 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuzhang Shang
LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Apr 01, 2024
Large Multimodal Models (LMMs) have shown significant reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically use a fixed amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which increase the number of visual tokens significantly. However, due to the design of the Transformer architecture, computational costs associated with these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism and find, similar to prior work, that many visual tokens are spatially redundant. Based on this, we propose PruMerge, a novel adaptive visual token reduction approach, which largely reduces the number of visual tokens while maintaining comparable model performance. We first select the unpruned visual tokens based on their similarity to class tokens and spatial tokens. We then cluster the pruned tokens based on key similarity and merge the clustered tokens with the unpruned tokens to supplement their information. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 18 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
FBPT: A Fully Binary Point Transformer
Mar 15, 2024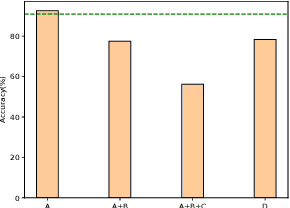
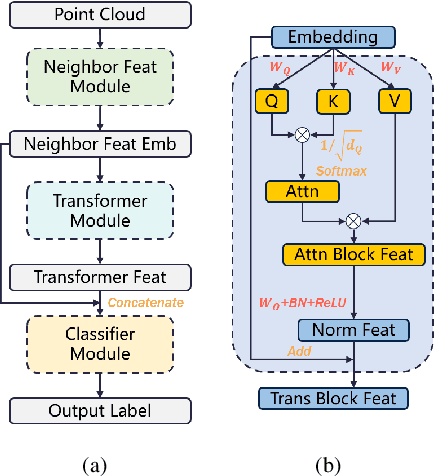
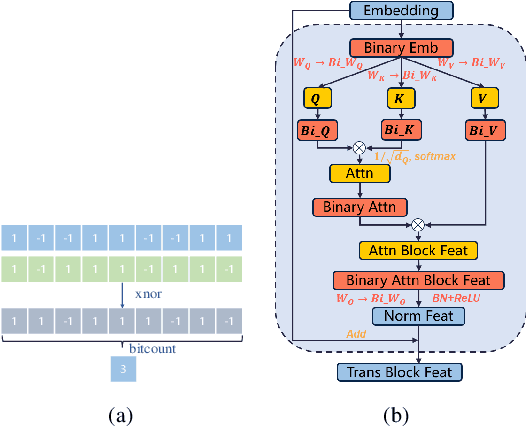

This paper presents a novel Fully Binary Point Cloud Transformer (FBPT) model which has the potential to be widely applied and expanded in the fields of robotics and mobile devices. By compressing the weights and activations of a 32-bit full-precision network to 1-bit binary values, the proposed binary point cloud Transformer network significantly reduces the storage footprint and computational resource requirements of neural network models for point cloud processing tasks, compared to full-precision point cloud networks. However, achieving a fully binary point cloud Transformer network, where all parts except the modules specific to the task are binary, poses challenges and bottlenecks in quantizing the activations of Q, K, V and self-attention in the attention module, as they do not adhere to simple probability distributions and can vary with input data. Furthermore, in our network, the binary attention module undergoes a degradation of the self-attention module due to the uniform distribution that occurs after the softmax operation. The primary focus of this paper is on addressing the performance degradation issue caused by the use of binary point cloud Transformer modules. We propose a novel binarization mechanism called dynamic-static hybridization. Specifically, our approach combines static binarization of the overall network model with fine granularity dynamic binarization of data-sensitive components. Furthermore, we make use of a novel hierarchical training scheme to obtain the optimal model and binarization parameters. These above improvements allow the proposed binarization method to outperform binarization methods applied to convolution neural networks when used in point cloud Transformer structures. To demonstrate the superiority of our algorithm, we conducted experiments on two different tasks: point cloud classification and place recognition.
