 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeyu Huang
Spatial and Surface Correspondence Field for Interaction Transfer
May 06, 2024
In this paper, we introduce a new method for the task of interaction transfer. Given an example interaction between a source object and an agent, our method can automatically infer both surface and spatial relationships for the agent and target objects within the same category, yielding more accurate and valid transfers. Specifically, our method characterizes the example interaction using a combined spatial and surface representation. We correspond the agent points and object points related to the representation to the target object space using a learned spatial and surface correspondence field, which represents objects as deformed and rotated signed distance fields. With the corresponded points, an optimization is performed under the constraints of our spatial and surface interaction representation and additional regularization. Experiments conducted on human-chair and hand-mug interaction transfer tasks show that our approach can handle larger geometry and topology variations between source and target shapes, significantly outperforming state-of-the-art methods.
Empirical Study on Updating Key-Value Memories in Transformer Feed-forward Layers
Feb 19, 2024The feed-forward networks (FFNs) in transformers are recognized as a group of key-value neural memories to restore abstract high-level knowledge. In this work, we conduct an empirical ablation study on updating keys (the 1st layer in the FFNs layer) or values (the 2nd layer in the FFNs layer). We compare those two methods in various knowledge editing and fine-tuning tasks of large language models to draw insights to understand FFNs further. Code is available at $\href{https://github.com/qiuzh20/Tuning-keys-v.s.-values}{this\,repo}$.
Emergent Mixture-of-Experts: Can Dense Pre-trained Transformers Benefit from Emergent Modular Structures?
Oct 17, 2023Incorporating modular designs into neural networks demonstrates superior out-of-generalization, learning efficiency, etc. Existing modular neural networks are generally $\textit{explicit}$ because their modular architectures are pre-defined, and individual modules are expected to implement distinct functions. Conversely, recent works reveal that there exist $\textit{implicit}$ modular structures in standard pre-trained transformers, namely $\textit{Emergent Modularity}$. They indicate that such modular structures exhibit during the early pre-training phase and are totally spontaneous. However, most transformers are still treated as monolithic models with their modular natures underutilized. Therefore, given the excellent properties of explicit modular architecture, we explore $\textit{whether and how dense pre-trained transformers can benefit from emergent modular structures.}$ To study this question, we construct \textbf{E}mergent $\textbf{M}$ixture-$\textbf{o}$f-$\textbf{E}$xperts (EMoE). Without introducing additional parameters, EMoE can be seen as the modular counterpart of the original model and can be effortlessly incorporated into downstream tuning. Extensive experiments (we tune 1785 models) on various downstream tasks (vision and language) and models (22M to1.5B) demonstrate that EMoE effectively boosts in-domain and out-of-domain generalization abilities. Further analysis and ablation study suggest that EMoE mitigates negative knowledge transfer and is robust to various configurations. Code is available at \url{https://github.com/qiuzh20/EMoE}
Transformer-Patcher: One Mistake worth One Neuron
Jan 24, 2023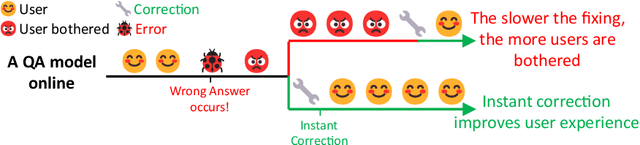
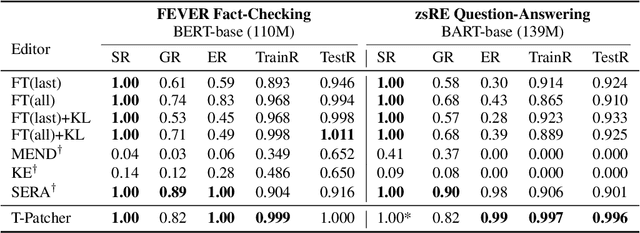
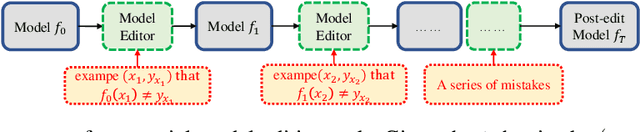
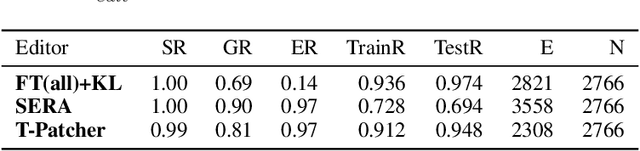
Large Transformer-based Pretrained Language Models (PLMs) dominate almost all Natural Language Processing (NLP) tasks. Nevertheless, they still make mistakes from time to time. For a model deployed in an industrial environment, fixing these mistakes quickly and robustly is vital to improve user experiences. Previous works formalize such problems as Model Editing (ME) and mostly focus on fixing one mistake. However, the one-mistake-fixing scenario is not an accurate abstraction of the real-world challenge. In the deployment of AI services, there are ever-emerging mistakes, and the same mistake may recur if not corrected in time. Thus a preferable solution is to rectify the mistakes as soon as they appear nonstop. Therefore, we extend the existing ME into Sequential Model Editing (SME) to help develop more practical editing methods. Our study shows that most current ME methods could yield unsatisfying results in this scenario. We then introduce Transformer-Patcher, a novel model editor that can shift the behavior of transformer-based models by simply adding and training a few neurons in the last Feed-Forward Network layer. Experimental results on both classification and generation tasks show that Transformer-Patcher can successively correct up to thousands of errors (Reliability) and generalize to their equivalent inputs (Generality) while retaining the model's accuracy on irrelevant inputs (Locality). Our method outperforms previous fine-tuning and HyperNetwork-based methods and achieves state-of-the-art performance for Sequential Model Editing (SME). The code is available at https://github.com/ZeroYuHuang/Transformer-Patcher.
