 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZekun Wu
Shifting Focus with HCEye: Exploring the Dynamics of Visual Highlighting and Cognitive Load on User Attention and Saliency Prediction
May 02, 2024
Visual highlighting can guide user attention in complex interfaces. However, its effectiveness under limited attentional capacities is underexplored. This paper examines the joint impact of visual highlighting (permanent and dynamic) and dual-task-induced cognitive load on gaze behaviour. Our analysis, using eye-movement data from 27 participants viewing 150 unique webpages reveals that while participants' ability to attend to UI elements decreases with increasing cognitive load, dynamic adaptations (i.e., highlighting) remain attention-grabbing. The presence of these factors significantly alters what people attend to and thus what is salient. Accordingly, we show that state-of-the-art saliency models increase their performance when accounting for different cognitive loads. Our empirical insights, along with our openly available dataset, enhance our understanding of attentional processes in UIs under varying cognitive (and perceptual) loads and open the door for new models that can predict user attention while multitasking.
* 18 pages, 9 Figures, Conference: ACM Symposium on Eye Tracking Research & Applications (ETRA); Journal: Proc. ACM Hum.-Comput. Interact., Vol. 8, No. ETRA, Article 236. Publication date: May 2024
Auditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Apr 02, 2024Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
Advancing Multimodal Data Fusion in Pain Recognition: A Strategy Leveraging Statistical Correlation and Human-Centered Perspectives
Mar 30, 2024This research tackles the challenge of integrating heterogeneous data for specific behavior recognition within the domain of Pain Recognition, presenting a novel methodology that harmonizes statistical correlations with a human-centered approach. By leveraging a diverse range of deep learning architectures, we highlight the adaptability and efficacy of our approach in improving model performance across various complex scenarios. The novelty of our methodology is the strategic incorporation of statistical relevance weights and the segmentation of modalities from a human-centric perspective, enhancing model precision and providing a explainable analysis of multimodal data. This study surpasses traditional modality fusion techniques by underscoring the role of data diversity and customized modality segmentation in enhancing pain behavior analysis. Introducing a framework that matches each modality with an suited classifier, based on the statistical significance, signals a move towards customized and accurate multimodal fusion strategies. Our contributions extend beyond the field of Pain Recognition by delivering new insights into modality fusion and human-centered computing applications, contributing towards explainable AI and bolstering patient-centric healthcare interventions. Thus, we bridge a significant void in the effective and interpretable fusion of multimodal data, establishing a novel standard for forthcoming inquiries in pain behavior recognition and allied fields.
Eliciting Personality Traits in Large Language Models
Feb 15, 2024Large Language Models (LLMs) are increasingly being utilized by both candidates and employers in the recruitment context. However, with this comes numerous ethical concerns, particularly related to the lack of transparency in these "black-box" models. Although previous studies have sought to increase the transparency of these models by investigating the personality traits of LLMs, many of the previous studies have provided them with personality assessments to complete. On the other hand, this study seeks to obtain a better understanding of such models by examining their output variations based on different input prompts. Specifically, we use a novel elicitation approach using prompts derived from common interview questions, as well as prompts designed to elicit particular Big Five personality traits to examine whether the models were susceptible to trait-activation like humans are, to measure their personality based on the language used in their outputs. To do so, we repeatedly prompted multiple LMs with different parameter sizes, including Llama-2, Falcon, Mistral, Bloom, GPT, OPT, and XLNet (base and fine tuned versions) and examined their personality using classifiers trained on the myPersonality dataset. Our results reveal that, generally, all LLMs demonstrate high openness and low extraversion. However, whereas LMs with fewer parameters exhibit similar behaviour in personality traits, newer and LMs with more parameters exhibit a broader range of personality traits, with increased agreeableness, emotional stability, and openness. Furthermore, a greater number of parameters is positively associated with openness and conscientiousness. Moreover, fine-tuned models exhibit minor modulations in their personality traits, contingent on the dataset. Implications and directions for future research are discussed.
What User Behaviors Make the Differences During the Process of Visual Analytics?
Nov 17, 2023The understanding of visual analytics process can benefit visualization researchers from multiple aspects, including improving visual designs and developing advanced interaction functions. However, the log files of user behaviors are still hard to analyze due to the complexity of sensemaking and our lack of knowledge on the related user behaviors. This work presents a study on a comprehensive data collection of user behaviors, and our analysis approach with time-series classification methods. We have chosen a classical visualization application, Covid-19 data analysis, with common analysis tasks covering geo-spatial, time-series and multi-attributes. Our user study collects user behaviors on a diverse set of visualization tasks with two comparable systems, desktop and immersive visualizations. We summarize the classification results with three time-series machine learning algorithms at two scales, and explore the influences of behavior features. Our results reveal that user behaviors can be distinguished during the process of visual analytics and there is a potentially strong association between the physical behaviors of users and the visualization tasks they perform. We also demonstrate the usage of our models by interpreting open sessions of visual analytics, which provides an automatic way to study sensemaking without tedious manual annotations.
Prognostic classification based on random convolutional kernel
Apr 09, 2022
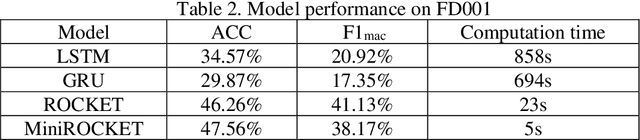

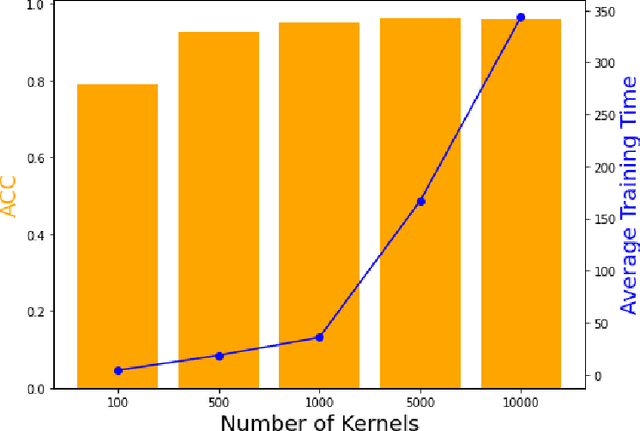
Assessing the health status (HS) of system/component has long been a challenging task in the prognostic and health management (PHM) study. Differed from other regression based prognostic task such as predicting the remaining useful life, the HS assessment is essentially a multi class classificatIon problem. To address this issue, we introduced the random convolutional kernel-based approach, the RandOm Convolutional KErnel Transforms (ROCKET) and its latest variant MiniROCKET, in the paper. We implement ROCKET and MiniROCKET on the NASA's CMPASS dataset and assess the turbine fan engine's HS with the multi-sensor time-series data. Both methods show great accuracy when tackling the HS assessment task. More importantly, they demonstrate considerably efficiency especially compare with the deep learning-based method. We further reveal that the feature generated by random convolutional kernel can be combined with other classifiers such as support vector machine (SVM) and linear discriminant analysis (LDA). The newly constructed method maintains the high efficiency and outperforms all the other deop neutal network models in classification accuracy.