 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeeshan Ahmed
Recovering from Privacy-Preserving Masking with Large Language Models
Sep 23, 2023
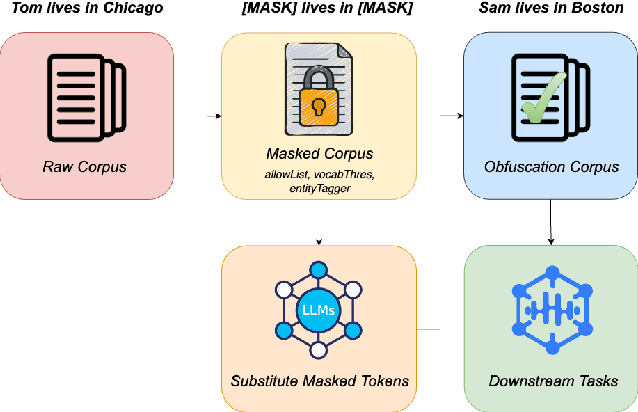
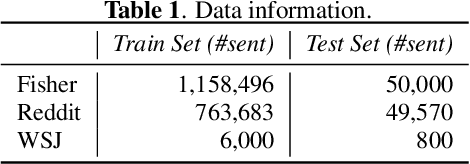
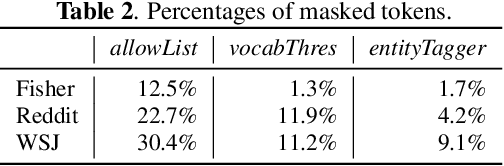
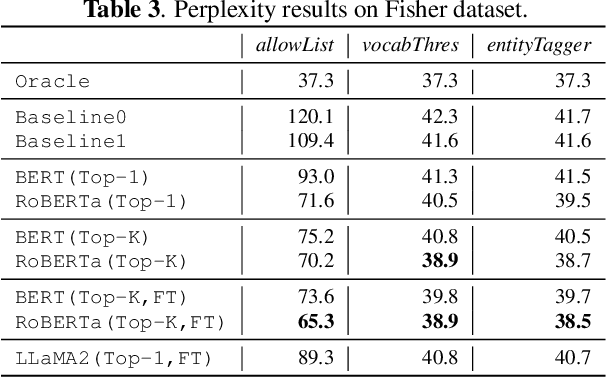
Model adaptation is crucial to handle the discrepancy between proxy training data and actual users data received. To effectively perform adaptation, textual data of users is typically stored on servers or their local devices, where downstream natural language processing (NLP) models can be directly trained using such in-domain data. However, this might raise privacy and security concerns due to the extra risks of exposing user information to adversaries. Replacing identifying information in textual data with a generic marker has been recently explored. In this work, we leverage large language models (LLMs) to suggest substitutes of masked tokens and have their effectiveness evaluated on downstream language modeling tasks. Specifically, we propose multiple pre-trained and fine-tuned LLM-based approaches and perform empirical studies on various datasets for the comparison of these methods. Experimental results show that models trained on the obfuscation corpora are able to achieve comparable performance with the ones trained on the original data without privacy-preserving token masking.
Contextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023
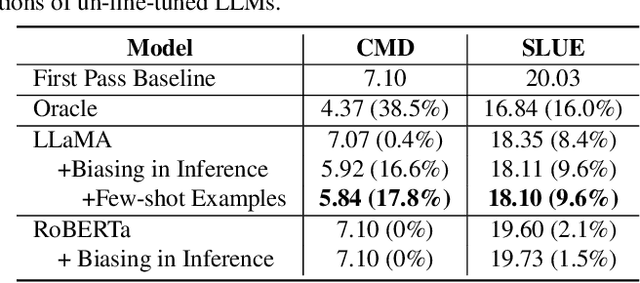
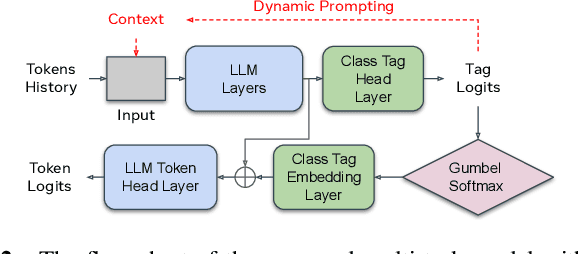
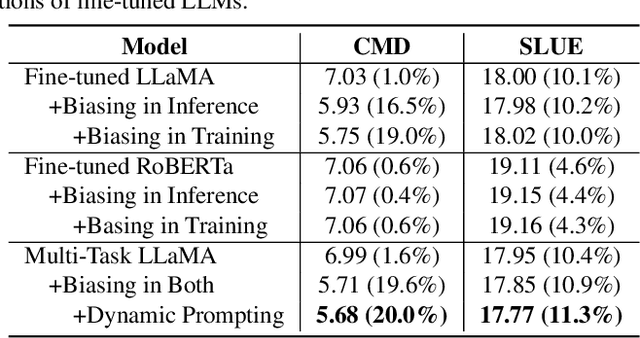
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Nostradamus: Weathering Worth
Dec 08, 2022
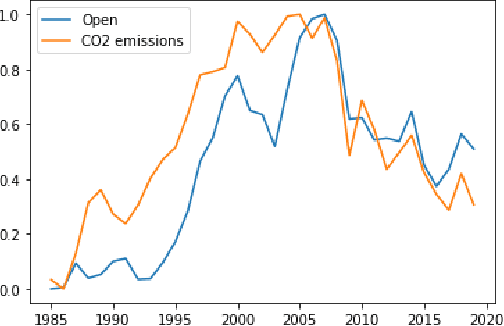
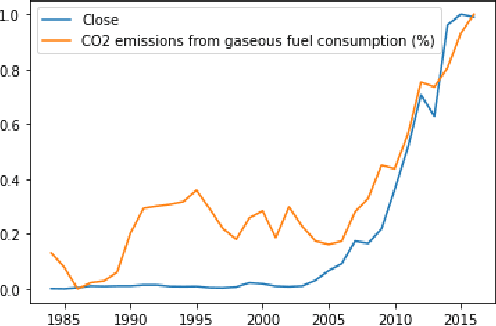
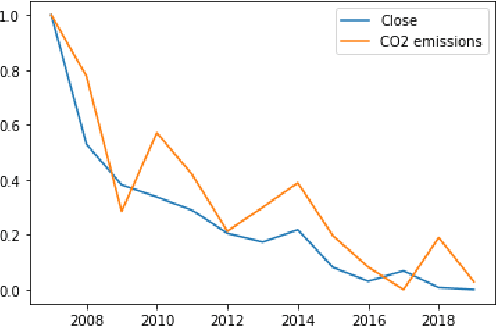
Nostradamus, inspired by the French astrologer and reputed seer, is a detailed study exploring relations between environmental factors and changes in the stock market. In this paper, we analyze associative correlation and causation between environmental elements and stock prices based on the US financial market, global climate trends, and daily weather records to demonstrate significant relationships between climate and stock price fluctuation. Our analysis covers short and long-term rises and dips in company stock performances. Lastly, we take four natural disasters as a case study to observe their effect on the emotional state of people and their influence on the stock market.
CUE Vectors: Modular Training of Language Models Conditioned on Diverse Contextual Signals
Mar 16, 2022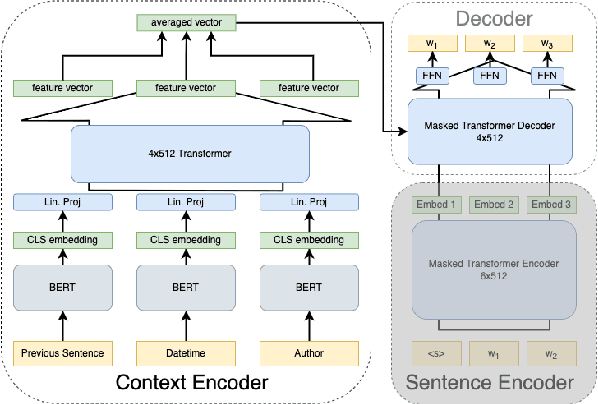
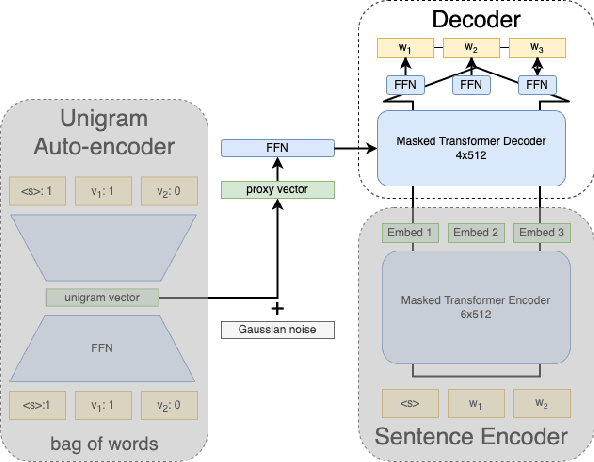
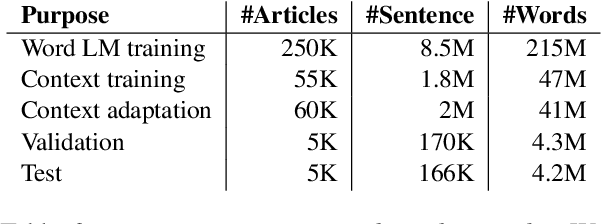
We propose a framework to modularize the training of neural language models that use diverse forms of sentence-external context (including metadata) by eliminating the need to jointly train sentence-external and within-sentence encoders. Our approach, contextual universal embeddings (CUE), trains LMs on one set of context, such as date and author, and adapts to novel metadata types, such as article title, or previous sentence. The model consists of a pretrained neural sentence LM, a BERT-based context encoder, and a masked transformer decoder that estimates LM probabilities using sentence-internal and sentence-external information. When context or metadata are unavailable, our model learns to combine contextual and sentence-internal information using noisy oracle unigram embeddings as a proxy. Real contextual information