 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhang Chen
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
Mar 15, 2024
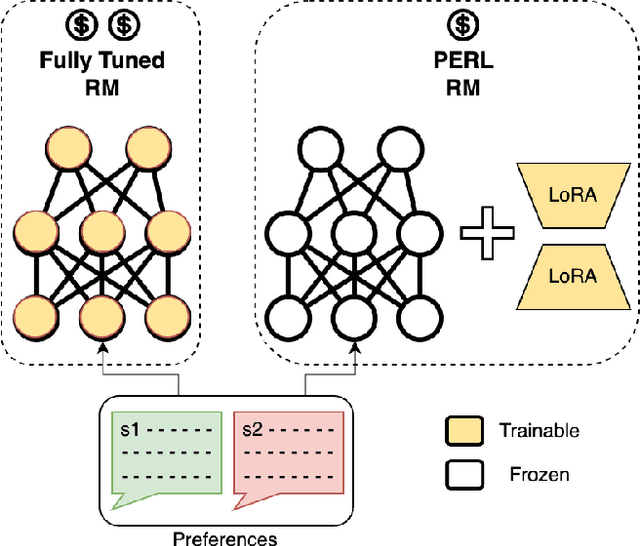
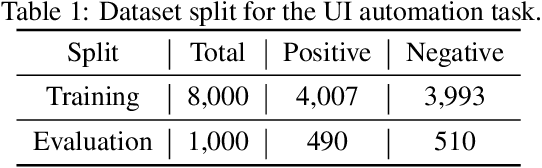
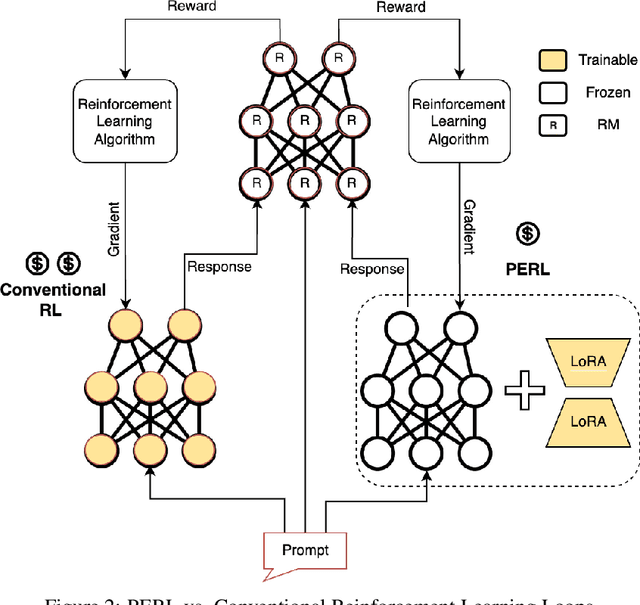
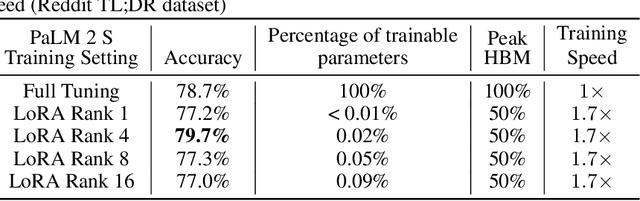
Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process. In this work, we study RLHF where the underlying models are trained using the parameter efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al. [2021]. We investigate the setup of "Parameter Efficient Reinforcement Learning" (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning. We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF, while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs up/down preference datasets: "Taskmaster Coffee", and "Taskmaster Ticketing" to promote research around RLHF.
