 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunsu Kim
Leveraging the Interplay Between Syntactic and Acoustic Cues for Optimizing Korean TTS Pause Formation
Apr 03, 2024
Contemporary neural speech synthesis models have indeed demonstrated remarkable proficiency in synthetic speech generation as they have attained a level of quality comparable to that of human-produced speech. Nevertheless, it is important to note that these achievements have predominantly been verified within the context of high-resource languages such as English. Furthermore, the Tacotron and FastSpeech variants show substantial pausing errors when applied to the Korean language, which affects speech perception and naturalness. In order to address the aforementioned issues, we propose a novel framework that incorporates comprehensive modeling of both syntactic and acoustic cues that are associated with pausing patterns. Remarkably, our framework possesses the capability to consistently generate natural speech even for considerably more extended and intricate out-of-domain (OOD) sentences, despite its training on short audio clips. Architectural design choices are validated through comparisons with baseline models and ablation studies using subjective and objective metrics, thus confirming model performance.
Evalverse: Unified and Accessible Library for Large Language Model Evaluation
Apr 01, 2024This paper introduces Evalverse, a novel library that streamlines the evaluation of Large Language Models (LLMs) by unifying disparate evaluation tools into a single, user-friendly framework. Evalverse enables individuals with limited knowledge of artificial intelligence to easily request LLM evaluations and receive detailed reports, facilitated by an integration with communication platforms like Slack. Thus, Evalverse serves as a powerful tool for the comprehensive assessment of LLMs, offering both researchers and practitioners a centralized and easily accessible evaluation framework. Finally, we also provide a demo video for Evalverse, showcasing its capabilities and implementation in a two-minute format.
Explainable Multi-hop Question Generation: An End-to-End Approach without Intermediate Question Labeling
Mar 31, 2024In response to the increasing use of interactive artificial intelligence, the demand for the capacity to handle complex questions has increased. Multi-hop question generation aims to generate complex questions that requires multi-step reasoning over several documents. Previous studies have predominantly utilized end-to-end models, wherein questions are decoded based on the representation of context documents. However, these approaches lack the ability to explain the reasoning process behind the generated multi-hop questions. Additionally, the question rewriting approach, which incrementally increases the question complexity, also has limitations due to the requirement of labeling data for intermediate-stage questions. In this paper, we introduce an end-to-end question rewriting model that increases question complexity through sequential rewriting. The proposed model has the advantage of training with only the final multi-hop questions, without intermediate questions. Experimental results demonstrate the effectiveness of our model in generating complex questions, particularly 3- and 4-hop questions, which are appropriately paired with input answers. We also prove that our model logically and incrementally increases the complexity of questions, and the generated multi-hop questions are also beneficial for training question answering models.
sDPO: Don't Use Your Data All at Once
Mar 28, 2024



As development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning. This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework. Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.
Denoising Table-Text Retrieval for Open-Domain Question Answering
Mar 26, 2024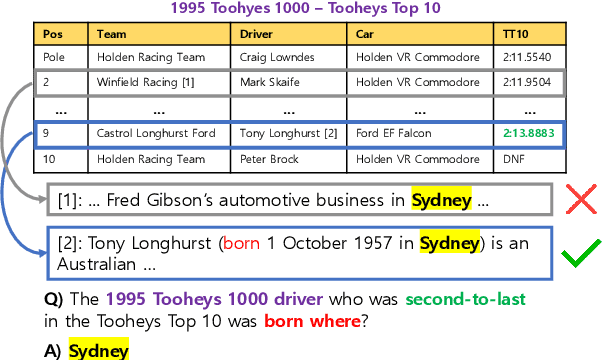
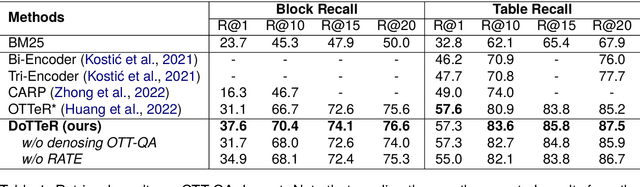
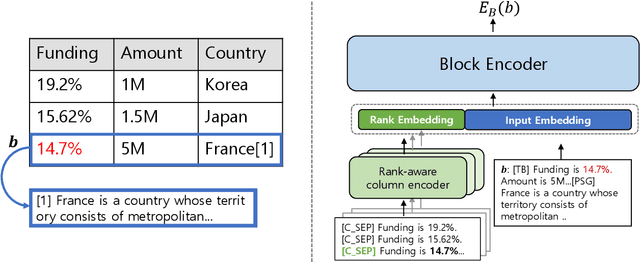
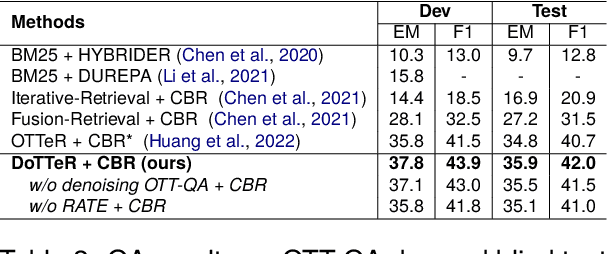
In table-text open-domain question answering, a retriever system retrieves relevant evidence from tables and text to answer questions. Previous studies in table-text open-domain question answering have two common challenges: firstly, their retrievers can be affected by false-positive labels in training datasets; secondly, they may struggle to provide appropriate evidence for questions that require reasoning across the table. To address these issues, we propose Denoised Table-Text Retriever (DoTTeR). Our approach involves utilizing a denoised training dataset with fewer false positive labels by discarding instances with lower question-relevance scores measured through a false positive detection model. Subsequently, we integrate table-level ranking information into the retriever to assist in finding evidence for questions that demand reasoning across the table. To encode this ranking information, we fine-tune a rank-aware column encoder to identify minimum and maximum values within a column. Experimental results demonstrate that DoTTeR significantly outperforms strong baselines on both retrieval recall and downstream QA tasks. Our code is available at https://github.com/deokhk/DoTTeR.
