 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunyao Li
Entity Disambiguation via Fusion Entity Decoding
Apr 02, 2024
Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.
Increasing Coverage and Precision of Textual Information in Multilingual Knowledge Graphs
Nov 27, 2023Recent work in Natural Language Processing and Computer Vision has been using textual information -- e.g., entity names and descriptions -- available in knowledge graphs to ground neural models to high-quality structured data. However, when it comes to non-English languages, the quantity and quality of textual information are comparatively scarce. To address this issue, we introduce the novel task of automatic Knowledge Graph Enhancement (KGE) and perform a thorough investigation on bridging the gap in both the quantity and quality of textual information between English and non-English languages. More specifically, we: i) bring to light the problem of increasing multilingual coverage and precision of entity names and descriptions in Wikidata; ii) demonstrate that state-of-the-art methods, namely, Machine Translation (MT), Web Search (WS), and Large Language Models (LLMs), struggle with this task; iii) present M-NTA, a novel unsupervised approach that combines MT, WS, and LLMs to generate high-quality textual information; and, iv) study the impact of increasing multilingual coverage and precision of non-English textual information in Entity Linking, Knowledge Graph Completion, and Question Answering. As part of our effort towards better multilingual knowledge graphs, we also introduce WikiKGE-10, the first human-curated benchmark to evaluate KGE approaches in 10 languages across 7 language families.
FairytaleCQA: Integrating a Commonsense Knowledge Graph into Children's Storybook Narratives
Nov 16, 2023AI models (including LLM) often rely on narrative question-answering (QA) datasets to provide customized QA functionalities to support downstream children education applications; however, existing datasets only include QA pairs that are grounded within the given storybook content, but children can learn more when teachers refer the storybook content to real-world knowledge (e.g., commonsense knowledge). We introduce the FairytaleCQA dataset, which is annotated by children education experts, to supplement 278 storybook narratives with educationally appropriate commonsense knowledge. The dataset has 5,868 QA pairs that not only originate from the storybook narrative but also contain the commonsense knowledge grounded by an external knowledge graph (i.e., ConceptNet). A follow-up experiment shows that a smaller model (T5-large) fine-tuned with FairytaleCQA reliably outperforms much larger prompt-engineered LLM (e.g., GPT-4) in this new QA-pair generation task (QAG). This result suggests that: 1) our dataset brings novel challenges to existing LLMs, and 2) human experts' data annotation are still critical as they have much nuanced knowledge that LLMs do not know in the children educational domain.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023
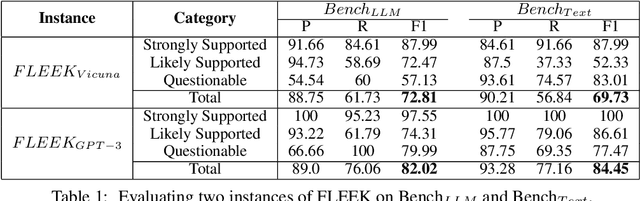
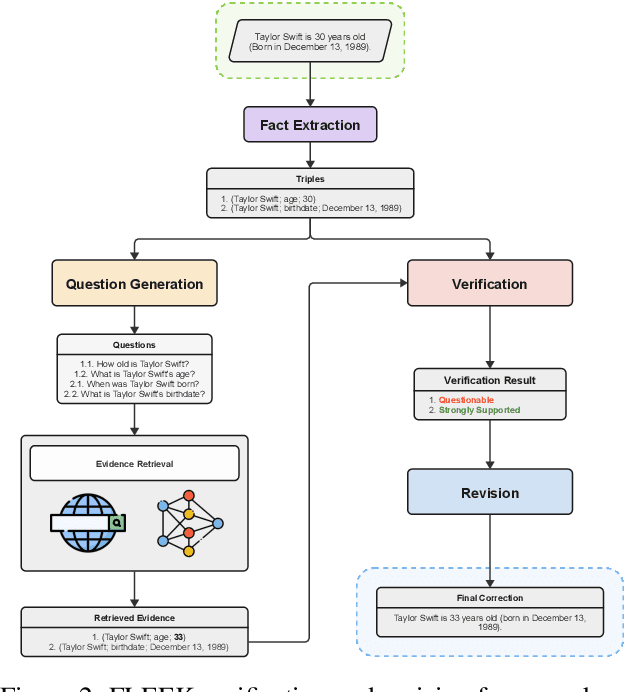
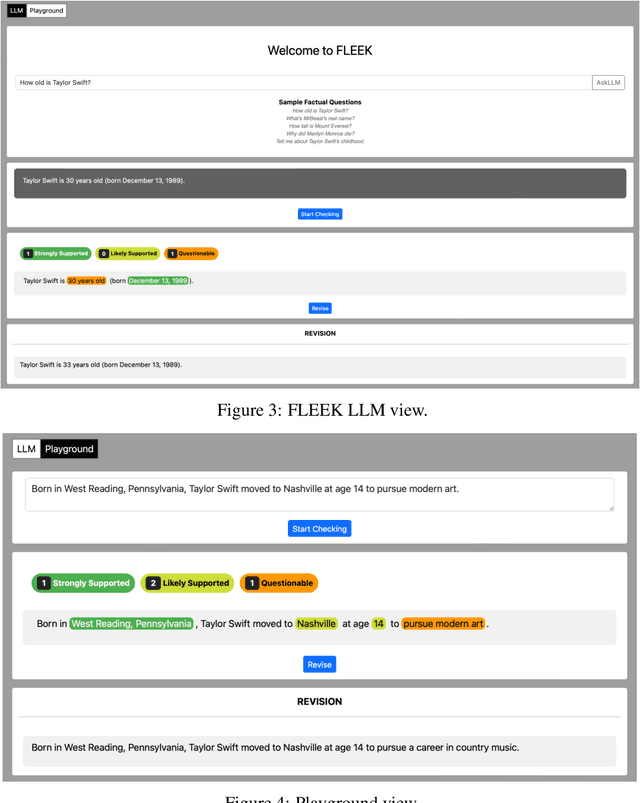
Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.
Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
Sep 20, 2023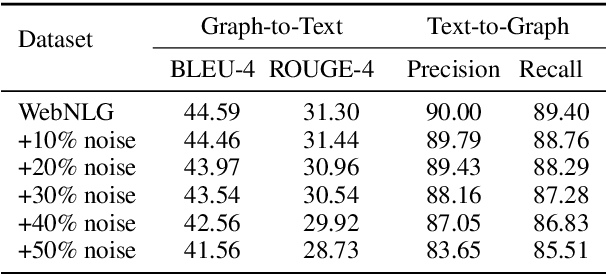
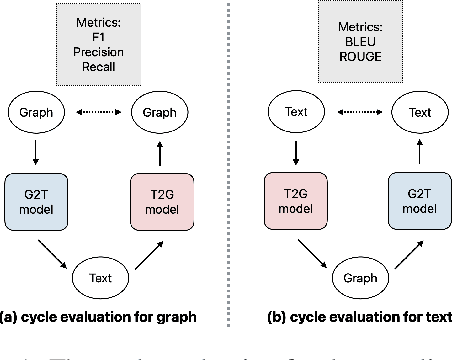