A Bearing-Angle Approach for Unknown Target Motion Analysis Based on Visual Measurements
Jan 30, 2024Vision-based estimation of the motion of a moving target is usually formulated as a bearing-only estimation problem where the visual measurement is modeled as a bearing vector. Although the bearing-only approach has been studied for decades, a fundamental limitation of this approach is that it requires extra lateral motion of the observer to enhance the target's observability. Unfortunately, the extra lateral motion conflicts with the desired motion of the observer in many tasks. It is well-known that, once a target has been detected in an image, a bounding box that surrounds the target can be obtained. Surprisingly, this common visual measurement especially its size information has not been well explored up to now. In this paper, we propose a new bearing-angle approach to estimate the motion of a target by modeling its image bounding box as bearing-angle measurements. Both theoretical analysis and experimental results show that this approach can significantly enhance the observability without relying on additional lateral motion of the observer. The benefit of the bearing-angle approach comes with no additional cost because a bounding box is a standard output of object detection algorithms. The approach simply exploits the information that has not been fully exploited in the past. No additional sensing devices or special detection algorithms are required.
Spacetime Gaussian Feature Splatting for Real-Time Dynamic View Synthesis
Dec 28, 2023Novel view synthesis of dynamic scenes has been an intriguing yet challenging problem. Despite recent advancements, simultaneously achieving high-resolution photorealistic results, real-time rendering, and compact storage remains a formidable task. To address these challenges, we propose Spacetime Gaussian Feature Splatting as a novel dynamic scene representation, composed of three pivotal components. First, we formulate expressive Spacetime Gaussians by enhancing 3D Gaussians with temporal opacity and parametric motion/rotation. This enables Spacetime Gaussians to capture static, dynamic, as well as transient content within a scene. Second, we introduce splatted feature rendering, which replaces spherical harmonics with neural features. These features facilitate the modeling of view- and time-dependent appearance while maintaining small size. Third, we leverage the guidance of training error and coarse depth to sample new Gaussians in areas that are challenging to converge with existing pipelines. Experiments on several established real-world datasets demonstrate that our method achieves state-of-the-art rendering quality and speed, while retaining compact storage. At 8K resolution, our lite-version model can render at 60 FPS on an Nvidia RTX 4090 GPU.
Relit-NeuLF: Efficient Relighting and Novel View Synthesis via Neural 4D Light Field
Oct 23, 2023In this paper, we address the problem of simultaneous relighting and novel view synthesis of a complex scene from multi-view images with a limited number of light sources. We propose an analysis-synthesis approach called Relit-NeuLF. Following the recent neural 4D light field network (NeuLF), Relit-NeuLF first leverages a two-plane light field representation to parameterize each ray in a 4D coordinate system, enabling efficient learning and inference. Then, we recover the spatially-varying bidirectional reflectance distribution function (SVBRDF) of a 3D scene in a self-supervised manner. A DecomposeNet learns to map each ray to its SVBRDF components: albedo, normal, and roughness. Based on the decomposed BRDF components and conditioning light directions, a RenderNet learns to synthesize the color of the ray. To self-supervise the SVBRDF decomposition, we encourage the predicted ray color to be close to the physically-based rendering result using the microfacet model. Comprehensive experiments demonstrate that the proposed method is efficient and effective on both synthetic data and real-world human face data, and outperforms the state-of-the-art results. We publicly released our code on GitHub. You can find it here: https://github.com/oppo-us-research/RelitNeuLF
