 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuu Jinnai
Regularized Best-of-N Sampling to Mitigate Reward Hacking for Language Model Alignment
Apr 05, 2024
Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) to human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Because the reward model is an imperfect proxy for the true objective, over-optimizing its value can compromise its performance on the true objective. A common solution to prevent reward hacking in preference learning techniques is to optimize a reward using proximity regularization (e.g., KL regularization), which ensures that the language model remains close to the reference model. In this research, we propose Regularized Best-of-N (RBoN), a variant of BoN that aims to mitigate reward hacking by incorporating a proximity term in response selection, similar to preference learning techniques. We evaluate two variants of RBoN on the AlpacaFarm dataset and find that they outperform BoN, especially when the proxy reward model has a low correlation with the true objective.
On the True Distribution Approximation of Minimum Bayes-Risk Decoding
Mar 31, 2024Minimum Bayes-risk (MBR) decoding has recently gained renewed attention in text generation. MBR decoding considers texts sampled from a model as pseudo-references and selects the text with the highest similarity to the others. Therefore, sampling is one of the key elements of MBR decoding, and previous studies reported that the performance varies by sampling methods. From a theoretical standpoint, this performance variation is likely tied to how closely the samples approximate the true distribution of references. However, this approximation has not been the subject of in-depth study. In this study, we propose using anomaly detection to measure the degree of approximation. We first closely examine the performance variation and then show that previous hypotheses about samples do not correlate well with the variation, but our introduced anomaly scores do. The results are the first to empirically support the link between the performance and the core assumption of MBR decoding.
Generating Diverse and High-Quality Texts by Minimum Bayes Risk Decoding
Jan 10, 2024One of the most important challenges in text generation systems is to produce outputs that are not only correct but also diverse. Recently, Minimum Bayes-Risk (MBR) decoding has gained prominence for generating sentences of the highest quality among the decoding algorithms. However, existing algorithms proposed for generating diverse outputs are predominantly based on beam search or random sampling, thus their output quality is capped by these underlying methods. In this paper, we investigate an alternative approach -- we develop diversity-promoting decoding algorithms by enforcing diversity objectives to MBR decoding. We propose two variants of MBR, Diverse MBR (DMBR) and $k$-medoids MBR (KMBR), methods to generate a set of sentences with high quality and diversity. We evaluate DMBR and KMBR on a variety of directed text generation tasks using encoder-decoder models and a large language model with prompting. The experimental results show that the proposed method achieves a better trade-off than the diverse beam search and sampling algorithms.
Hyperparameter-Free Approach for Faster Minimum Bayes Risk Decoding
Jan 05, 2024Minimum Bayes-Risk (MBR) decoding is shown to be a powerful alternative to beam search decoding for a wide range of text generation tasks. However, MBR requires a huge amount of time for inference to compute the MBR objective, which makes the method infeasible in many situations where response time is critical. Confidence-based pruning (CBP) (Cheng and Vlachos, 2023) has recently been proposed to reduce the inference time in machine translation tasks. Although it is shown to significantly reduce the amount of computation, it requires hyperparameter tuning using a development set to be effective. To this end, we propose Approximate Minimum Bayes-Risk (AMBR) decoding, a hyperparameter-free method to run MBR decoding approximately. AMBR is derived from the observation that the problem of computing the sample-based MBR objective is the medoid identification problem. AMBR uses the Correlated Sequential Halving (CSH) algorithm (Baharav and Tse, 2019), the best approximation algorithm to date for the medoid identification problem, to compute the sample-based MBR objective. We evaluate AMBR on machine translation, text summarization, and image captioning tasks. The results show that AMBR achieves on par with CBP, with CBP selecting hyperparameters through an Oracle for each given computation budget.
