 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuya Sasaki
Evaluating Fairness Metrics Across Borders from Human Perceptions
Mar 24, 2024
Which fairness metrics are appropriately applicable in your contexts? There may be instances of discordance regarding the perception of fairness, even when the outcomes comply with established fairness metrics. Several surveys have been conducted to evaluate fairness metrics with human perceptions of fairness. However, these surveys were limited in scope, including only a few hundred participants within a single country. In this study, we conduct an international survey to evaluate the appropriateness of various fairness metrics in decision-making scenarios. We collected responses from 1,000 participants in each of China, France, Japan, and the United States, amassing a total of 4,000 responses, to analyze the preferences of fairness metrics. Our survey consists of three distinct scenarios paired with four fairness metrics, and each participant answers their preference for the fairness metric in each case. This investigation explores the relationship between personal attributes and the choice of fairness metrics, uncovering a significant influence of national context on these preferences.
High-Dimensional Tail Index Regression: with An Application to Text Analyses of Viral Posts in Social Media
Mar 02, 2024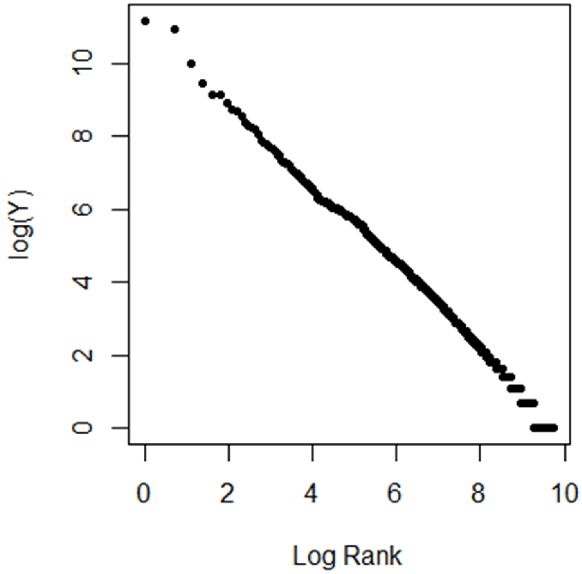

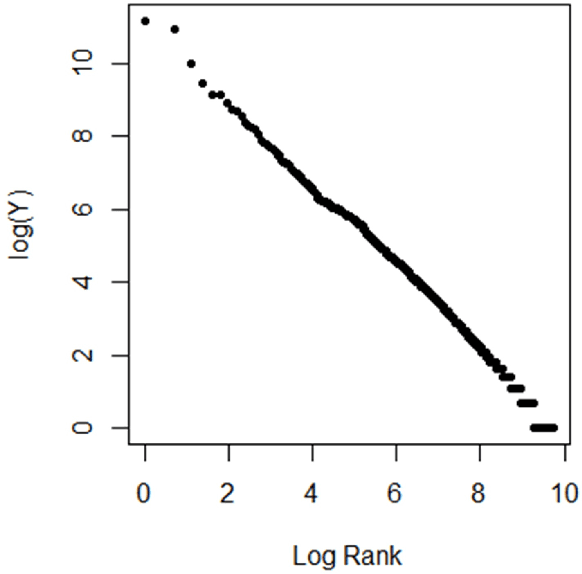
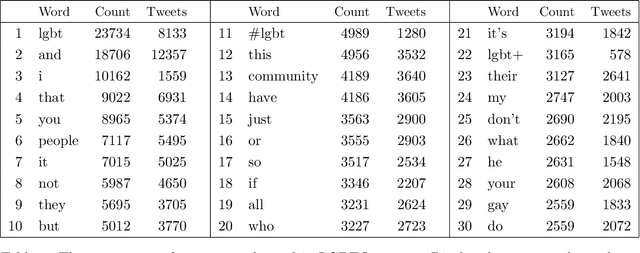
Motivated by the empirical power law of the distributions of credits (e.g., the number of "likes") of viral posts in social media, we introduce the high-dimensional tail index regression and methods of estimation and inference for its parameters. We propose a regularized estimator, establish its consistency, and derive its convergence rate. To conduct inference, we propose to debias the regularized estimate, and establish the asymptotic normality of the debiased estimator. Simulation studies support our theory. These methods are applied to text analyses of viral posts in X (formerly Twitter) concerning LGBTQ+.