LLM Inference Unveiled: Survey and Roofline Model Insights
Mar 11, 2024The field of efficient Large Language Model (LLM) inference is rapidly evolving, presenting a unique blend of opportunities and challenges. Although the field has expanded and is vibrant, there hasn't been a concise framework that analyzes the various methods of LLM Inference to provide a clear understanding of this domain. Our survey stands out from traditional literature reviews by not only summarizing the current state of research but also by introducing a framework based on roofline model for systematic analysis of LLM inference techniques. This framework identifies the bottlenecks when deploying LLMs on hardware devices and provides a clear understanding of practical problems, such as why LLMs are memory-bound, how much memory and computation they need, and how to choose the right hardware. We systematically collate the latest advancements in efficient LLM inference, covering crucial areas such as model compression (e.g., Knowledge Distillation and Quantization), algorithm improvements (e.g., Early Exit and Mixture-of-Expert), and both hardware and system-level enhancements. Our survey stands out by analyzing these methods with roofline model, helping us understand their impact on memory access and computation. This distinctive approach not only showcases the current research landscape but also delivers valuable insights for practical implementation, positioning our work as an indispensable resource for researchers new to the field as well as for those seeking to deepen their understanding of efficient LLM deployment. The analyze tool, LLM-Viewer, is open-sourced.
Online Multi-spectral Neuron Tracing
Mar 10, 2024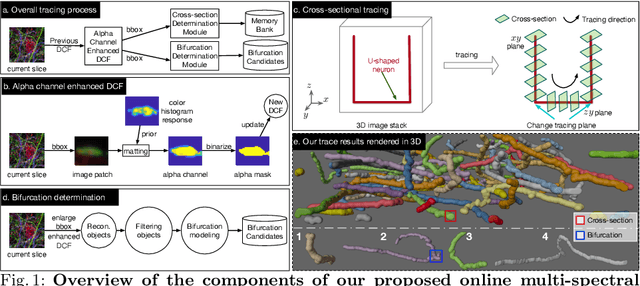

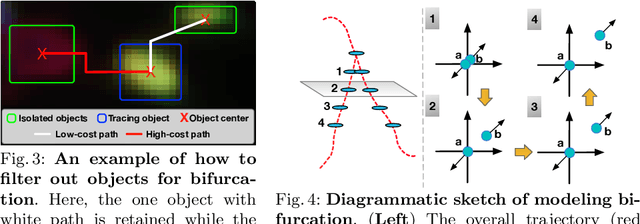
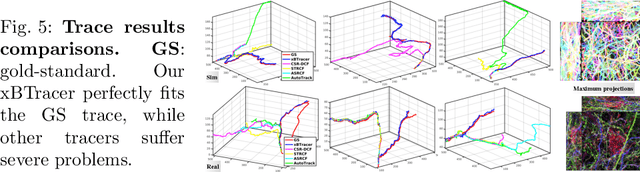
In this paper, we propose an online multi-spectral neuron tracing method with uniquely designed modules, where no offline training are required. Our method is trained online to update our enhanced discriminative correlation filter to conglutinate the tracing process. This distinctive offline-training-free schema differentiates us from other training-dependent tracing approaches like deep learning methods since no annotation is needed for our method. Besides, compared to other tracing methods requiring complicated set-up such as for clustering and graph multi-cut, our approach is much easier to be applied to new images. In fact, it only needs a starting bounding box of the tracing neuron, significantly reducing users' configuration effort. Our extensive experiments show that our training-free and easy-configured methodology allows fast and accurate neuron reconstructions in multi-spectral images.
QuEST: Low-bit Diffusion Model Quantization via Efficient Selective Finetuning
Feb 13, 2024Diffusion models have achieved remarkable success in image generation tasks, yet their practical deployment is restrained by the high memory and time consumption. While quantization paves a way for diffusion model compression and acceleration, existing methods totally fail when the models are quantized to low-bits. In this paper, we unravel three properties in quantized diffusion models that compromise the efficacy of current methods: imbalanced activation distributions, imprecise temporal information, and vulnerability to perturbations of specific modules. To alleviate the intensified low-bit quantization difficulty stemming from the distribution imbalance, we propose finetuning the quantized model to better adapt to the activation distribution. Building on this idea, we identify two critical types of quantized layers: those holding vital temporal information and those sensitive to reduced bit-width, and finetune them to mitigate performance degradation with efficiency. We empirically verify that our approach modifies the activation distribution and provides meaningful temporal information, facilitating easier and more accurate quantization. Our method is evaluated over three high-resolution image generation tasks and achieves state-of-the-art performance under various bit-width settings, as well as being the first method to generate readable images on full 4-bit (i.e. W4A4) Stable Diffusion. Code is been made publicly available.
