 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZafar Takhirov
Embedding Attack Project (Work Report)
Jan 24, 2024
This report summarizes all the MIA experiments (Membership Inference Attacks) of the Embedding Attack Project, including threat models, experimental setup, experimental results, findings and discussion. Current results cover the evaluation of two main MIA strategies (loss-based and embedding-based MIAs) on 6 AI models ranging from Computer Vision to Language Modelling. There are two ongoing experiments on MIA defense and neighborhood-comparison embedding attacks. These are ongoing projects. The current work on MIA and PIA can be summarized into six conclusions: (1) Amount of overfitting is directly proportional to model's vulnerability; (2) early embedding layers in the model are less susceptible to privacy leaks; (3) Deeper model layers contain more membership information; (4) Models are more vulnerable to MIA if both embeddings and corresponding training labels are compromised; (5) it is possible to use pseudo-labels to increase the MIA success; and (6) although MIA and PIA success rates are proportional, reducing the MIA does not necessarily reduce the PIA.
Field of Groves: An Energy-Efficient Random Forest
Apr 10, 2017


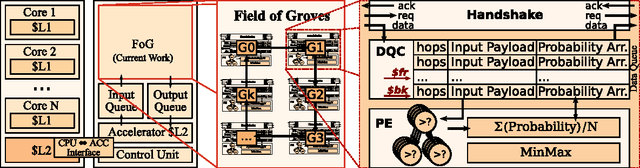
Machine Learning (ML) algorithms, like Convolutional Neural Networks (CNN), Support Vector Machines (SVM), etc. have become widespread and can achieve high statistical performance. However their accuracy decreases significantly in energy-constrained mobile and embedded systems space, where all computations need to be completed under a tight energy budget. In this work, we present a field of groves (FoG) implementation of random forests (RF) that achieves an accuracy comparable to CNNs and SVMs under tight energy budgets. Evaluation of the FoG shows that at comparable accuracy it consumes ~1.48x, ~24x, ~2.5x, and ~34.7x lower energy per classification compared to conventional RF, SVM_RBF , MLP, and CNN, respectively. FoG is ~6.5x less energy efficient than SVM_LR, but achieves 18% higher accuracy on average across all considered datasets.