Efficient and Explainable Graph Neural Architecture Search via Monte-Carlo Tree Search
Sep 01, 2023



Graph neural networks (GNNs) are powerful tools for performing data science tasks in various domains. Although we use GNNs in wide application scenarios, it is a laborious task for researchers and practitioners to design/select optimal GNN architectures in diverse graphs. To save human efforts and computational costs, graph neural architecture search (Graph NAS) has been used to search for a sub-optimal GNN architecture that combines existing components. However, there are no existing Graph NAS methods that satisfy explainability, efficiency, and adaptability to various graphs. Therefore, we propose an efficient and explainable Graph NAS method, called ExGNAS, which consists of (i) a simple search space that can adapt to various graphs and (ii) a search algorithm that makes the decision process explainable. The search space includes only fundamental functions that can handle homophilic and heterophilic graphs. The search algorithm efficiently searches for the best GNN architecture via Monte-Carlo tree search without neural models. The combination of our search space and algorithm achieves finding accurate GNN models and the important functions within the search space. We comprehensively evaluate our method compared with twelve hand-crafted GNN architectures and three Graph NAS methods in four graphs. Our experimental results show that ExGNAS increases AUC up to 3.6 and reduces run time up to 78\% compared with the state-of-the-art Graph NAS methods. Furthermore, we show ExGNAS is effective in analyzing the difference between GNN architectures in homophilic and heterophilic graphs.
Learned spatial data partitioning
Jun 19, 2023
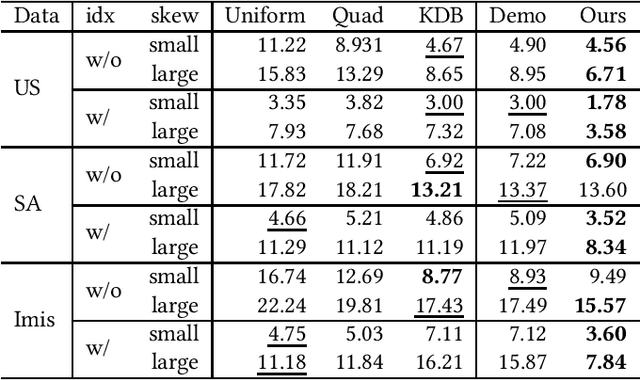

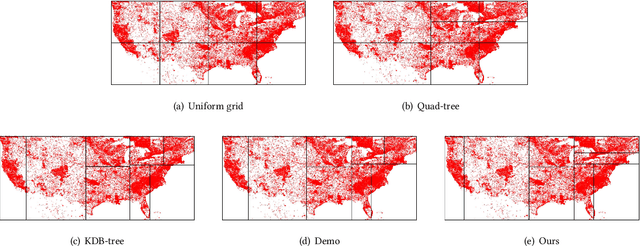
Due to the significant increase in the size of spatial data, it is essential to use distributed parallel processing systems to efficiently analyze spatial data. In this paper, we first study learned spatial data partitioning, which effectively assigns groups of big spatial data to computers based on locations of data by using machine learning techniques. We formalize spatial data partitioning in the context of reinforcement learning and develop a novel deep reinforcement learning algorithm. Our learning algorithm leverages features of spatial data partitioning and prunes ineffective learning processes to find optimal partitions efficiently. Our experimental study, which uses Apache Sedona and real-world spatial data, demonstrates that our method efficiently finds partitions for accelerating distance join queries and reduces the workload run time by up to 59.4%.
