compared to the advanced ZSQ, our IntraQ obtains 9.17\% increase of the top-1 accuracy on ImageNet when all layers of MobileNetV1 are quantized to 4-bit. Code is at https://github.com/zysxmu/InterQ.