 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeming Wei
Boosting Jailbreak Attack with Momentum
May 02, 2024
Large Language Models (LLMs) have achieved remarkable success across diverse tasks, yet they remain vulnerable to adversarial attacks, notably the well-documented \textit{jailbreak} attack. Recently, the Greedy Coordinate Gradient (GCG) attack has demonstrated efficacy in exploiting this vulnerability by optimizing adversarial prompts through a combination of gradient heuristics and greedy search. However, the efficiency of this attack has become a bottleneck in the attacking process. To mitigate this limitation, in this paper we rethink the generation of adversarial prompts through an optimization lens, aiming to stabilize the optimization process and harness more heuristic insights from previous iterations. Specifically, we introduce the \textbf{M}omentum \textbf{A}ccelerated G\textbf{C}G (\textbf{MAC}) attack, which incorporates a momentum term into the gradient heuristic. Experimental results showcase the notable enhancement achieved by MAP in gradient-based attacks on aligned language models. Our code is available at https://github.com/weizeming/momentum-attack-llm.
Exploring the Robustness of In-Context Learning with Noisy Labels
May 01, 2024Recently, the mysterious In-Context Learning (ICL) ability exhibited by Transformer architectures, especially in large language models (LLMs), has sparked significant research interest. However, the resilience of Transformers' in-context learning capabilities in the presence of noisy samples, prevalent in both training corpora and prompt demonstrations, remains underexplored. In this paper, inspired by prior research that studies ICL ability using simple function classes, we take a closer look at this problem by investigating the robustness of Transformers against noisy labels. Specifically, we first conduct a thorough evaluation and analysis of the robustness of Transformers against noisy labels during in-context learning and show that they exhibit notable resilience against diverse types of noise in demonstration labels. Furthermore, we delve deeper into this problem by exploring whether introducing noise into the training set, akin to a form of data augmentation, enhances such robustness during inference, and find that such noise can indeed improve the robustness of ICL. Overall, our fruitful analysis and findings provide a comprehensive understanding of the resilience of Transformer models against label noises during ICL and provide valuable insights into the research on Transformers in natural language processing. Our code is available at https://github.com/InezYu0928/in-context-learning.
Towards General Conceptual Model Editing via Adversarial Representation Engineering
Apr 21, 2024Recent research has introduced Representation Engineering (RepE) as a promising approach for understanding complex inner workings of large-scale models like Large Language Models (LLMs). However, finding practical and efficient methods to apply these representations for general and flexible model editing remains an open problem. Inspired by the Generative Adversarial Network (GAN) framework, we introduce a novel approach called Adversarial Representation Engineering (ARE). This method leverages RepE by using a representation sensor to guide the editing of LLMs, offering a unified and interpretable framework for conceptual model editing without degrading baseline performance. Our experiments on multiple conceptual editing confirm ARE's effectiveness. Code and data are available at https://github.com/Zhang-Yihao/Adversarial-Representation-Engineering.
On the Duality Between Sharpness-Aware Minimization and Adversarial Training
Feb 23, 2024Adversarial Training (AT), which adversarially perturb the input samples during training, has been acknowledged as one of the most effective defenses against adversarial attacks, yet suffers from a fundamental tradeoff that inevitably decreases clean accuracy. Instead of perturbing the samples, Sharpness-Aware Minimization (SAM) perturbs the model weights during training to find a more flat loss landscape and improve generalization. However, as SAM is designed for better clean accuracy, its effectiveness in enhancing adversarial robustness remains unexplored. In this work, considering the duality between SAM and AT, we investigate the adversarial robustness derived from SAM. Intriguingly, we find that using SAM alone can improve adversarial robustness. To understand this unexpected property of SAM, we first provide empirical and theoretical insights into how SAM can implicitly learn more robust features, and conduct comprehensive experiments to show that SAM can improve adversarial robustness notably without sacrificing any clean accuracy, shedding light on the potential of SAM to be a substitute for AT when accuracy comes at a higher priority. Code is available at https://github.com/weizeming/SAM_AT.
Studious Bob Fight Back Against Jailbreaking via Prompt Adversarial Tuning
Feb 09, 2024Although Large Language Models (LLMs) have achieved tremendous success in various applications, they are also susceptible to certain prompts that can induce them to bypass built-in safety measures and provide dangerous or illegal content, a phenomenon known as jailbreak. To protect LLMs from producing harmful information, various defense strategies are proposed, with most focusing on content filtering or adversarial training of models. In this paper, we propose an approach named Prompt Adversarial Tuning (PAT) to train a defense control mechanism, which is then embedded as a prefix to user prompts to implement our defense strategy. We design a training process similar to adversarial training to achieve our optimized goal, alternating between updating attack and defense controls. To our knowledge, we are the first to implement defense from the perspective of prompt tuning. Once employed, our method will hardly impact the operational efficiency of LLMs. Experiments show that our method is effective in both black-box and white-box settings, reducing the success rate of advanced attacks to nearly 0 while maintaining the benign answer rate of 80% to simple benign questions. Our work might potentially chart a new perspective for future explorations in LLM security.