Model-Based Minimum Bayes Risk Decoding
Nov 09, 2023Minimum Bayes Risk (MBR) decoding has been shown to be a powerful alternative to beam search decoding in a variety of text generation tasks. MBR decoding selects a hypothesis from a pool of hypotheses that has the least expected risk under a probability model according to a given utility function. Since it is impractical to compute the expected risk exactly over all possible hypotheses, two approximations are commonly used in MBR. First, it integrates over a sampled set of hypotheses rather than over all possible hypotheses. Second, it estimates the probability of each hypothesis using a Monte Carlo estimator. While the first approximation is necessary to make it computationally feasible, the second is not essential since we typically have access to the model probability at inference time. We propose Model-Based MBR (MBMBR), a variant of MBR that uses the model probability itself as the estimate of the probability distribution instead of the Monte Carlo estimate. We show analytically and empirically that the model-based estimate is more promising than the Monte Carlo estimate in text generation tasks. Our experiments show that MBMBR outperforms MBR in several text generation tasks, both with encoder-decoder models and with large language models.
On the Depth between Beam Search and Exhaustive Search for Text Generation
Aug 25, 2023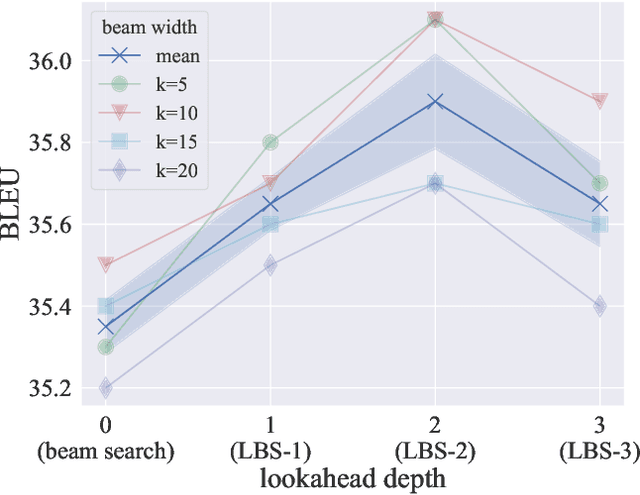



Beam search and exhaustive search are two extreme ends of text decoding algorithms with respect to the search depth. Beam search is limited in both search width and depth, whereas exhaustive search is a global search that has no such limitations. Surprisingly, beam search is not only computationally cheaper but also performs better than exhaustive search despite its higher search error. Plenty of research has investigated a range of beam widths, from small to large, and reported that a beam width that is neither too large nor too small is desirable. However, in terms of search depth, only the two extreme ends, beam search and exhaustive search are studied intensively. In this paper, we examine a range of search depths between the two extremes to discover the desirable search depth. To this end, we introduce Lookahead Beam Search (LBS), a multi-step lookahead search that optimizes the objective considering a fixed number of future steps. Beam search and exhaustive search are special cases of LBS where the lookahead depth is set to $0$ and $\infty$, respectively. We empirically evaluate the performance of LBS and find that it outperforms beam search overall on machine translation tasks. The result suggests there is room for improvement in beam search by searching deeper. Inspired by the analysis, we propose Lookbehind Heuristic Beam Search, a computationally feasible search algorithm that heuristically simulates LBS with 1-step lookahead. The empirical results show that the proposed method outperforms vanilla beam search on machine translation and text summarization tasks.
