 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZechu Li
Reconciling Reality through Simulation: A Real-to-Sim-to-Real Approach for Robust Manipulation
Mar 06, 2024
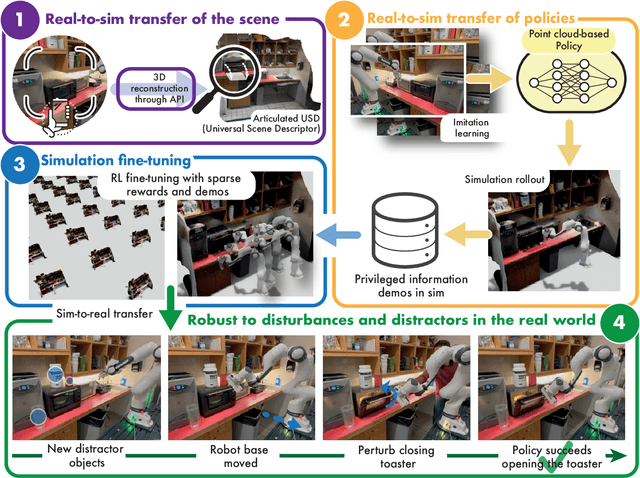



Imitation learning methods need significant human supervision to learn policies robust to changes in object poses, physical disturbances, and visual distractors. Reinforcement learning, on the other hand, can explore the environment autonomously to learn robust behaviors but may require impractical amounts of unsafe real-world data collection. To learn performant, robust policies without the burden of unsafe real-world data collection or extensive human supervision, we propose RialTo, a system for robustifying real-world imitation learning policies via reinforcement learning in "digital twin" simulation environments constructed on the fly from small amounts of real-world data. To enable this real-to-sim-to-real pipeline, RialTo proposes an easy-to-use interface for quickly scanning and constructing digital twins of real-world environments. We also introduce a novel "inverse distillation" procedure for bringing real-world demonstrations into simulated environments for efficient fine-tuning, with minimal human intervention and engineering required. We evaluate RialTo across a variety of robotic manipulation problems in the real world, such as robustly stacking dishes on a rack, placing books on a shelf, and six other tasks. RialTo increases (over 67%) in policy robustness without requiring extensive human data collection. Project website and videos at https://real-to-sim-to-real.github.io/RialTo/
Parallel $Q$-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation
Jul 24, 2023Reinforcement learning is time-consuming for complex tasks due to the need for large amounts of training data. Recent advances in GPU-based simulation, such as Isaac Gym, have sped up data collection thousands of times on a commodity GPU. Most prior works used on-policy methods like PPO due to their simplicity and ease of scaling. Off-policy methods are more data efficient but challenging to scale, resulting in a longer wall-clock training time. This paper presents a Parallel $Q$-Learning (PQL) scheme that outperforms PPO in wall-clock time while maintaining superior sample efficiency of off-policy learning. PQL achieves this by parallelizing data collection, policy learning, and value learning. Different from prior works on distributed off-policy learning, such as Apex, our scheme is designed specifically for massively parallel GPU-based simulation and optimized to work on a single workstation. In experiments, we demonstrate that $Q$-learning can be scaled to \textit{tens of thousands of parallel environments} and investigate important factors affecting learning speed. The code is available at https://github.com/Improbable-AI/pql.
ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning
Dec 11, 2021
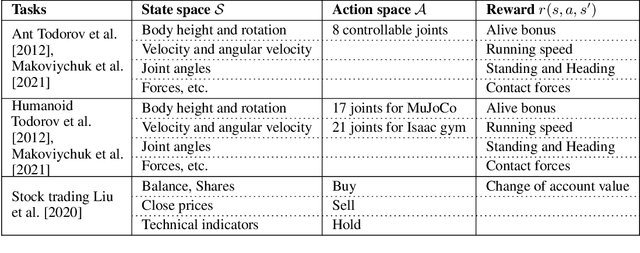


Deep reinforcement learning (DRL) has revolutionized learning and actuation in applications such as game playing and robotic control. The cost of data collection, i.e., generating transitions from agent-environment interactions, remains a major challenge for wider DRL adoption in complex real-world problems. Following a cloud-native paradigm to train DRL agents on a GPU cloud platform is a promising solution. In this paper, we present a scalable and elastic library ElegantRL-podracer for cloud-native deep reinforcement learning, which efficiently supports millions of GPU cores to carry out massively parallel training at multiple levels. At a high-level, ElegantRL-podracer employs a tournament-based ensemble scheme to orchestrate the training process on hundreds or even thousands of GPUs, scheduling the interactions between a leaderboard and a training pool with hundreds of pods. At a low-level, each pod simulates agent-environment interactions in parallel by fully utilizing nearly 7,000 GPU CUDA cores in a single GPU. Our ElegantRL-podracer library features high scalability, elasticity and accessibility by following the development principles of containerization, microservices and MLOps. Using an NVIDIA DGX SuperPOD cloud, we conduct extensive experiments on various tasks in locomotion and stock trading and show that ElegantRL-podracer substantially outperforms RLlib. Our codes are available on GitHub.
* 9 pages, 7 figures