Jatmo: Prompt Injection Defense by Task-Specific Finetuning
Jan 08, 2024Large Language Models (LLMs) are attracting significant research attention due to their instruction-following abilities, allowing users and developers to leverage LLMs for a variety of tasks. However, LLMs are vulnerable to prompt-injection attacks: a class of attacks that hijack the model's instruction-following abilities, changing responses to prompts to undesired, possibly malicious ones. In this work, we introduce Jatmo, a method for generating task-specific models resilient to prompt-injection attacks. Jatmo leverages the fact that LLMs can only follow instructions once they have undergone instruction tuning. It harnesses a teacher instruction-tuned model to generate a task-specific dataset, which is then used to fine-tune a base model (i.e., a non-instruction-tuned model). Jatmo only needs a task prompt and a dataset of inputs for the task: it uses the teacher model to generate outputs. For situations with no pre-existing datasets, Jatmo can use a single example, or in some cases none at all, to produce a fully synthetic dataset. Our experiments on seven tasks show that Jatmo models provide similar quality of outputs on their specific task as standard LLMs, while being resilient to prompt injections. The best attacks succeeded in less than 0.5% of cases against our models, versus 87% success rate against GPT-3.5-Turbo. We release Jatmo at https://github.com/wagner-group/prompt-injection-defense.
Architecture Matters: Uncovering Implicit Mechanisms in Graph Contrastive Learning
Nov 05, 2023With the prosperity of contrastive learning for visual representation learning (VCL), it is also adapted to the graph domain and yields promising performance. However, through a systematic study of various graph contrastive learning (GCL) methods, we observe that some common phenomena among existing GCL methods that are quite different from the original VCL methods, including 1) positive samples are not a must for GCL; 2) negative samples are not necessary for graph classification, neither for node classification when adopting specific normalization modules; 3) data augmentations have much less influence on GCL, as simple domain-agnostic augmentations (e.g., Gaussian noise) can also attain fairly good performance. By uncovering how the implicit inductive bias of GNNs works in contrastive learning, we theoretically provide insights into the above intriguing properties of GCL. Rather than directly porting existing VCL methods to GCL, we advocate for more attention toward the unique architecture of graph learning and consider its implicit influence when designing GCL methods. Code is available at https: //github.com/PKU-ML/ArchitectureMattersGCL.
Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
Oct 10, 2023



Large Language Models (LLMs) have shown remarkable success in various tasks, but concerns about their safety and the potential for generating malicious content have emerged. In this paper, we explore the power of In-Context Learning (ICL) in manipulating the alignment ability of LLMs. We find that by providing just few in-context demonstrations without fine-tuning, LLMs can be manipulated to increase or decrease the probability of jailbreaking, i.e. answering malicious prompts. Based on these observations, we propose In-Context Attack (ICA) and In-Context Defense (ICD) methods for jailbreaking and guarding aligned language model purposes. ICA crafts malicious contexts to guide models in generating harmful outputs, while ICD enhances model robustness by demonstrations of rejecting to answer harmful prompts. Our experiments show the effectiveness of ICA and ICD in increasing or reducing the success rate of adversarial jailbreaking attacks. Overall, we shed light on the potential of ICL to influence LLM behavior and provide a new perspective for enhancing the safety and alignment of LLMs.