Blind Signal Separation for Fast Ultrasound Computed Tomography
Apr 27, 2023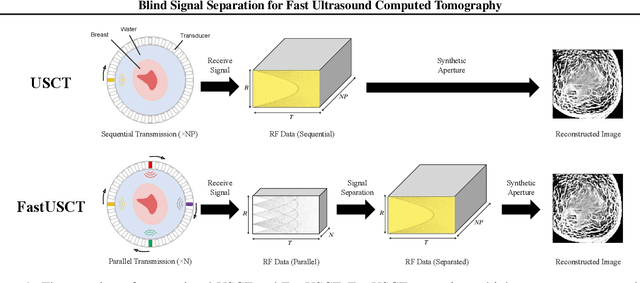

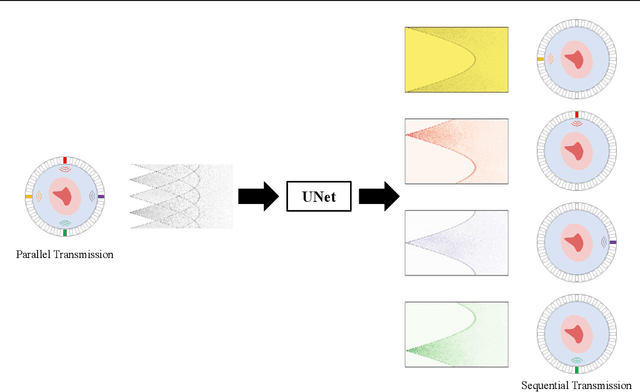
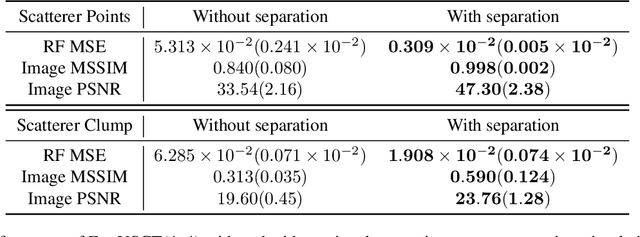
Breast cancer is the most prevalent cancer with a high mortality rate in women over the age of 40. Many studies have shown that the detection of cancer at earlier stages significantly reduces patients' mortality and morbidity rages. Ultrasound computer tomography (USCT) is considered as a promising screening tool for diagnosing early-stage breast cancer as it is cost-effective and produces 3D images without radiation exposure. However, USCT is not a popular choice mainly due to its prolonged imaging time. USCT is time-consuming because it needs to transmit a number of ultrasound waves and record them one by one to acquire a high-quality image. We propose FastUSCT, a method to acquire a high-quality image faster than traditional methods for USCT. FastUSCT consists of three steps. First, it transmits multiple ultrasound waves at the same time to reduce the imaging time. Second, it separates the overlapping waves recorded by the receiving elements into each wave with UNet. Finally, it reconstructs an ultrasound image with a synthetic aperture method using the separated waves. We evaluated FastUSCT on simulation on breast digital phantoms. We trained the UNet on simulation using natural images and transferred the model for the breast digital phantoms. The empirical result shows that FastUSCT significantly improves the quality of the image under the same imaging time to the conventional USCT method, especially when the imaging time is limited.
Lipschitz Lifelong Reinforcement Learning
Jan 17, 2020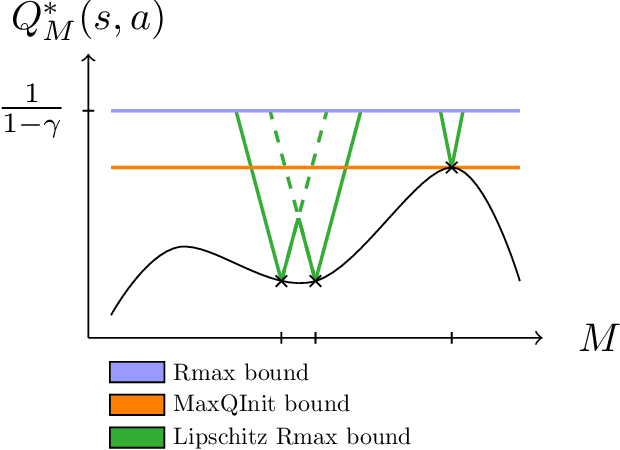
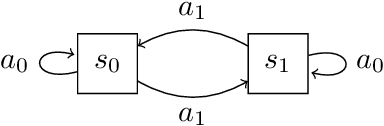

We consider the problem of knowledge transfer when an agent is facing a series of Reinforcement Learning (RL) tasks. We introduce a novel metric between Markov Decision Processes and establish that close MDPs have close optimal value functions. Formally, the optimal value functions are Lipschitz continuous with respect to the tasks space. These theoretical results lead us to a value transfer method for Lifelong RL, which we use to build a PAC-MDP algorithm with improved convergence rate. We illustrate the benefits of the method in Lifelong RL experiments.