MIM4DD: Mutual Information Maximization for Dataset Distillation
Dec 27, 2023Dataset distillation (DD) aims to synthesize a small dataset whose test performance is comparable to a full dataset using the same model. State-of-the-art (SoTA) methods optimize synthetic datasets primarily by matching heuristic indicators extracted from two networks: one from real data and one from synthetic data (see Fig.1, Left), such as gradients and training trajectories. DD is essentially a compression problem that emphasizes maximizing the preservation of information contained in the data. We argue that well-defined metrics which measure the amount of shared information between variables in information theory are necessary for success measurement but are never considered by previous works. Thus, we introduce mutual information (MI) as the metric to quantify the shared information between the synthetic and the real datasets, and devise MIM4DD numerically maximizing the MI via a newly designed optimizable objective within a contrastive learning framework to update the synthetic dataset. Specifically, we designate the samples in different datasets that share the same labels as positive pairs and vice versa negative pairs. Then we respectively pull and push those samples in positive and negative pairs into contrastive space via minimizing NCE loss. As a result, the targeted MI can be transformed into a lower bound represented by feature maps of samples, which is numerically feasible. Experiment results show that MIM4DD can be implemented as an add-on module to existing SoTA DD methods.
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models
Dec 10, 2023This paper explores a new post-hoc training-free compression paradigm for compressing Large Language Models (LLMs) to facilitate their wider adoption in various computing environments. We delve into the challenges of LLM compression, notably their dependency on extensive training data and computational resources. We propose a training-free approach dubbed Activation-aware Singular Value Decomposition (ASVD) to address these limitations. ASVD effectively manages activation outliers by adjusting the weight matrix based on the activation distribution, improving decomposition accuracy and efficiency. Our method also addresses the varying sensitivity of different LLM layers to decomposition, with an iterative calibration process for optimal layer-specific decomposition. Experiments demonstrate that ASVD can compress network by 10%-20% without losing reasoning capacities. Additionally, it can be seamlessly integrated with other LLM compression paradigms, showcasing its flexible compatibility. Code and compressed models are available at https://github.com/hahnyuan/ASVD4LLM.
PB-LLM: Partially Binarized Large Language Models
Sep 29, 2023This paper explores network binarization, a radical form of quantization, compressing model weights to a single bit, specifically for Large Language Models (LLMs) compression. Due to previous binarization methods collapsing LLMs, we propose a novel approach, Partially-Binarized LLM (PB-LLM), which can achieve extreme low-bit quantization while maintaining the linguistic reasoning capacity of quantized LLMs. Specifically, our exploration first uncovers the ineffectiveness of naive applications of existing binarization algorithms and highlights the imperative role of salient weights in achieving low-bit quantization. Thus, PB-LLM filters a small ratio of salient weights during binarization, allocating them to higher-bit storage, i.e., partially-binarization. PB-LLM is extended to recover the capacities of quantized LMMs, by analyzing from the perspective of post-training quantization (PTQ) and quantization-aware training (QAT). Under PTQ, combining the concepts from GPTQ, we reconstruct the binarized weight matrix guided by the Hessian matrix and successfully recover the reasoning capacity of PB-LLM in low-bit. Under QAT, we freeze the salient weights during training, explore the derivation of optimal scaling factors crucial for minimizing the quantization error, and propose a scaling mechanism based on this derived scaling strategy for residual binarized weights. Those explorations and the developed methodologies significantly contribute to rejuvenating the performance of low-bit quantized LLMs and present substantial advancements in the field of network binarization for LLMs.The code is available at https://github.com/hahnyuan/BinaryLLM.