Weighted Automata Extraction and Explanation of Recurrent Neural Networks for Natural Language Tasks
Jun 24, 2023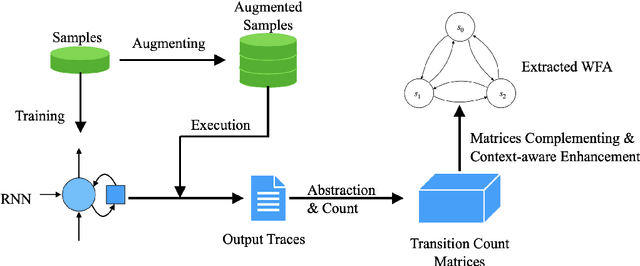
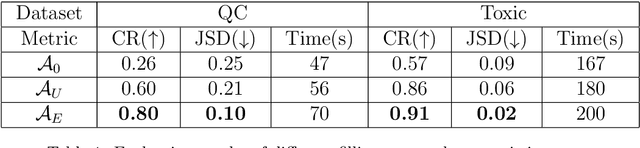
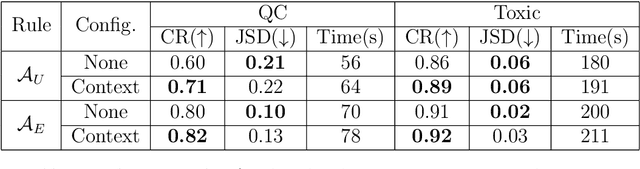
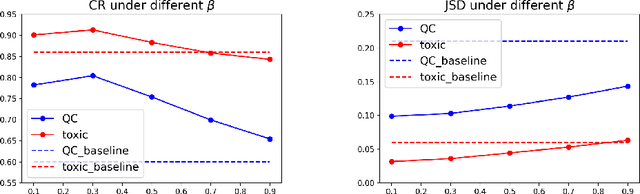
Recurrent Neural Networks (RNNs) have achieved tremendous success in processing sequential data, yet understanding and analyzing their behaviours remains a significant challenge. To this end, many efforts have been made to extract finite automata from RNNs, which are more amenable for analysis and explanation. However, existing approaches like exact learning and compositional approaches for model extraction have limitations in either scalability or precision. In this paper, we propose a novel framework of Weighted Finite Automata (WFA) extraction and explanation to tackle the limitations for natural language tasks. First, to address the transition sparsity and context loss problems we identified in WFA extraction for natural language tasks, we propose an empirical method to complement missing rules in the transition diagram, and adjust transition matrices to enhance the context-awareness of the WFA. We also propose two data augmentation tactics to track more dynamic behaviours of RNN, which further allows us to improve the extraction precision. Based on the extracted model, we propose an explanation method for RNNs including a word embedding method -- Transition Matrix Embeddings (TME) and TME-based task oriented explanation for the target RNN. Our evaluation demonstrates the advantage of our method in extraction precision than existing approaches, and the effectiveness of TME-based explanation method in applications to pretraining and adversarial example generation.
On the Relation between Sharpness-Aware Minimization and Adversarial Robustness
May 09, 2023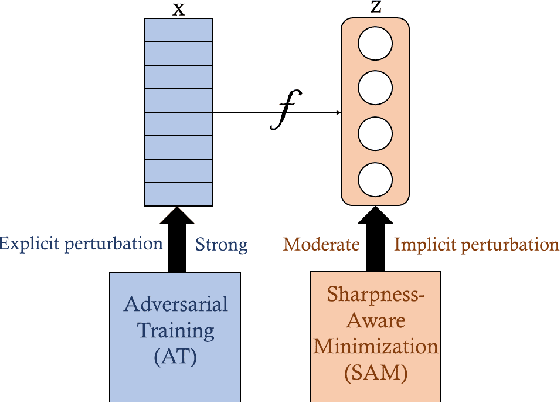
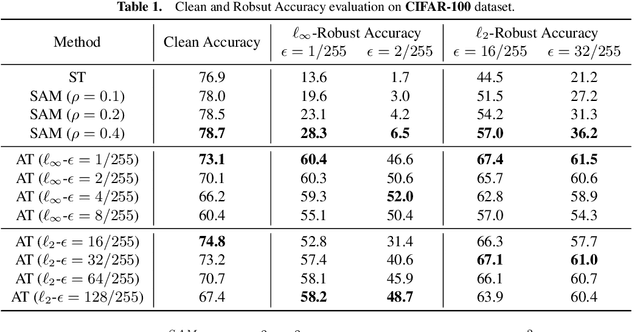
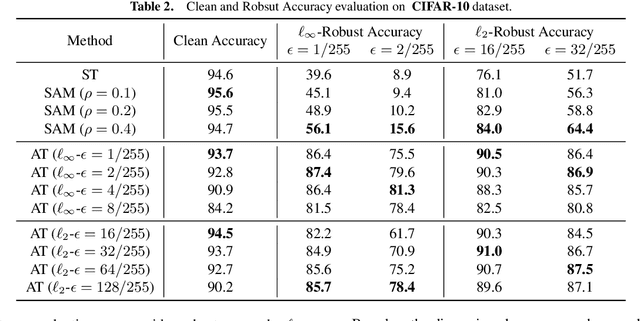
We propose a novel understanding of Sharpness-Aware Minimization (SAM) in the context of adversarial robustness. In this paper, we point out that both SAM and adversarial training (AT) can be viewed as specific feature perturbations, which improve adversarial robustness. However, we note that SAM and AT are distinct in terms of perturbation strength, leading to different accuracy and robustness trade-offs. We provide theoretical evidence for these claims in a simplified model with rigorous mathematical proofs. Furthermore, we conduct experiment to demonstrate that only utilizing SAM can achieve superior adversarial robustness compared to standard training, which is an unexpected benefit. As adversarial training can suffer from a decrease in clean accuracy, we show that using SAM alone can improve robustness without sacrificing clean accuracy. Code is available at https://github.com/weizeming/SAM_AT.