can be introduced later and used to adapt a small number of parameters that map contextual data into the decoder's embedding space. We validate the CUE framework on a NYTimes text corpus with multiple metadata types, for which the LM perplexity can be lowered from 36.6 to 27.4 by conditioning on context. Bootstrapping a contextual LM with only a subset of the context/metadata during training retains 85\% of the achievable gain. Training the model initially with proxy context retains 67% of the perplexity gain after adapting to real context. Furthermore, we can swap one type of pretrained sentence LM for another without retraining the context encoders, by only adapting the decoder model. Overall, we obtain a modular framework that allows incremental, scalable training of context-enhanced LMs.
Mitigating Closed-model Adversarial Examples with Bayesian Neural Modeling for Enhanced End-to-End Speech Recognition
Feb 17, 2022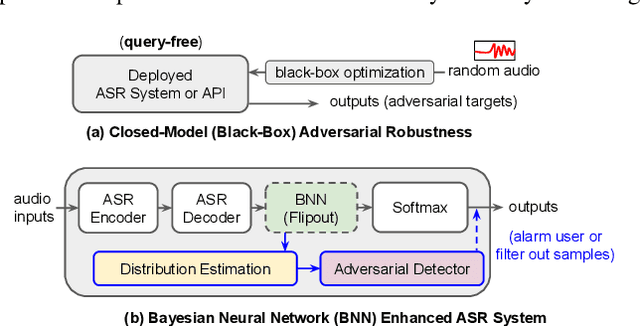

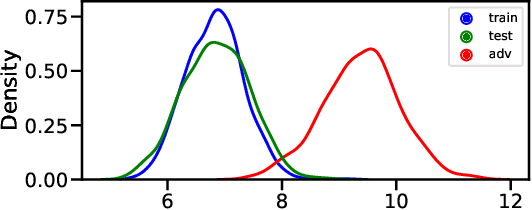
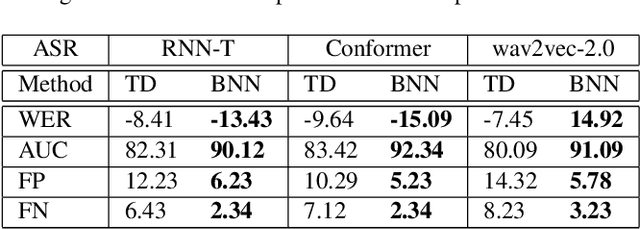
In this work, we aim to enhance the system robustness of end-to-end automatic speech recognition (ASR) against adversarially-noisy speech examples. We focus on a rigorous and empirical "closed-model adversarial robustness" setting (e.g., on-device or cloud applications). The adversarial noise is only generated by closed-model optimization (e.g., evolutionary and zeroth-order estimation) without accessing gradient information of a targeted ASR model directly. We propose an advanced Bayesian neural network (BNN) based adversarial detector, which could model latent distributions against adaptive adversarial perturbation with divergence measurement. We further simulate deployment scenarios of RNN Transducer, Conformer, and wav2vec-2.0 based ASR systems with the proposed adversarial detection system. Leveraging the proposed BNN based detection system, we improve detection rate by +2.77 to +5.42% (relative +3.03 to +6.26%) and reduce the word error rate by 5.02 to 7.47% on LibriSpeech datasets compared to the current model enhancement methods against the adversarial speech examples.