NeuRBF: A Neural Fields Representation with Adaptive Radial Basis Functions
Sep 27, 2023
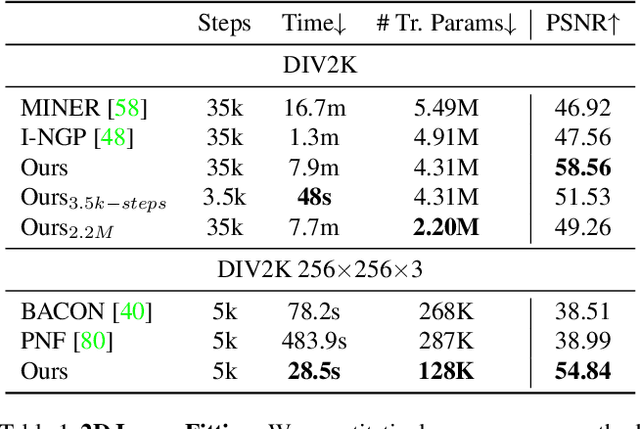
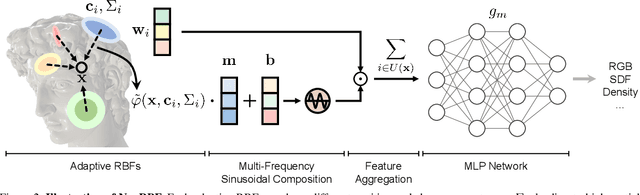
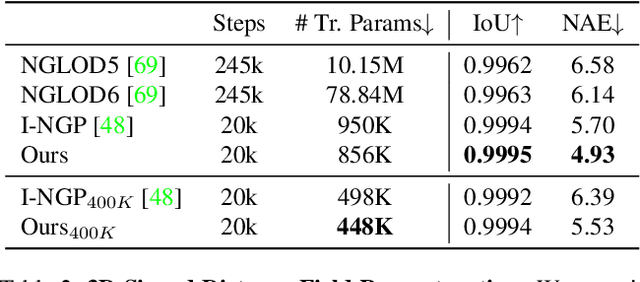
We present a novel type of neural fields that uses general radial bases for signal representation. State-of-the-art neural fields typically rely on grid-based representations for storing local neural features and N-dimensional linear kernels for interpolating features at continuous query points. The spatial positions of their neural features are fixed on grid nodes and cannot well adapt to target signals. Our method instead builds upon general radial bases with flexible kernel position and shape, which have higher spatial adaptivity and can more closely fit target signals. To further improve the channel-wise capacity of radial basis functions, we propose to compose them with multi-frequency sinusoid functions. This technique extends a radial basis to multiple Fourier radial bases of different frequency bands without requiring extra parameters, facilitating the representation of details. Moreover, by marrying adaptive radial bases with grid-based ones, our hybrid combination inherits both adaptivity and interpolation smoothness. We carefully designed weighting schemes to let radial bases adapt to different types of signals effectively. Our experiments on 2D image and 3D signed distance field representation demonstrate the higher accuracy and compactness of our method than prior arts. When applied to neural radiance field reconstruction, our method achieves state-of-the-art rendering quality, with small model size and comparable training speed.
High Fidelity 3D Hand Shape Reconstruction via Scalable Graph Frequency Decomposition
Jul 08, 2023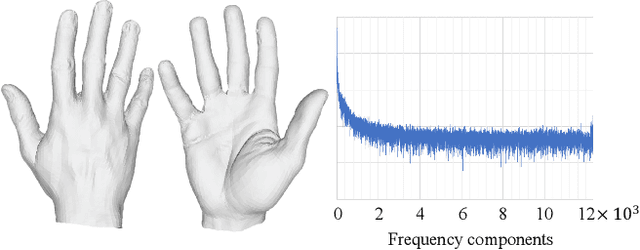
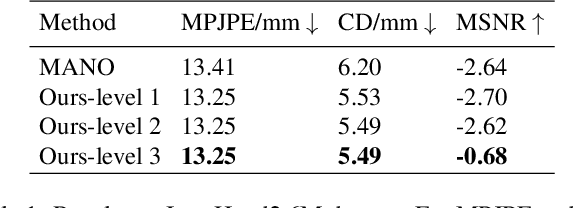
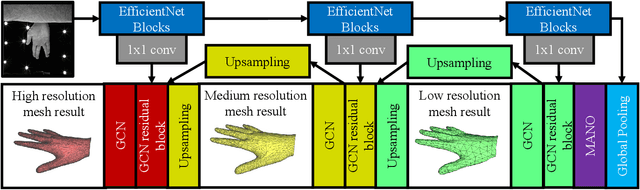
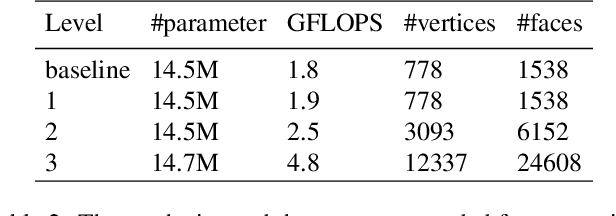
Despite the impressive performance obtained by recent single-image hand modeling techniques, they lack the capability to capture sufficient details of the 3D hand mesh. This deficiency greatly limits their applications when high-fidelity hand modeling is required, e.g., personalized hand modeling. To address this problem, we design a frequency split network to generate 3D hand mesh using different frequency bands in a coarse-to-fine manner. To capture high-frequency personalized details, we transform the 3D mesh into the frequency domain, and propose a novel frequency decomposition loss to supervise each frequency component. By leveraging such a coarse-to-fine scheme, hand details that correspond to the higher frequency domain can be preserved. In addition, the proposed network is scalable, and can stop the inference at any resolution level to accommodate different hardware with varying computational powers. To quantitatively evaluate the performance of our method in terms of recovering personalized shape details, we introduce a new evaluation metric named Mean Signal-to-Noise Ratio (MSNR) to measure the signal-to-noise ratio of each mesh frequency component. Extensive experiments demonstrate that our approach generates fine-grained details for high-fidelity 3D hand reconstruction, and our evaluation metric is more effective for measuring mesh details compared with traditional metrics.
