 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuqing Yang
Position Engineering: Boosting Large Language Models through Positional Information Manipulation
Apr 17, 2024
The performance of large language models (LLMs) is significantly influenced by the quality of the prompts provided. In response, researchers have developed enormous prompt engineering strategies aimed at modifying the prompt text to enhance task performance. In this paper, we introduce a novel technique termed position engineering, which offers a more efficient way to guide large language models. Unlike prompt engineering, which requires substantial effort to modify the text provided to LLMs, position engineering merely involves altering the positional information in the prompt without modifying the text itself. We have evaluated position engineering in two widely-used LLM scenarios: retrieval-augmented generation (RAG) and in-context learning (ICL). Our findings show that position engineering substantially improves upon the baseline in both cases. Position engineering thus represents a promising new strategy for exploiting the capabilities of large language models.
LLM-ABR: Designing Adaptive Bitrate Algorithms via Large Language Models
Apr 02, 2024We present LLM-ABR, the first system that utilizes the generative capabilities of large language models (LLMs) to autonomously design adaptive bitrate (ABR) algorithms tailored for diverse network characteristics. Operating within a reinforcement learning framework, LLM-ABR empowers LLMs to design key components such as states and neural network architectures. We evaluate LLM-ABR across diverse network settings, including broadband, satellite, 4G, and 5G. LLM-ABR consistently outperforms default ABR algorithms.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Mar 19, 2024
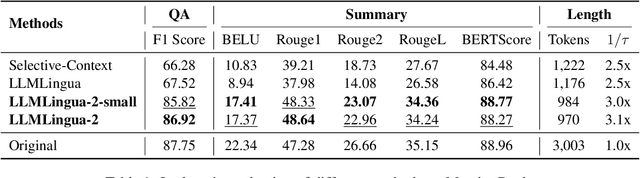

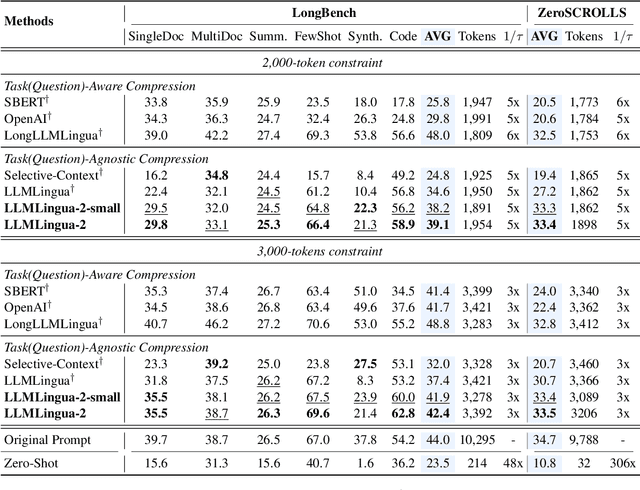
This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
Automated Contrastive Learning Strategy Search for Time Series
Mar 19, 2024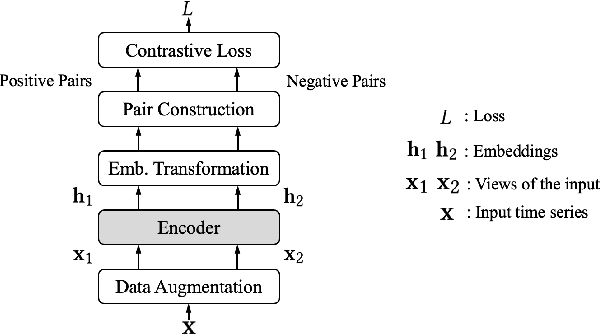
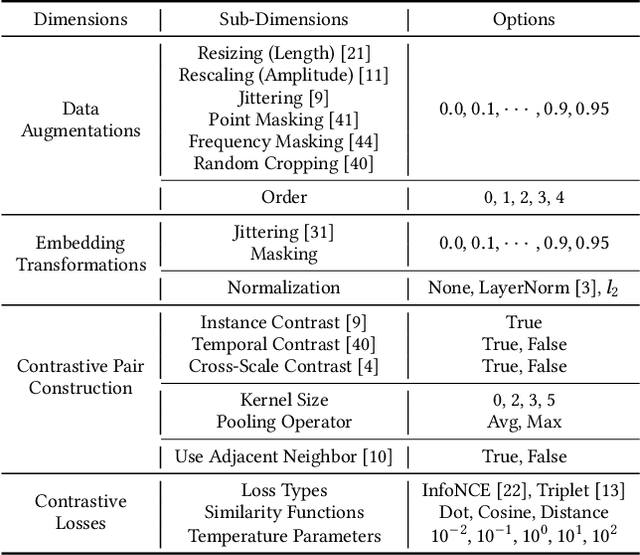
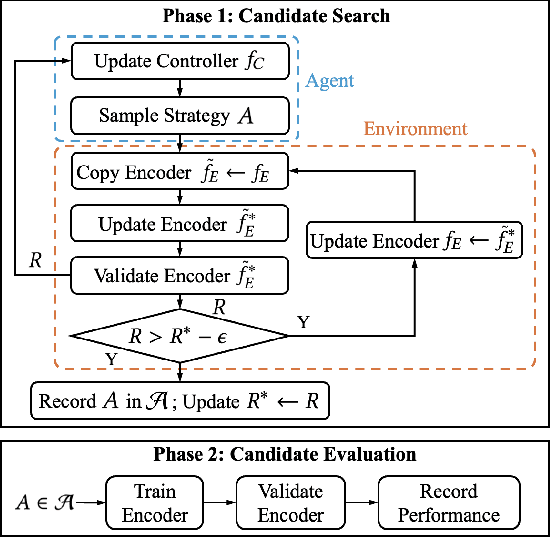
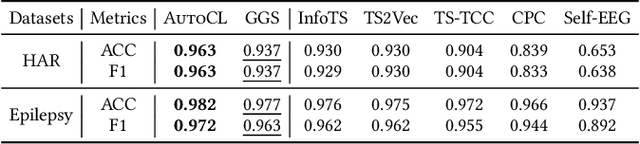