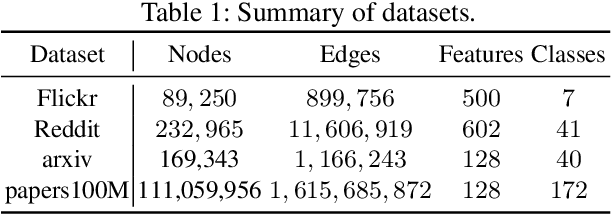
Why Using Either Aggregated Features or Adjacency Lists in Directed or Undirected Graph? Empirical Study and Simple Classification Method
Jun 14, 2023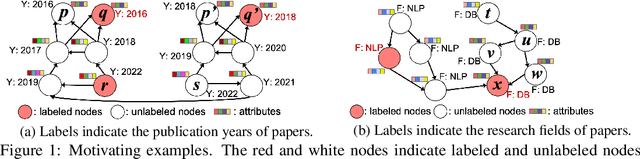
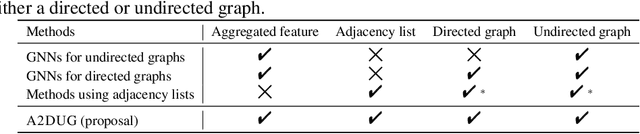
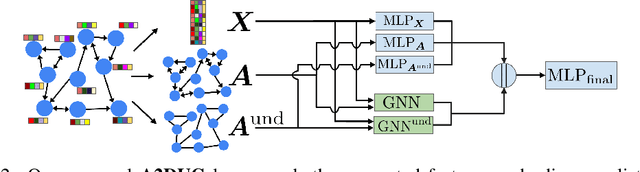

Node classification is one of the hottest tasks in graph analysis. In this paper, we focus on the choices of node representations (aggregated features vs. adjacency lists) and the edge direction of an input graph (directed vs. undirected), which have a large influence on classification results. We address the first empirical study to benchmark the performance of various GNNs that use either combination of node representations and edge directions. Our experiments demonstrate that no single combination stably achieves state-of-the-art results across datasets, which indicates that we need to select appropriate combinations depending on the characteristics of datasets. In response, we propose a simple yet holistic classification method A2DUG which leverages all combinations of node representation variants in directed and undirected graphs. We demonstrate that A2DUG stably performs well on various datasets. Surprisingly, it largely outperforms the current state-of-the-art methods in several datasets. This result validates the importance of the adaptive effect control on the combinations of node representations and edge directions.
Scardina: Scalable Join Cardinality Estimation by Multiple Density Estimators
Mar 31, 2023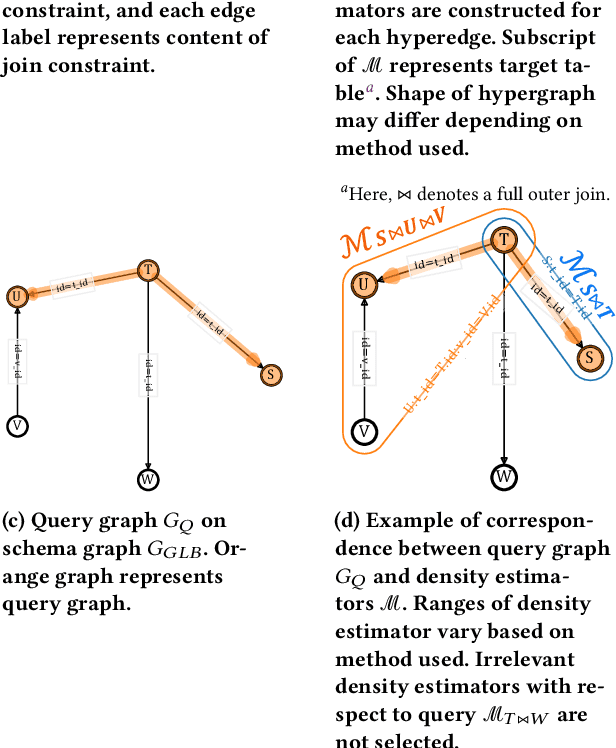
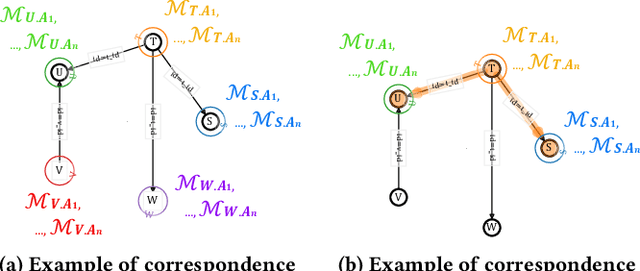

In recent years, machine learning-based cardinality estimation methods are replacing traditional methods. This change is expected to contribute to one of the most important applications of cardinality estimation, the query optimizer, to speed up query processing. However, none of the existing methods do not precisely estimate cardinalities when relational schemas consist of many tables with strong correlations between tables/attributes. This paper describes that multiple density estimators can be combined to effectively target the cardinality estimation of data with large and complex schemas having strong correlations. We propose Scardina, a new join cardinality estimation method using multiple partitioned models based on the schema structure.