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
Mar 26, 2019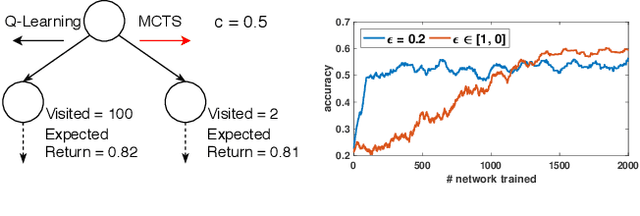
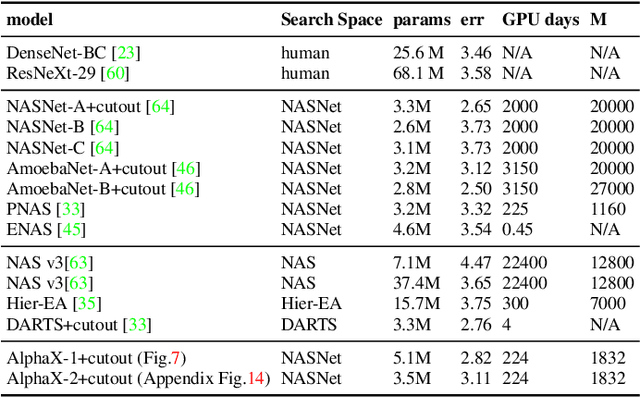
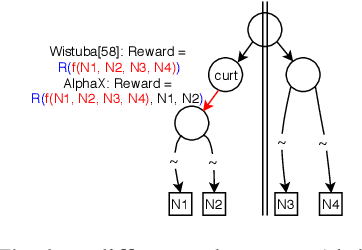
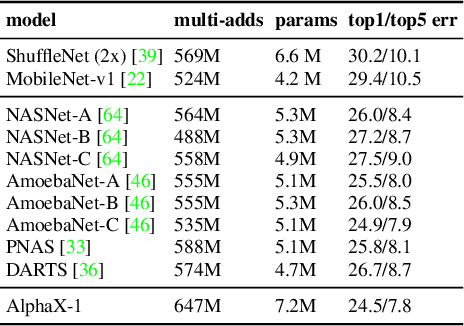
We present AlphaX, a fully automated agent that designs complex neural architectures from scratch. AlphaX explores the exponentially grown search space with a distributed Monte Carlo Tree Search (MCTS) and a Meta-Deep Neural Network (DNN). MCTS intrinsically improves the search efficiency by dynamically balancing the exploration and exploitation at fine-grained states, while Meta-DNN predicts the network accuracy to guide the search, and to provide an estimated reward to speed up the rollout. As the search progresses, AlphaX also generates the training data for Meta-DNN. So, the learning of Meta-DNN is end-to-end. In 14 days with only 16 GPUs (1832 samples), AlphaX found an architecture that reaches the state-of-the-art accuracies on both CIFAR-10(97.18%) and ImageNet(75.5% top-1 and 92.2% top-5). This demonstrates up to 10x speedup over the original searching for NASNet that used 500 GPUs in 4 days (20000 samples). On NASBench-101, AlphaX demonstrates 3x and 2.8x speedup over Random Search and Regularized Evolution. Finally, we show the searched architecture improves a variety of vision applications from Neural Style Transfer, to Image Captioning and Object Detection. Our implementation is available at https://github.com/linnanwang/AlphaX-NASBench101.