In recent years, Contrastive Learning (CL) has become a predominant representation learning paradigm for time series. Most existing methods in the literature focus on manually building specific Contrastive Learning Strategies (CLS) by human heuristics for certain datasets and tasks. However, manually developing CLS usually require excessive prior knowledge about the datasets and tasks, e.g., professional cognition of the medical time series in healthcare, as well as huge human labor and massive experiments to determine the detailed learning configurations. In this paper, we present an Automated Machine Learning (AutoML) practice at Microsoft, which automatically learns to contrastively learn representations for various time series datasets and tasks, namely Automated Contrastive Learning (AutoCL). We first construct a principled universal search space of size over 3x1012, covering data augmentation, embedding transformation, contrastive pair construction and contrastive losses. Further, we introduce an efficient reinforcement learning algorithm, which optimizes CLS from the performance on the validation tasks, to obtain more effective CLS within the space. Experimental results on various real-world tasks and datasets demonstrate that AutoCL could automatically find the suitable CLS for a given dataset and task. From the candidate CLS found by AutoCL on several public datasets/tasks, we compose a transferable Generally Good Strategy (GGS), which has a strong performance for other datasets. We also provide empirical analysis as a guidance for future design of CLS.
Benchmarking Data Science Agents
Feb 27, 2024In the era of data-driven decision-making, the complexity of data analysis necessitates advanced expertise and tools of data science, presenting significant challenges even for specialists. Large Language Models (LLMs) have emerged as promising aids as data science agents, assisting humans in data analysis and processing. Yet their practical efficacy remains constrained by the varied demands of real-world applications and complicated analytical process. In this paper, we introduce DSEval -- a novel evaluation paradigm, as well as a series of innovative benchmarks tailored for assessing the performance of these agents throughout the entire data science lifecycle. Incorporating a novel bootstrapped annotation method, we streamline dataset preparation, improve the evaluation coverage, and expand benchmarking comprehensiveness. Our findings uncover prevalent obstacles and provide critical insights to inform future advancements in the field.