ARO-Net: Learning Neural Fields from Anchored Radial Observations
Dec 19, 2022
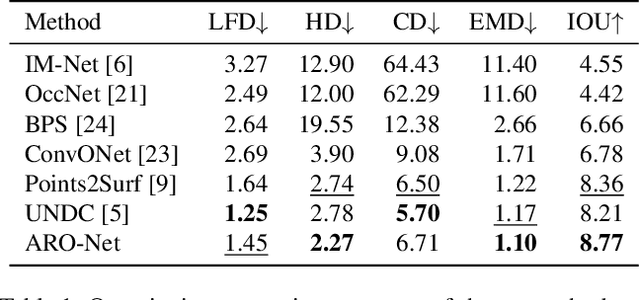
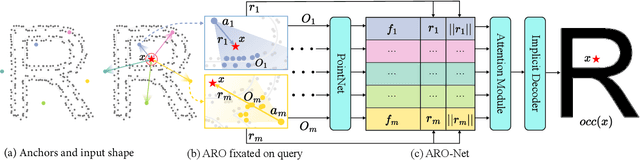
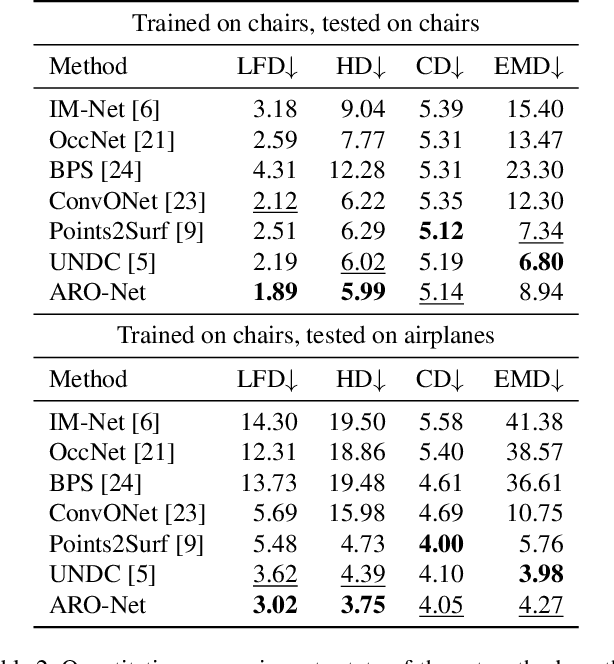
We introduce anchored radial observations (ARO), a novel shape encoding for learning neural field representation of shapes that is category-agnostic and generalizable amid significant shape variations. The main idea behind our work is to reason about shapes through partial observations from a set of viewpoints, called anchors. We develop a general and unified shape representation by employing a fixed set of anchors, via Fibonacci sampling, and designing a coordinate-based deep neural network to predict the occupancy value of a query point in space. Differently from prior neural implicit models, that use global shape feature, our shape encoder operates on contextual, query-specific features. To predict point occupancy, locally observed shape information from the perspective of the anchors surrounding the input query point are encoded and aggregated through an attention module, before implicit decoding is performed. We demonstrate the quality and generality of our network, coined ARO-Net, on surface reconstruction from sparse point clouds, with tests on novel and unseen object categories, "one-shape" training, and comparisons to state-of-the-art neural and classical methods for reconstruction and tessellation.