GNN Transformation Framework for Improving Efficiency and Scalability
Jul 25, 2022
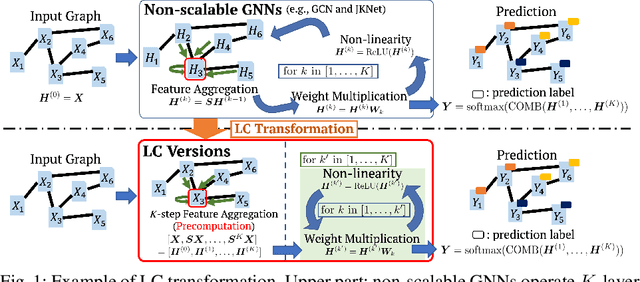
We propose a framework that automatically transforms non-scalable GNNs into precomputation-based GNNs which are efficient and scalable for large-scale graphs. The advantages of our framework are two-fold; 1) it transforms various non-scalable GNNs to scale well to large-scale graphs by separating local feature aggregation from weight learning in their graph convolution, 2) it efficiently executes precomputation on GPU for large-scale graphs by decomposing their edges into small disjoint and balanced sets. Through extensive experiments with large-scale graphs, we demonstrate that the transformed GNNs run faster in training time than existing GNNs while achieving competitive accuracy to the state-of-the-art GNNs. Consequently, our transformation framework provides simple and efficient baselines for future research on scalable GNNs.
Scaling Private Deep Learning with Low-Rank and Sparse Gradients
Jul 06, 2022

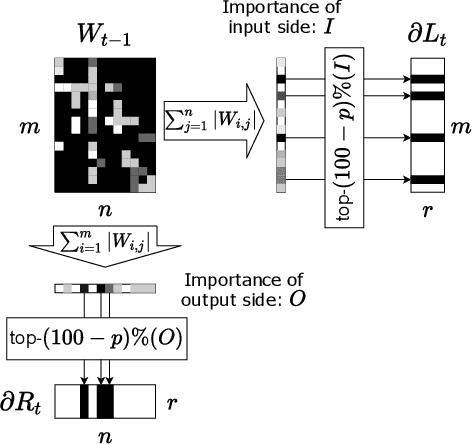
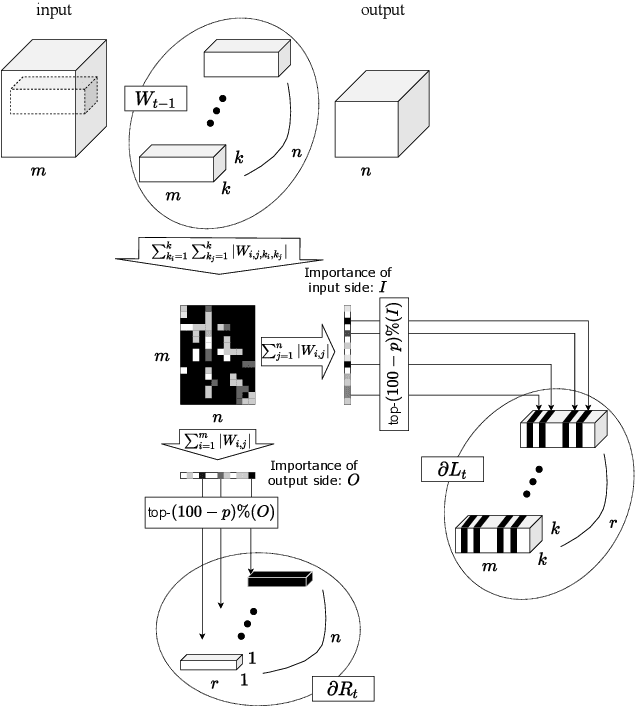
Applying Differentially Private Stochastic Gradient Descent (DPSGD) to training modern, large-scale neural networks such as transformer-based models is a challenging task, as the magnitude of noise added to the gradients at each iteration scales with model dimension, hindering the learning capability significantly. We propose a unified framework, $\textsf{LSG}$, that fully exploits the low-rank and sparse structure of neural networks to reduce the dimension of gradient updates, and hence alleviate the negative impacts of DPSGD. The gradient updates are first approximated with a pair of low-rank matrices. Then, a novel strategy is utilized to sparsify the gradients, resulting in low-dimensional, less noisy updates that are yet capable of retaining the performance of neural networks. Empirical evaluation on natural language processing and computer vision tasks shows that our method outperforms other state-of-the-art baselines.