On the Out-Of-Distribution Generalization of Multimodal Large Language Models
Feb 09, 2024We investigate the generalization boundaries of current Multimodal Large Language Models (MLLMs) via comprehensive evaluation under out-of-distribution scenarios and domain-specific tasks. We evaluate their zero-shot generalization across synthetic images, real-world distributional shifts, and specialized datasets like medical and molecular imagery. Empirical results indicate that MLLMs struggle with generalization beyond common training domains, limiting their direct application without adaptation. To understand the cause of unreliable performance, we analyze three hypotheses: semantic misinterpretation, visual feature extraction insufficiency, and mapping deficiency. Results identify mapping deficiency as the primary hurdle. To address this problem, we show that in-context learning (ICL) can significantly enhance MLLMs' generalization, opening new avenues for overcoming generalization barriers. We further explore the robustness of ICL under distribution shifts and show its vulnerability to domain shifts, label shifts, and spurious correlation shifts between in-context examples and test data.
Alignment for Honesty
Dec 12, 2023Recent research has made significant strides in applying alignment techniques to enhance the helpfulness and harmlessness of large language models (LLMs) in accordance with human intentions. In this paper, we argue for the importance of alignment for honesty, ensuring that LLMs proactively refuse to answer questions when they lack knowledge, while still not being overly conservative. However, a pivotal aspect of alignment for honesty involves discerning the limits of an LLM's knowledge, which is far from straightforward. This challenge demands comprehensive solutions in terms of metric development, benchmark creation, and training methodologies. In this paper, we address these challenges by first establishing a precise problem definition and defining ``honesty'' inspired by the Analects of Confucius. This serves as a cornerstone for developing metrics that effectively measure an LLM's honesty by quantifying its progress post-alignment. Furthermore, we introduce a flexible training framework which is further instantiated by several efficient fine-tuning techniques that emphasize honesty without sacrificing performance on other tasks. Our extensive experiments reveal that these aligned models show a marked increase in honesty, as indicated by our proposed metrics. We open-source a wealth of resources to facilitate future research at https://github.com/GAIR-NLP/alignment-for-honesty, including honesty-aligned models, training and evaluation datasets for honesty alignment, concept glossary, as well as all relevant source code.
CoLLiE: Collaborative Training of Large Language Models in an Efficient Way
Dec 01, 2023Large language models (LLMs) are increasingly pivotal in a wide range of natural language processing tasks. Access to pre-trained models, courtesy of the open-source community, has made it possible to adapt these models to specific applications for enhanced performance. However, the substantial resources required for training these models necessitate efficient solutions. This paper introduces CoLLiE, an efficient library that facilitates collaborative training of large language models using 3D parallelism, parameter-efficient fine-tuning (PEFT) methods, and optimizers such as Lion, Adan, Sophia, LOMO and AdaLomo. With its modular design and comprehensive functionality, CoLLiE offers a balanced blend of efficiency, ease of use, and customization. CoLLiE has proven superior training efficiency in comparison with prevalent solutions in pre-training and fine-tuning scenarios. Furthermore, we provide an empirical evaluation of the correlation between model size and GPU memory consumption under different optimization methods, as well as an analysis of the throughput. Lastly, we carry out a comprehensive comparison of various optimizers and PEFT methods within the instruction-tuning context. CoLLiE is available at https://github.com/OpenLMLab/collie.