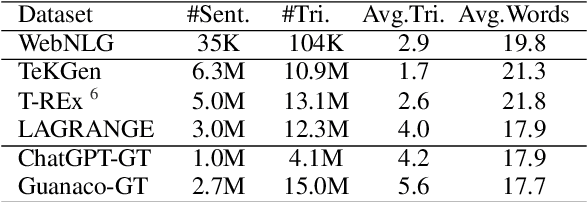
Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.
Growing and Serving Large Open-domain Knowledge Graphs
May 16, 2023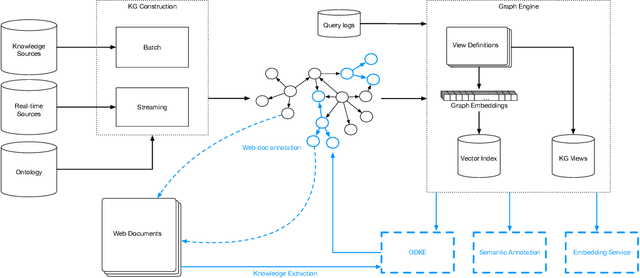
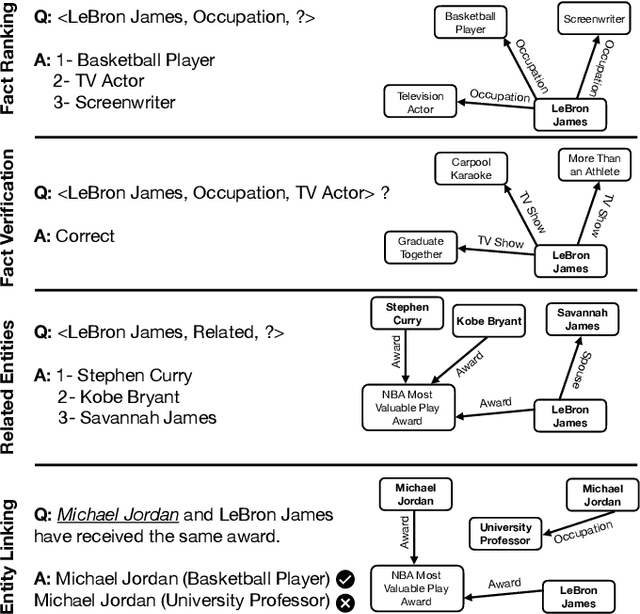
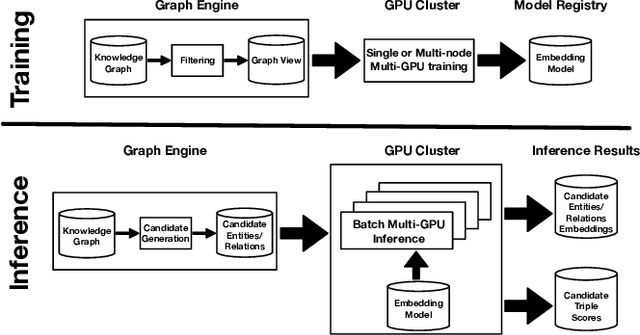
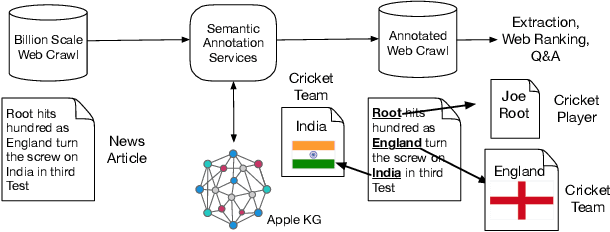
Applications of large open-domain knowledge graphs (KGs) to real-world problems pose many unique challenges. In this paper, we present extensions to Saga our platform for continuous construction and serving of knowledge at scale. In particular, we describe a pipeline for training knowledge graph embeddings that powers key capabilities such as fact ranking, fact verification, a related entities service, and support for entity linking. We then describe how our platform, including graph embeddings, can be leveraged to create a Semantic Annotation service that links unstructured Web documents to entities in our KG. Semantic annotation of the Web effectively expands our knowledge graph with edges to open-domain Web content which can be used in various search and ranking problems. Finally, we leverage annotated Web documents to drive Open-domain Knowledge Extraction. This targeted extraction framework identifies important coverage issues in the KG, then finds relevant data sources for target entities on the Web and extracts missing information to enrich the KG. Finally, we describe adaptations to our knowledge platform needed to construct and serve private personal knowledge on-device. This includes private incremental KG construction, cross-device knowledge sync, and global knowledge enrichment.
When to Use What: An In-Depth Comparative Empirical Analysis of OpenIE Systems for Downstream Applications
Nov 15, 2022