CathAI: Fully Automated Interpretation of Coronary Angiograms Using Neural Networks
Jun 14, 2021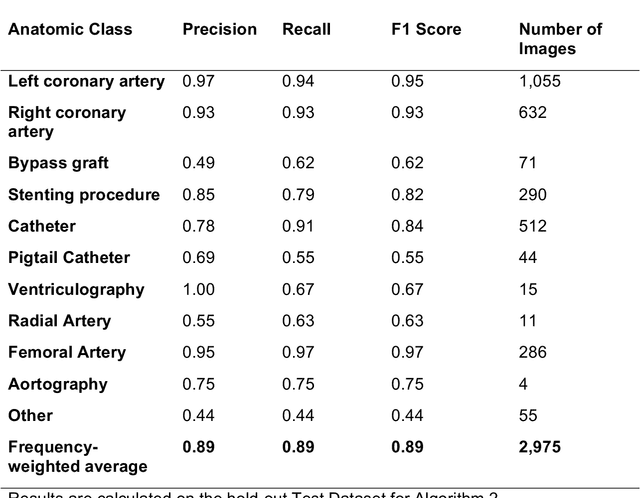
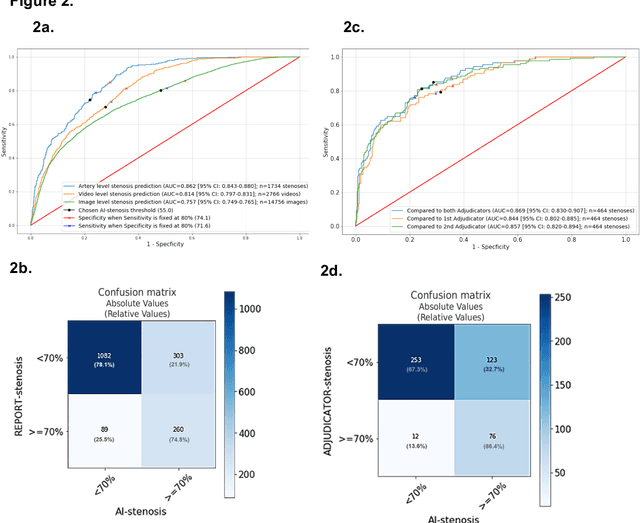
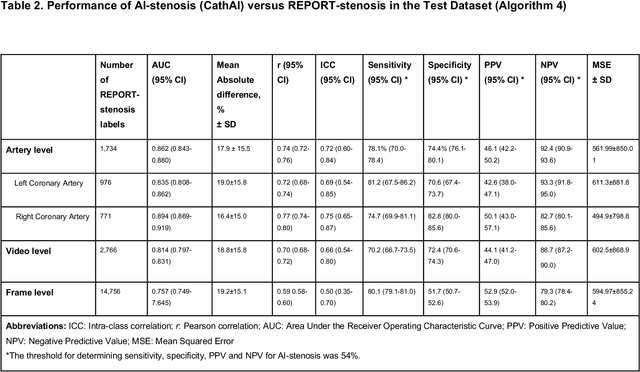
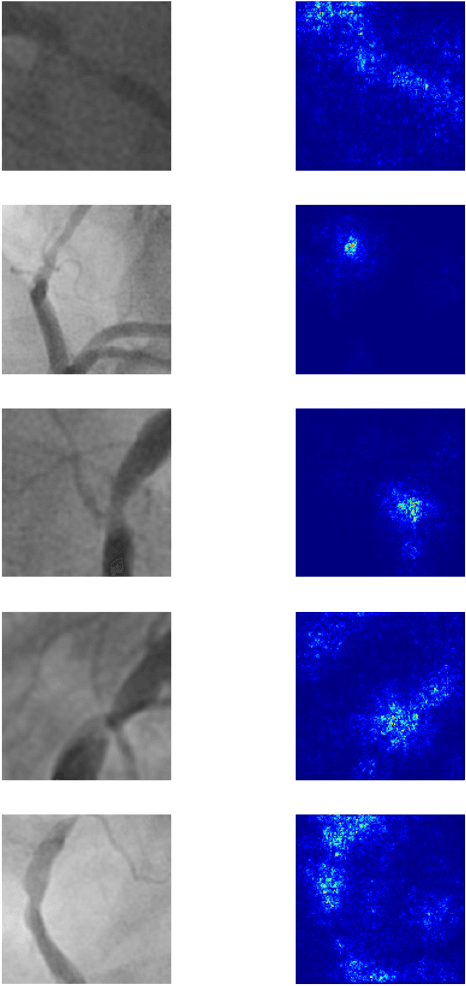
Coronary heart disease (CHD) is the leading cause of adult death in the United States and worldwide, and for which the coronary angiography procedure is the primary gateway for diagnosis and clinical management decisions. The standard-of-care for interpretation of coronary angiograms depends upon ad-hoc visual assessment by the physician operator. However, ad-hoc visual interpretation of angiograms is poorly reproducible, highly variable and bias prone. Here we show for the first time that fully-automated angiogram interpretation to estimate coronary artery stenosis is possible using a sequence of deep neural network algorithms. The algorithmic pipeline we developed--called CathAI--achieves state-of-the art performance across the sequence of tasks required to accomplish automated interpretation of unselected, real-world angiograms. CathAI (Algorithms 1-2) demonstrated positive predictive value, sensitivity and F1 score of >=90% to identify the projection angle overall and >=93% for left or right coronary artery angiogram detection, the primary anatomic structures of interest. To predict obstructive coronary artery stenosis (>=70% stenosis), CathAI (Algorithm 4) exhibited an area under the receiver operating characteristic curve (AUC) of 0.862 (95% CI: 0.843-0.880). When externally validated in a healthcare system in another country, CathAI AUC was 0.869 (95% CI: 0.830-0.907) to predict obstructive coronary artery stenosis. Our results demonstrate that multiple purpose-built neural networks can function in sequence to accomplish the complex series of tasks required for automated analysis of real-world angiograms. Deployment of CathAI may serve to increase standardization and reproducibility in coronary stenosis assessment, while providing a robust foundation to accomplish future tasks for algorithmic angiographic interpretation.
Machine Learning at Microsoft with ML .NET
May 15, 2019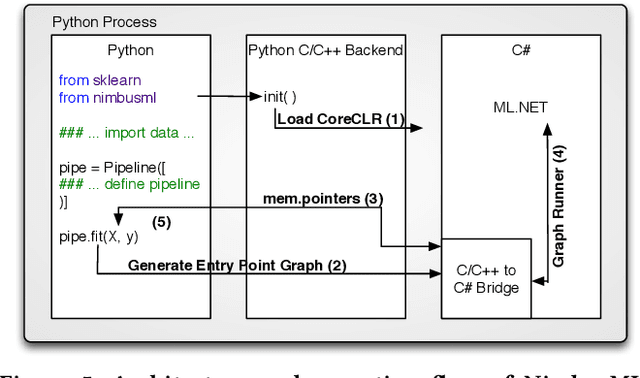
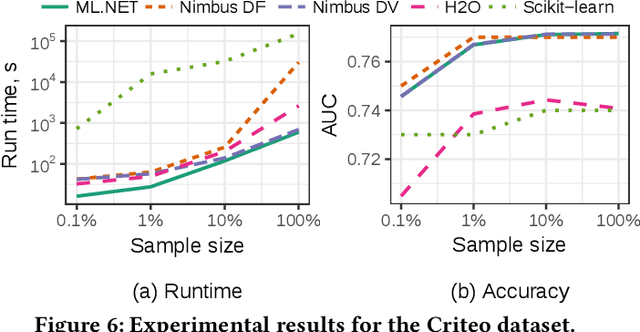
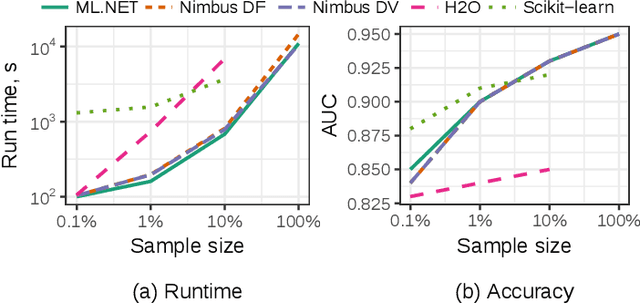
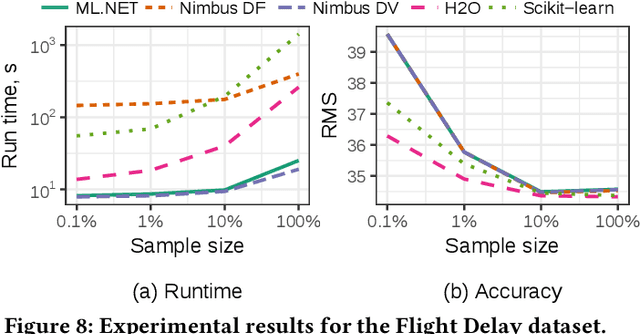
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.