An Empirical Study of Personalized Federated Learning
Jun 27, 2022
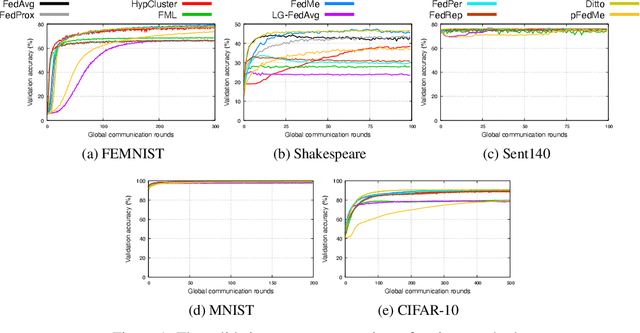
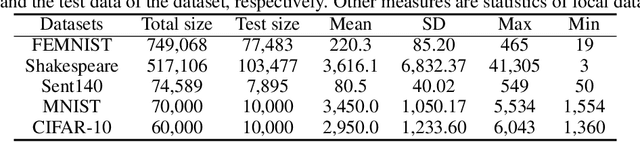

Federated learning is a distributed machine learning approach in which a single server and multiple clients collaboratively build machine learning models without sharing datasets on clients. A challenging issue of federated learning is data heterogeneity (i.e., data distributions may differ across clients). To cope with this issue, numerous federated learning methods aim at personalized federated learning and build optimized models for clients. Whereas existing studies empirically evaluated their own methods, the experimental settings (e.g., comparison methods, datasets, and client setting) in these studies differ from each other, and it is unclear which personalized federate learning method achieves the best performance and how much progress can be made by using these methods instead of standard (i.e., non-personalized) federated learning. In this paper, we benchmark the performance of existing personalized federated learning through comprehensive experiments to evaluate the characteristics of each method. Our experimental study shows that (1) there are no champion methods, (2) large data heterogeneity often leads to high accurate predictions, and (3) standard federated learning methods (e.g. FedAvg) with fine-tuning often outperform personalized federated learning methods. We open our benchmark tool FedBench for researchers to conduct experimental studies with various experimental settings.
Predicting Parking Lot Availability by Graph-to-Sequence Model: A Case Study with SmartSantander
Jun 21, 2022



Nowadays, so as to improve services and urban areas livability, multiple smart city initiatives are being carried out throughout the world. SmartSantander is a smart city project in Santander, Spain, which has relied on wireless sensor network technologies to deploy heterogeneous sensors within the city to measure multiple parameters, including outdoor parking information. In this paper, we study the prediction of parking lot availability using historical data from more than 300 outdoor parking sensors with SmartSantander. We design a graph-to-sequence model to capture the periodical fluctuation and geographical proximity of parking lots. For developing and evaluating our model, we use a 3-year dataset of parking lot availability in the city of Santander. Our model achieves a high accuracy compared with existing sequence-to-sequence models, which is accurate enough to provide a parking information service in the city. We apply our model to a smartphone application to be widely used by citizens and tourists.