 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuntao Ma
USat: A Unified Self-Supervised Encoder for Multi-Sensor Satellite Imagery
Dec 02, 2023
Large, self-supervised vision models have led to substantial advancements for automatically interpreting natural images. Recent works have begun tailoring these methods to remote sensing data which has rich structure with multi-sensor, multi-spectral, and temporal information providing massive amounts of self-labeled data that can be used for self-supervised pre-training. In this work, we develop a new encoder architecture called USat that can input multi-spectral data from multiple sensors for self-supervised pre-training. USat is a vision transformer with modified patch projection layers and positional encodings to model spectral bands with varying spatial scales from multiple sensors. We integrate USat into a Masked Autoencoder (MAE) self-supervised pre-training procedure and find that a pre-trained USat outperforms state-of-the-art self-supervised MAE models trained on remote sensing data on multiple remote sensing benchmark datasets (up to 8%) and leads to improvements in low data regimes (up to 7%). Code and pre-trained weights are available at https://github.com/stanfordmlgroup/USat .
Learning Arm-Assisted Fall Damage Reduction and Recovery for Legged Mobile Manipulators
Mar 09, 2023
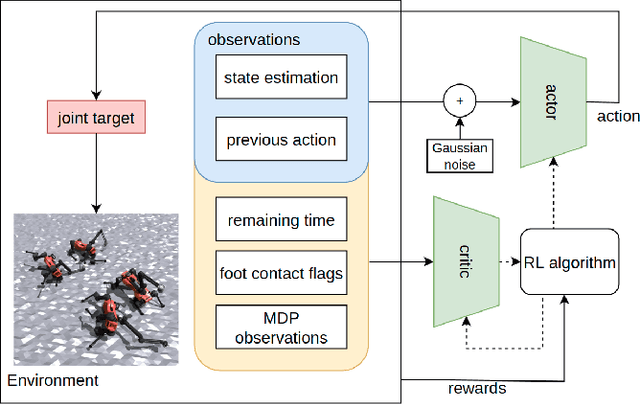

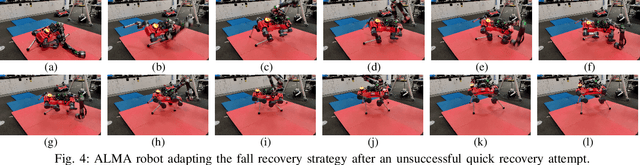
Adaptive falling and recovery skills greatly extend the applicability of robot deployments. In the case of legged mobile manipulators, the robot arm could adaptively stop the fall and assist the recovery. Prior works on falling and recovery strategies for legged mobile manipulators usually rely on assumptions such as inelastic collisions and falling in defined directions to enable real-time computation. This paper presents a learning-based approach to reducing fall damage and recovery. An asymmetric actor-critic training structure is used to train a time-invariant policy with time-varying reward functions. In simulated experiments, the policy recovers from 98.9\% of initial falling configurations. It reduces base contact impulse, peak joint internal forces, and base acceleration during the fall compared to the baseline methods. The trained control policy is deployed and extensively tested on the ALMA robot hardware. A video summarizing the proposed method and the hardware tests is available at https://youtu.be/avwg2HqGi8s.
Combining Learning-based Locomotion Policy with Model-based Manipulation for Legged Mobile Manipulators
Jan 11, 2022
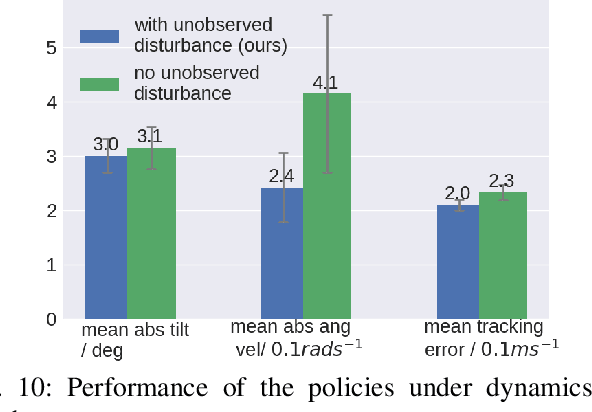
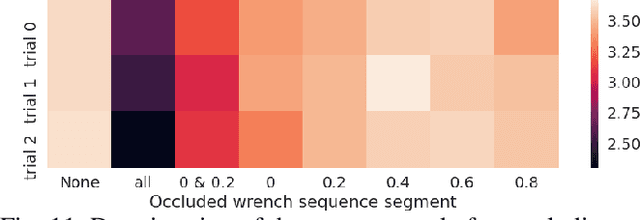
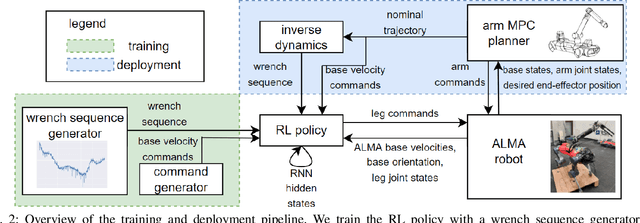
Deep reinforcement learning produces robust locomotion policies for legged robots over challenging terrains. To date, few studies have leveraged model-based methods to combine these locomotion skills with the precise control of manipulators. Here, we incorporate external dynamics plans into learning-based locomotion policies for mobile manipulation. We train the base policy by applying a random wrench sequence on the robot base in simulation and adding the noisified wrench sequence prediction to the policy observations. The policy then learns to counteract the partially-known future disturbance. The random wrench sequences are replaced with the wrench prediction generated with the dynamics plans from model predictive control to enable deployment. We show zero-shot adaptation for manipulators unseen during training. On the hardware, we demonstrate stable locomotion of legged robots with the prediction of the external wrench.