Open Information Extraction (OpenIE) has been used in the pipelines of various NLP tasks. Unfortunately, there is no clear consensus on which models to use in which tasks. Muddying things further is the lack of comparisons that take differing training sets into account. In this paper, we present an application-focused empirical survey of neural OpenIE models, training sets, and benchmarks in an effort to help users choose the most suitable OpenIE systems for their applications. We find that the different assumptions made by different models and datasets have a statistically significant effect on performance, making it important to choose the most appropriate model for one's applications. We demonstrate the applicability of our recommendations on a downstream Complex QA application.
PriMeSRL-Eval: A Practical Quality Metric for Semantic Role Labeling Systems Evaluation
Oct 12, 2022



Semantic role labeling (SRL) identifies the predicate-argument structure in a sentence. This task is usually accomplished in four steps: predicate identification, predicate sense disambiguation, argument identification, and argument classification. Errors introduced at one step propagate to later steps. Unfortunately, the existing SRL evaluation scripts do not consider the full effect of this error propagation aspect. They either evaluate arguments independent of predicate sense (CoNLL09) or do not evaluate predicate sense at all (CoNLL05), yielding an inaccurate SRL model performance on the argument classification task. In this paper, we address key practical issues with existing evaluation scripts and propose a more strict SRL evaluation metric PriMeSRL. We observe that by employing PriMeSRL, the quality evaluation of all SoTA SRL models drops significantly, and their relative rankings also change. We also show that PriMeSRLsuccessfully penalizes actual failures in SoTA SRL models.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022



Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
Domain Representative Keywords Selection: A Probabilistic Approach
Mar 19, 2022



We propose a probabilistic approach to select a subset of a \textit{target domain representative keywords} from a candidate set, contrasting with a context domain. Such a task is crucial for many downstream tasks in natural language processing. To contrast the target domain and the context domain, we adapt the \textit{two-component mixture model} concept to generate a distribution of candidate keywords. It provides more importance to the \textit{distinctive} keywords of the target domain than common keywords contrasting with the context domain. To support the \textit{representativeness} of the selected keywords towards the target domain, we introduce an \textit{optimization algorithm} for selecting the subset from the generated candidate distribution. We have shown that the optimization algorithm can be efficiently implemented with a near-optimal approximation guarantee. Finally, extensive experiments on multiple domains demonstrate the superiority of our approach over other baselines for the tasks of keyword summary generation and trending keywords selection.