Discovering Options for Exploration by Minimizing Cover Time
Mar 16, 2019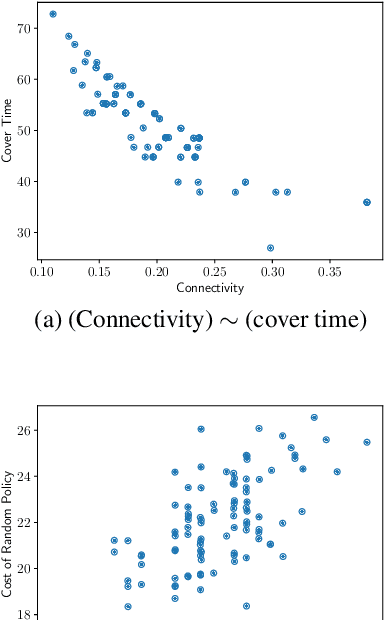
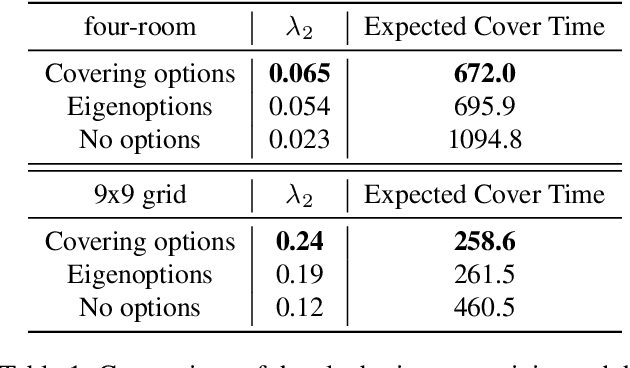
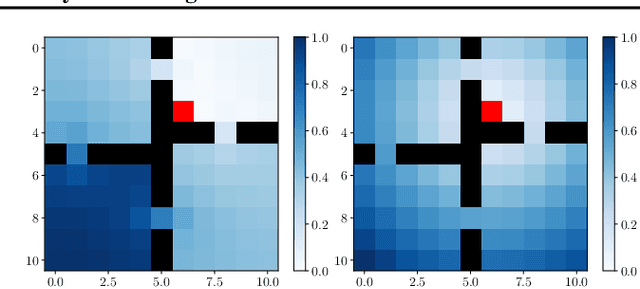
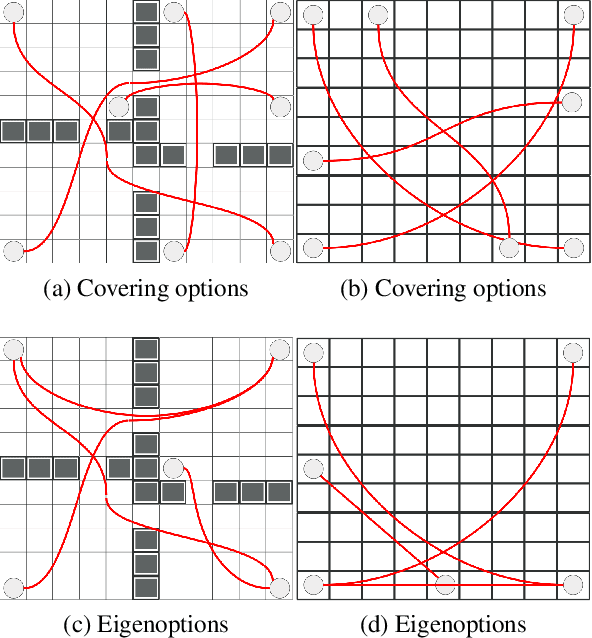
One of the main challenges in reinforcement learning is solving tasks with sparse reward. We show that the difficulty of discovering a distant rewarding state in an MDP is bounded by the expected cover time of a random walk over the graph induced by the MDP's transition dynamics. We therefore propose to accelerate exploration by constructing options that minimize cover time. The proposed algorithm finds an option which provably diminishes the expected number of steps to visit every state in the state space by a uniform random walk. We show empirically that the proposed algorithm improves the learning time in several domains with sparse rewards.