Imitation Learning from MPC for Quadrupedal Multi-Gait Control
Mar 26, 2021
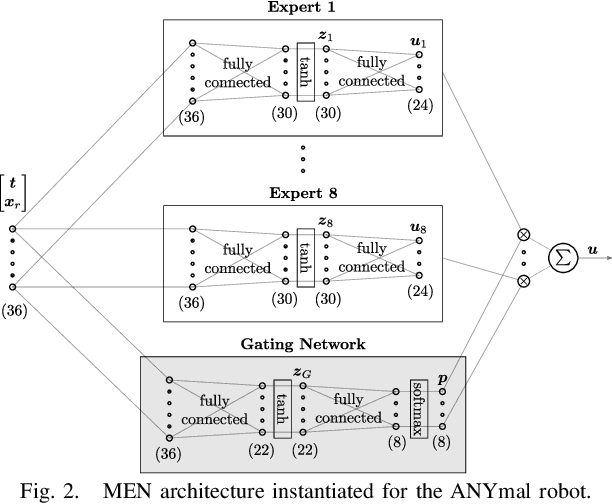
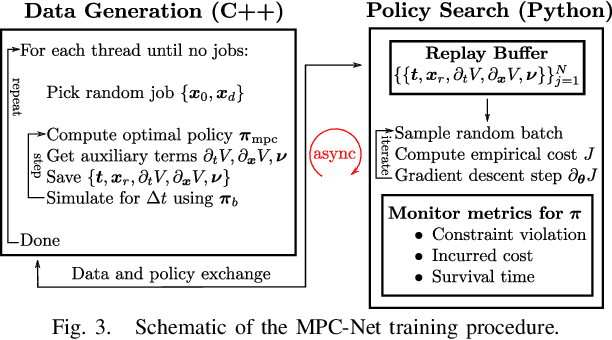
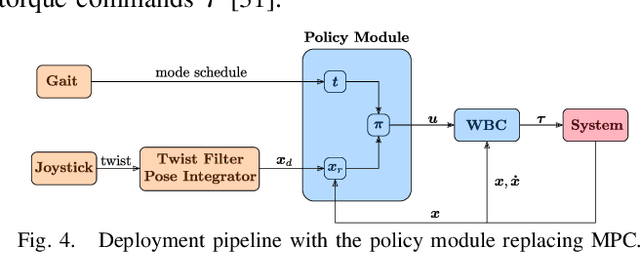
We present a learning algorithm for training a single policy that imitates multiple gaits of a walking robot. To achieve this, we use and extend MPC-Net, which is an Imitation Learning approach guided by Model Predictive Control (MPC). The strategy of MPC-Net differs from many other approaches since its objective is to minimize the control Hamiltonian, which derives from the principle of optimality. To represent the policies, we employ a mixture-of-experts network (MEN) and observe that the performance of a policy improves if each expert of a MEN specializes in controlling exactly one mode of a hybrid system, such as a walking robot. We introduce new loss functions for single- and multi-gait policies to achieve this kind of expert selection behavior. Moreover, we benchmark our algorithm against Behavioral Cloning and the original MPC implementation on various rough terrain scenarios. We validate our approach on hardware and show that a single learned policy can replace its teacher to control multiple gaits.