* CVPR 2023
Harnessing Low-Frequency Neural Fields for Few-Shot View Synthesis
Mar 15, 2023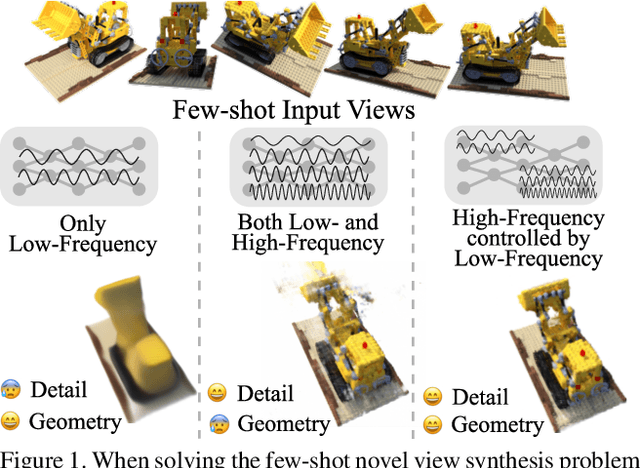
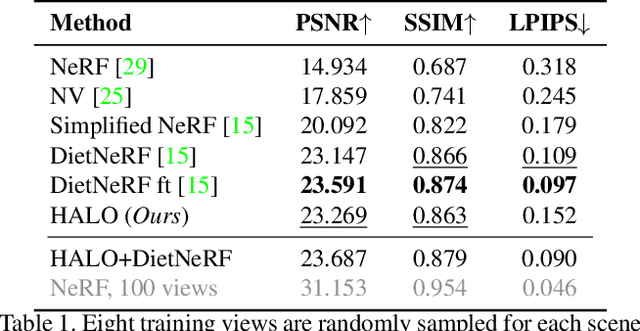

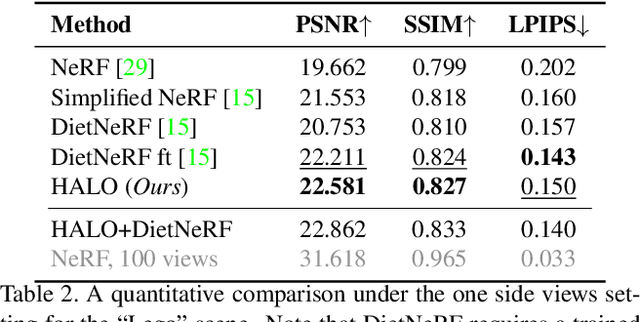
Neural Radiance Fields (NeRF) have led to breakthroughs in the novel view synthesis problem. Positional Encoding (P.E.) is a critical factor that brings the impressive performance of NeRF, where low-dimensional coordinates are mapped to high-dimensional space to better recover scene details. However, blindly increasing the frequency of P.E. leads to overfitting when the reconstruction problem is highly underconstrained, \eg, few-shot images for training. We harness low-frequency neural fields to regularize high-frequency neural fields from overfitting to better address the problem of few-shot view synthesis. We propose reconstructing with a low-frequency only field and then finishing details with a high-frequency equipped field. Unlike most existing solutions that regularize the output space (\ie, rendered images), our regularization is conducted in the input space (\ie, signal frequency). We further propose a simple-yet-effective strategy for tuning the frequency to avoid overfitting few-shot inputs: enforcing consistency among the frequency domain of rendered 2D images. Thanks to the input space regularizing scheme, our method readily applies to inputs beyond spatial locations, such as the time dimension in dynamic scenes. Comparisons with state-of-the-art on both synthetic and natural datasets validate the effectiveness of our proposed solution for few-shot view synthesis. Code is available at \href{https://github.com/lsongx/halo}{https://github.com/lsongx/halo}.
NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields
Oct 28, 2022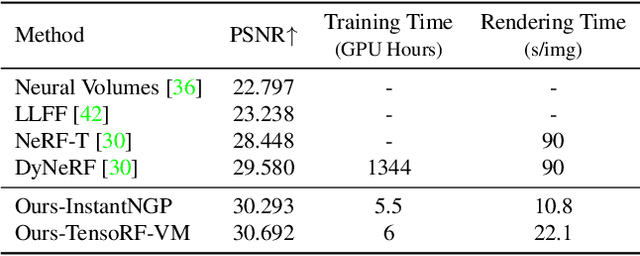



Visually exploring in a real-world 4D spatiotemporal space freely in VR has been a long-term quest. The task is especially appealing when only a few or even single RGB cameras are used for capturing the dynamic scene. To this end, we present an efficient framework capable of fast reconstruction, compact modeling, and streamable rendering. First, we propose to decompose the 4D spatiotemporal space according to temporal characteristics. Points in the 4D space are associated with probabilities of belonging to three categories: static, deforming, and new areas. Each area is represented and regularized by a separate neural field. Second, we propose a hybrid representations based feature streaming scheme for efficiently modeling the neural fields. Our approach, coined NeRFPlayer, is evaluated on dynamic scenes captured by single hand-held cameras and multi-camera arrays, achieving comparable or superior rendering performance in terms of quality and speed comparable to recent state-of-the-art methods, achieving reconstruction in 10 seconds per frame and real-time rendering.
Automatic Evaluation and Moderation of Open-domain Dialogue Systems
Nov 03, 2021


In recent years, dialogue systems have attracted significant interests in both academia and industry. Especially the discipline of open-domain dialogue systems, aka chatbots, has gained great momentum. Yet, a long standing challenge that bothers the researchers is the lack of effective automatic evaluation metrics, which results in significant impediment in the current research. Common practice in assessing the performance of open-domain dialogue models involves extensive human evaluation on the final deployed models, which is both time- and cost- intensive. Moreover, a recent trend in building open-domain chatbots involve pre-training dialogue models with a large amount of social media conversation data. However, the information contained in the social media conversations may be offensive and inappropriate. Indiscriminate usage of such data can result in insensitive and toxic generative models. This paper describes the data, baselines and results obtained for the Track 5 at the Dialogue System Technology Challenge 10 (DSTC10).