Mixture of Attention Heads: Selecting Attention Heads Per Token
Oct 11, 2022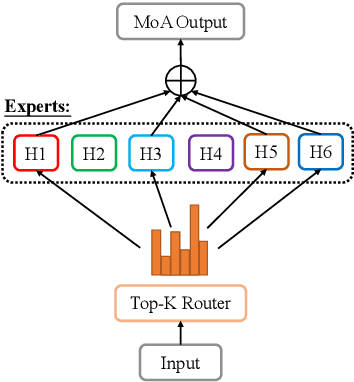
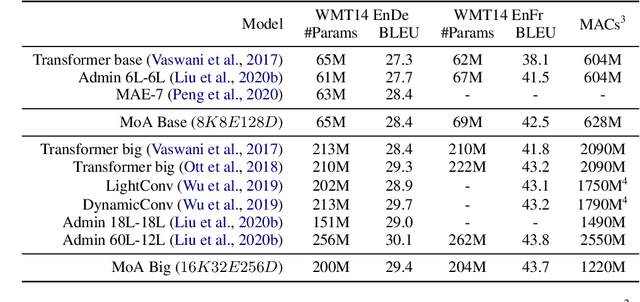
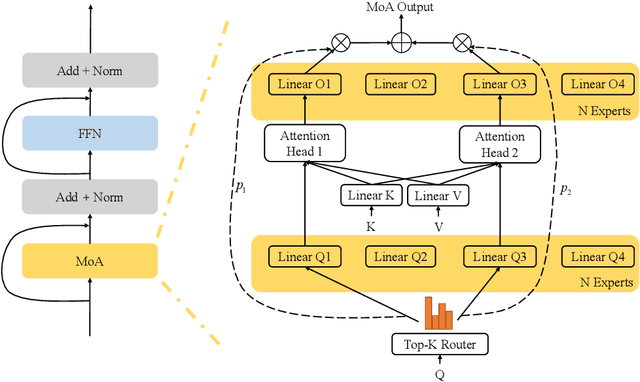
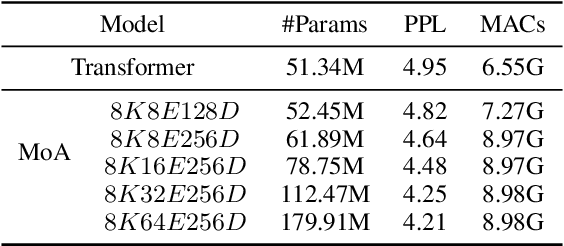
Mixture-of-Experts (MoE) networks have been proposed as an efficient way to scale up model capacity and implement conditional computing. However, the study of MoE components mostly focused on the feedforward layer in Transformer architecture. This paper proposes the Mixture of Attention Heads (MoA), a new architecture that combines multi-head attention with the MoE mechanism. MoA includes a set of attention heads that each has its own set of parameters. Given an input, a router dynamically selects a subset of $k$ attention heads per token. This conditional computation schema allows MoA to achieve stronger performance than the standard multi-head attention layer. Furthermore, the sparsely gated MoA can easily scale up the number of attention heads and the number of parameters while preserving computational efficiency. In addition to the performance improvements, MoA also automatically differentiates heads' utilities, providing a new perspective to discuss the model's interpretability. We conducted experiments on several important tasks, including Machine Translation and Masked Language Modeling. Experiments have shown promising results on several tasks against strong baselines that involve large and very deep models.
Graph2Plan: Learning Floorplan Generation from Layout Graphs
Apr 27, 2020



We introduce a learning framework for automated floorplan generation which combines generative modeling using deep neural networks and user-in-the-loop designs to enable human users to provide sparse design constraints. Such constraints are represented by a layout graph. The core component of our learning framework is a deep neural network, Graph2Plan, which converts a layout graph, along with a building boundary, into a floorplan that fulfills both the layout and boundary constraints. Given an input building boundary, we allow a user to specify room counts and other layout constraints, which are used to retrieve a set of floorplans, with their associated layout graphs, from a database. For each retrieved layout graph, along with the input boundary, Graph2Plan first generates a corresponding raster floorplan image, and then a refined set of boxes representing the rooms. Graph2Plan is trained on RPLAN, a large-scale dataset consisting of 80K annotated floorplans. The network is mainly based on convolutional processing over both the layout graph, via a graph neural network (GNN), and the input building boundary, as well as the raster floorplan images, via conventional image convolution.
Entity Extraction with Knowledge from Web Scale Corpora
Nov 21, 2019



Entity extraction is an important task in text mining and natural language processing. A popular method for entity extraction is by comparing substrings from free text against a dictionary of entities. In this paper, we present several techniques as a post-processing step for improving the effectiveness of the existing entity extraction technique. These techniques utilise models trained with the web-scale corpora which makes our techniques robust and versatile. Experiments show that our techniques bring a notable improvement on efficiency and effectiveness.