Autoregressive Score Generation for Multi-trait Essay Scoring
Mar 13, 2024
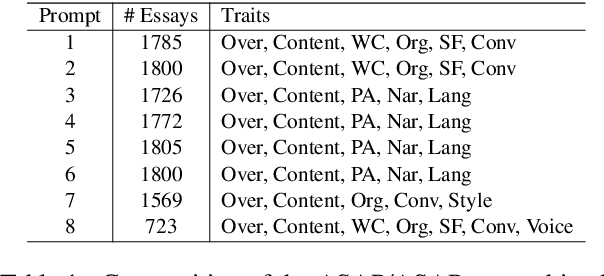

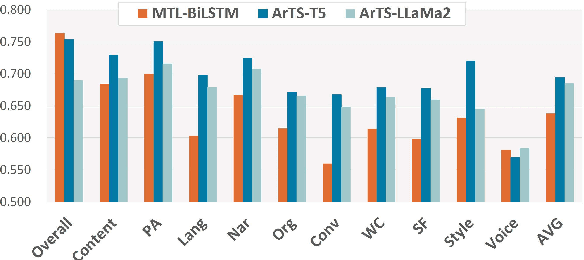
Recently, encoder-only pre-trained models such as BERT have been successfully applied in automated essay scoring (AES) to predict a single overall score. However, studies have yet to explore these models in multi-trait AES, possibly due to the inefficiency of replicating BERT-based models for each trait. Breaking away from the existing sole use of encoder, we propose an autoregressive prediction of multi-trait scores (ArTS), incorporating a decoding process by leveraging the pre-trained T5. Unlike prior regression or classification methods, we redefine AES as a score-generation task, allowing a single model to predict multiple scores. During decoding, the subsequent trait prediction can benefit by conditioning on the preceding trait scores. Experimental results proved the efficacy of ArTS, showing over 5% average improvements in both prompts and traits.
Word-Level ASR Quality Estimation for Efficient Corpus Sampling and Post-Editing through Analyzing Attentions of a Reference-Free Metric
Feb 02, 2024In the realm of automatic speech recognition (ASR), the quest for models that not only perform with high accuracy but also offer transparency in their decision-making processes is crucial. The potential of quality estimation (QE) metrics is introduced and evaluated as a novel tool to enhance explainable artificial intelligence (XAI) in ASR systems. Through experiments and analyses, the capabilities of the NoRefER (No Reference Error Rate) metric are explored in identifying word-level errors to aid post-editors in refining ASR hypotheses. The investigation also extends to the utility of NoRefER in the corpus-building process, demonstrating its effectiveness in augmenting datasets with insightful annotations. The diagnostic aspects of NoRefER are examined, revealing its ability to provide valuable insights into model behaviors and decision patterns. This has proven beneficial for prioritizing hypotheses in post-editing workflows and fine-tuning ASR models. The findings suggest that NoRefER is not merely a tool for error detection but also a comprehensive framework for enhancing ASR systems' transparency, efficiency, and effectiveness. To ensure the reproducibility of the results, all source codes of this study are made publicly available.
Enhancing Zero-Shot Multi-Speaker TTS with Negated Speaker Representations
Jan 04, 2024Zero-shot multi-speaker TTS aims to synthesize speech with the voice of a chosen target speaker without any fine-tuning. Prevailing methods, however, encounter limitations at adapting to new speakers of out-of-domain settings, primarily due to inadequate speaker disentanglement and content leakage. To overcome these constraints, we propose an innovative negation feature learning paradigm that models decoupled speaker attributes as deviations from the complete audio representation by utilizing the subtraction operation. By eliminating superfluous content information from the speaker representation, our negation scheme not only mitigates content leakage, thereby enhancing synthesis robustness, but also improves speaker fidelity. In addition, to facilitate the learning of diverse speaker attributes, we leverage multi-stream Transformers, which retain multiple hypotheses and instigate a training paradigm akin to ensemble learning. To unify these hypotheses and realize the final speaker representation, we employ attention pooling. Finally, in light of the imperative to generate target text utterances in the desired voice, we adopt adaptive layer normalizations to effectively fuse the previously generated speaker representation with the target text representations, as opposed to mere concatenation of the text and audio modalities. Extensive experiments and validations substantiate the efficacy of our proposed approach in preserving and harnessing speaker-specific attributes vis-`a-vis alternative baseline models.
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dec 29, 2023We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.
Optimizing Two-Pass Cross-Lingual Transfer Learning: Phoneme Recognition and Phoneme to Grapheme Translation
Dec 06, 2023This research optimizes two-pass cross-lingual transfer learning in low-resource languages by enhancing phoneme recognition and phoneme-to-grapheme translation models. Our approach optimizes these two stages to improve speech recognition across languages. We optimize phoneme vocabulary coverage by merging phonemes based on shared articulatory characteristics, thus improving recognition accuracy. Additionally, we introduce a global phoneme noise generator for realistic ASR noise during phoneme-to-grapheme training to reduce error propagation. Experiments on the CommonVoice 12.0 dataset show significant reductions in Word Error Rate (WER) for low-resource languages, highlighting the effectiveness of our approach. This research contributes to the advancements of two-pass ASR systems in low-resource languages, offering the potential for improved cross-lingual transfer learning.