Multiple-Pilot Collaboration for Advanced Remote Intervention using Reinforcement Learning
Sep 27, 2021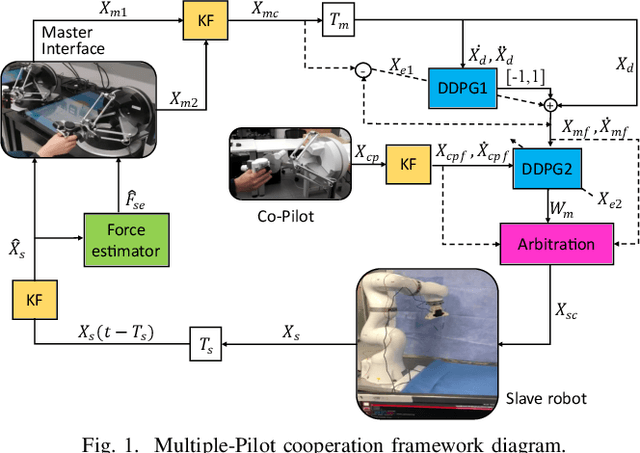
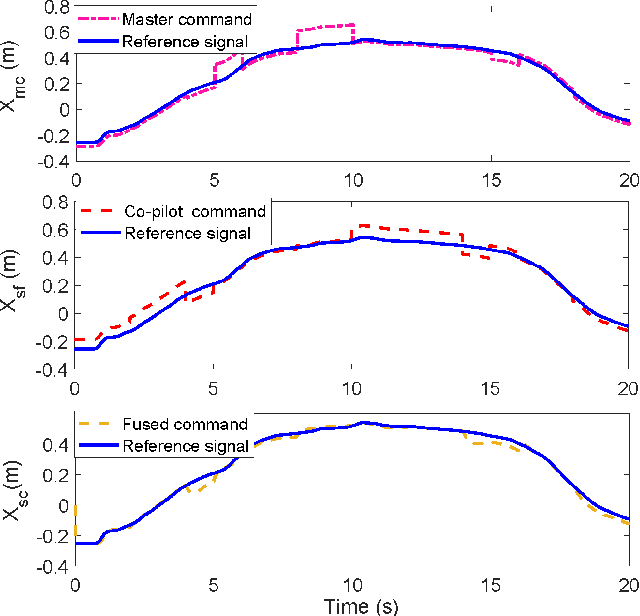
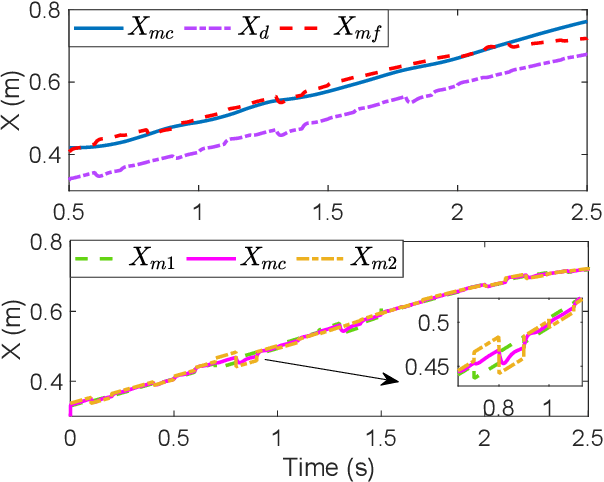
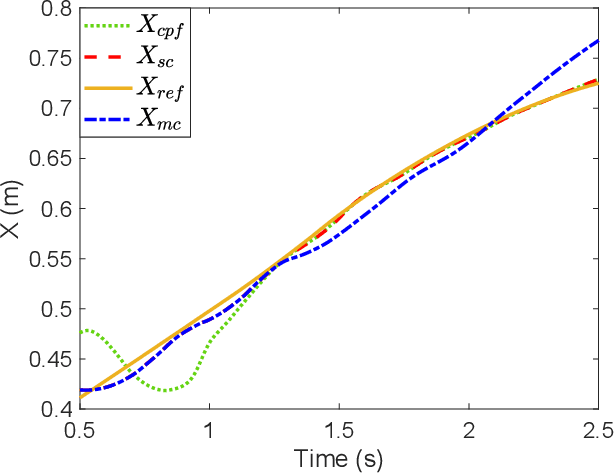
The traditional master-slave teleoperation relies on human expertise without correction mechanisms, resulting in excessive physical and mental workloads. To address these issues, a co-pilot-in-the-loop control framework is investigated for cooperative teleoperation. A deep deterministic policy gradient(DDPG) based agent is realised to effectively restore the master operators' intents without prior knowledge on time delay. The proposed framework allows for introducing an operator (i.e., co-pilot) to generate commands at the slave side, whose weights are optimally assigned online through DDPG-based arbitration, thereby enhancing the command robustness in the case of possible human operational errors. With the help of interval type-2(IT2) Takagi-Sugeno (T-S) fuzzy identification, force feedback can be reconstructed at the master side without a sense of delay, thus ensuring the telepresence performance in the force-sensor-free scenarios. Two experimental applications validate the effectiveness of the proposed framework.