Unified Medical Image Pre-training in Language-Guided Common Semantic Space
Nov 24, 2023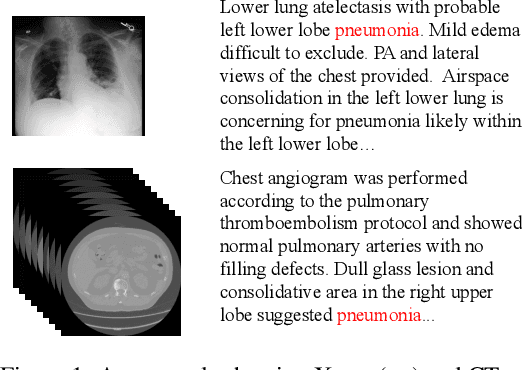
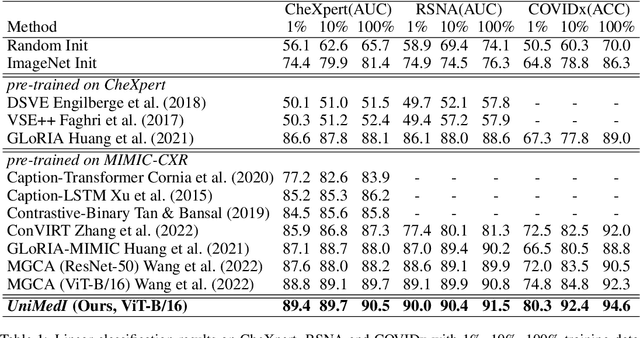
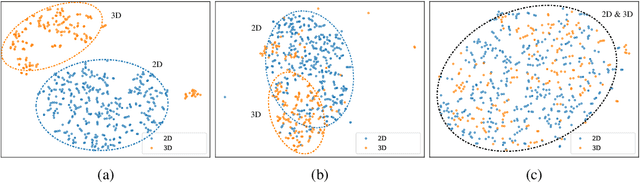
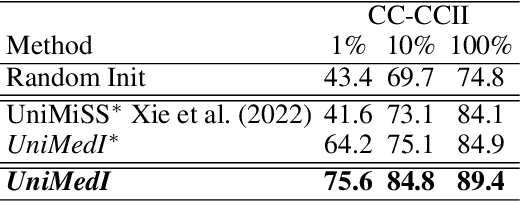
Vision-Language Pre-training (VLP) has shown the merits of analysing medical images, by leveraging the semantic congruence between medical images and their corresponding reports. It efficiently learns visual representations, which in turn facilitates enhanced analysis and interpretation of intricate imaging data. However, such observation is predominantly justified on single-modality data (mostly 2D images like X-rays), adapting VLP to learning unified representations for medical images in real scenario remains an open challenge. This arises from medical images often encompass a variety of modalities, especially modalities with different various number of dimensions (e.g., 3D images like Computed Tomography). To overcome the aforementioned challenges, we propose an Unified Medical Image Pre-training framework, namely UniMedI, which utilizes diagnostic reports as common semantic space to create unified representations for diverse modalities of medical images (especially for 2D and 3D images). Under the text's guidance, we effectively uncover visual modality information, identifying the affected areas in 2D X-rays and slices containing lesion in sophisticated 3D CT scans, ultimately enhancing the consistency across various medical imaging modalities. To demonstrate the effectiveness and versatility of UniMedI, we evaluate its performance on both 2D and 3D images across 10 different datasets, covering a wide range of medical image tasks such as classification, segmentation, and retrieval. UniMedI has demonstrated superior performance in downstream tasks, showcasing its effectiveness in establishing a universal medical visual representation.
Plan, Verify and Switch: Integrated Reasoning with Diverse X-of-Thoughts
Oct 23, 2023As large language models (LLMs) have shown effectiveness with different prompting methods, such as Chain of Thought, Program of Thought, we find that these methods have formed a great complementarity to each other on math reasoning tasks. In this work, we propose XoT, an integrated problem solving framework by prompting LLMs with diverse reasoning thoughts. For each question, XoT always begins with selecting the most suitable method then executes each method iteratively. Within each iteration, XoT actively checks the validity of the generated answer and incorporates the feedback from external executors, allowing it to dynamically switch among different prompting methods. Through extensive experiments on 10 popular math reasoning datasets, we demonstrate the effectiveness of our proposed approach and thoroughly analyze the strengths of each module. Moreover, empirical results suggest that our framework is orthogonal to recent work that makes improvements on single reasoning methods and can further generalise to logical reasoning domain. By allowing method switching, XoT provides a fresh perspective on the collaborative integration of diverse reasoning thoughts in a unified framework.