Image-based Face Detection and Recognition: "State of the Art"
Feb 26, 2013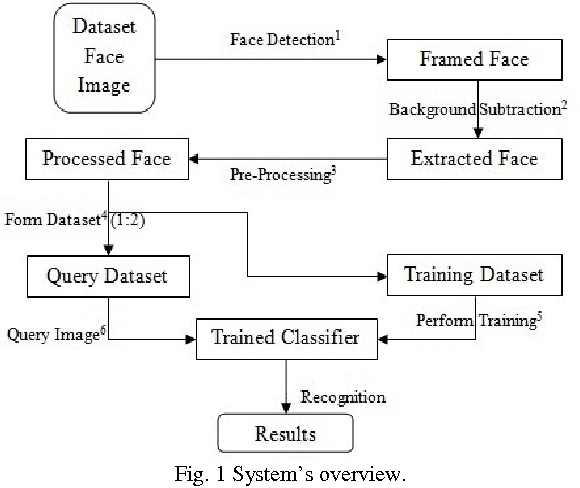
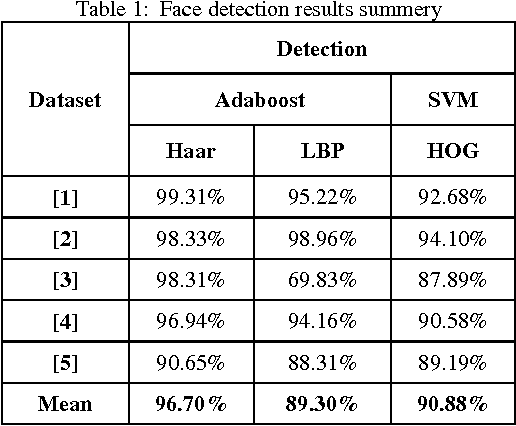
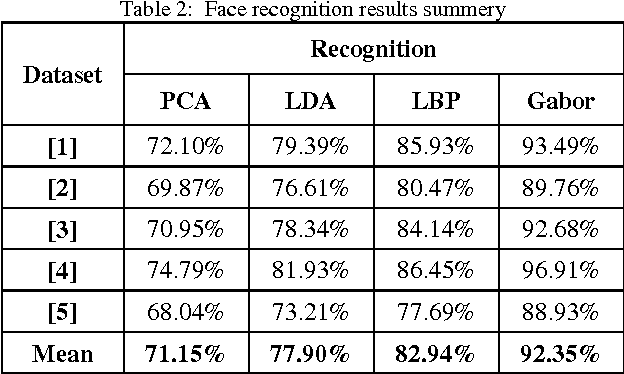

Face recognition from image or video is a popular topic in biometrics research. Many public places usually have surveillance cameras for video capture and these cameras have their significant value for security purpose. It is widely acknowledged that the face recognition have played an important role in surveillance system as it doesn't need the object's cooperation. The actual advantages of face based identification over other biometrics are uniqueness and acceptance. As human face is a dynamic object having high degree of variability in its appearance, that makes face detection a difficult problem in computer vision. In this field, accuracy and speed of identification is a main issue. The goal of this paper is to evaluate various face detection and recognition methods, provide complete solution for image based face detection and recognition with higher accuracy, better response rate as an initial step for video surveillance. Solution is proposed based on performed tests on various face rich databases in terms of subjects, pose, emotions, race and light.
* 4 pages, 3 table, 4 figure