Causal-DFQ: Causality Guided Data-free Network Quantization
Sep 24, 2023Model quantization, which aims to compress deep neural networks and accelerate inference speed, has greatly facilitated the development of cumbersome models on mobile and edge devices. There is a common assumption in quantization methods from prior works that training data is available. In practice, however, this assumption cannot always be fulfilled due to reasons of privacy and security, rendering these methods inapplicable in real-life situations. Thus, data-free network quantization has recently received significant attention in neural network compression. Causal reasoning provides an intuitive way to model causal relationships to eliminate data-driven correlations, making causality an essential component of analyzing data-free problems. However, causal formulations of data-free quantization are inadequate in the literature. To bridge this gap, we construct a causal graph to model the data generation and discrepancy reduction between the pre-trained and quantized models. Inspired by the causal understanding, we propose the Causality-guided Data-free Network Quantization method, Causal-DFQ, to eliminate the reliance on data via approaching an equilibrium of causality-driven intervened distributions. Specifically, we design a content-style-decoupled generator, synthesizing images conditioned on the relevant and irrelevant factors; then we propose a discrepancy reduction loss to align the intervened distributions of the pre-trained and quantized models. It is worth noting that our work is the first attempt towards introducing causality to data-free quantization problem. Extensive experiments demonstrate the efficacy of Causal-DFQ. The code is available at https://github.com/42Shawn/Causal-DFQ.
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Apr 25, 2023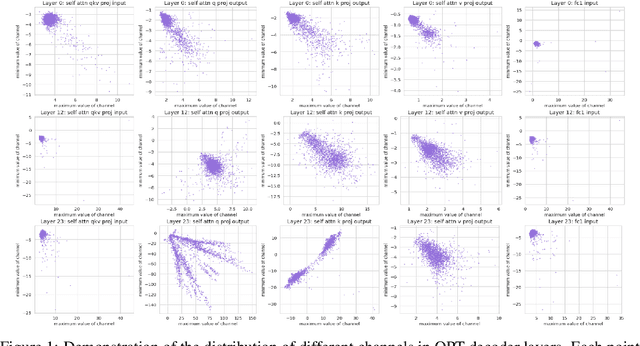
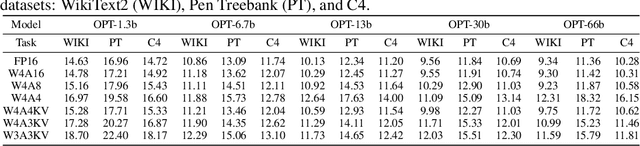
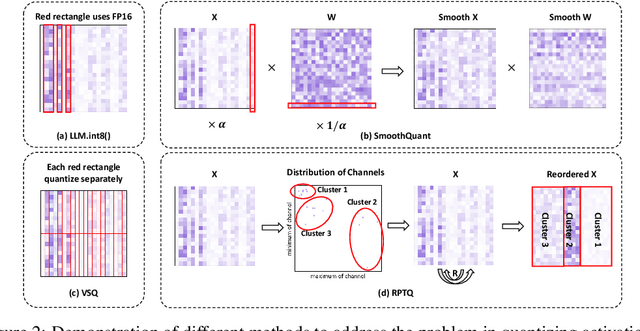
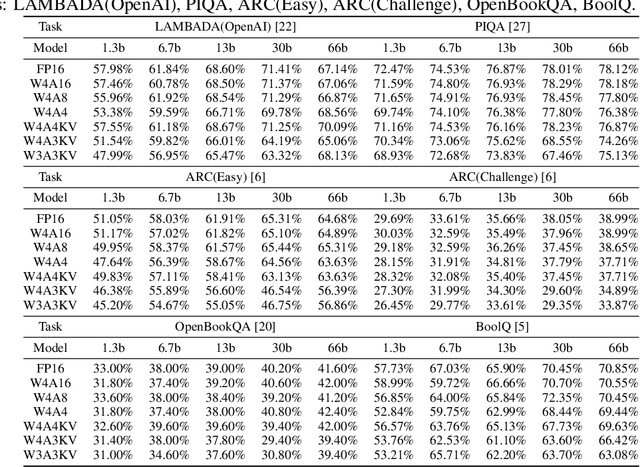
Large-scale language models (LLMs) have demonstrated outstanding performance on various tasks, but their deployment poses challenges due to their enormous model size. In this paper, we identify that the main challenge in quantizing LLMs stems from the different activation ranges between the channels, rather than just the issue of outliers.We propose a novel reorder-based quantization approach, RPTQ, that addresses the issue of quantizing the activations of LLMs. RPTQ rearranges the channels in the activations and then quantizing them in clusters, thereby reducing the impact of range difference of channels. In addition, we reduce the storage and computation overhead by avoiding explicit reordering. By implementing this approach, we achieved a significant breakthrough by pushing LLM models to 3 bit activation for the first time.