 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYusen Zhan
Theoretically-Grounded Policy Advice from Multiple Teachers in Reinforcement Learning Settings with Applications to Negative Transfer
Apr 13, 2016
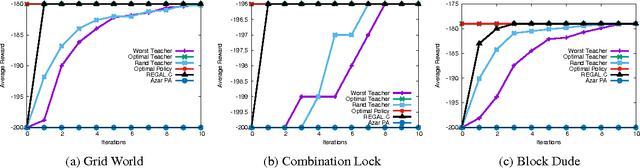
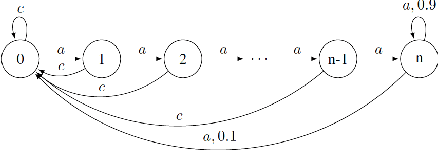
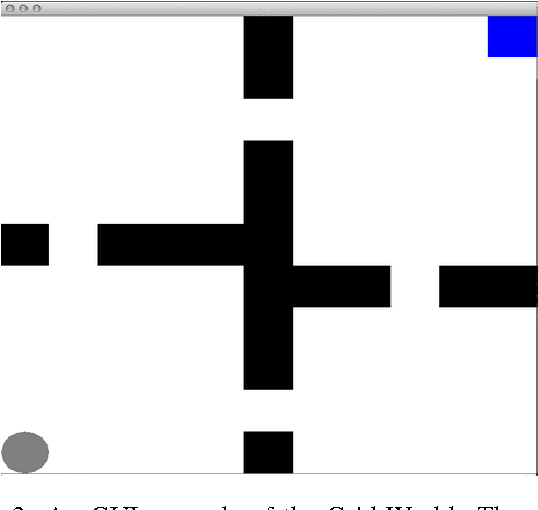

Policy advice is a transfer learning method where a student agent is able to learn faster via advice from a teacher. However, both this and other reinforcement learning transfer methods have little theoretical analysis. This paper formally defines a setting where multiple teacher agents can provide advice to a student and introduces an algorithm to leverage both autonomous exploration and teacher's advice. Our regret bounds justify the intuition that good teachers help while bad teachers hurt. Using our formalization, we are also able to quantify, for the first time, when negative transfer can occur within such a reinforcement learning setting.
Online Transfer Learning in Reinforcement Learning Domains
Jul 15, 2015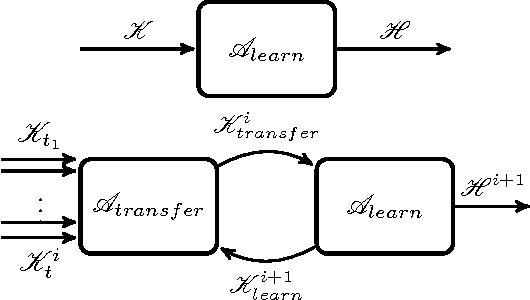
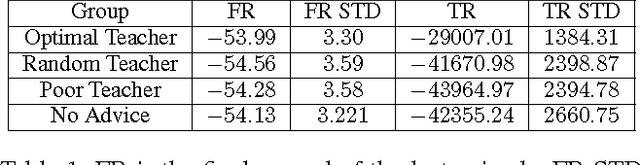
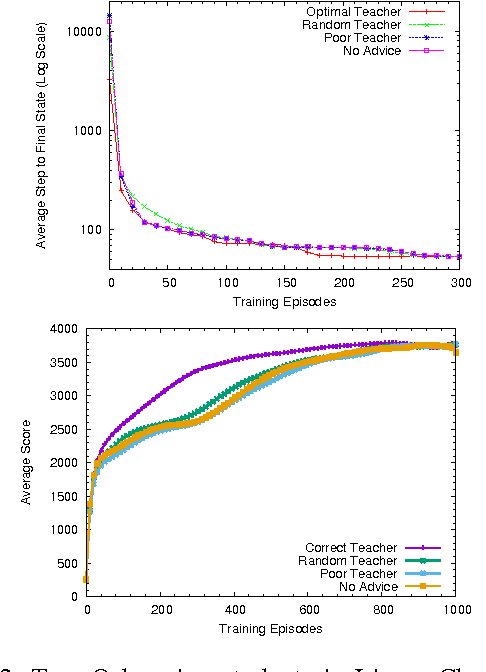
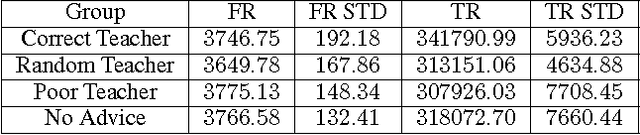
This paper proposes an online transfer framework to capture the interaction among agents and shows that current transfer learning in reinforcement learning is a special case of online transfer. Furthermore, this paper re-characterizes existing agents-teaching-agents methods as online transfer and analyze one such teaching method in three ways. First, the convergence of Q-learning and Sarsa with tabular representation with a finite budget is proven. Second, the convergence of Q-learning and Sarsa with linear function approximation is established. Third, the we show the asymptotic performance cannot be hurt through teaching. Additionally, all theoretical results are empirically validated.