 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhangkai Ni
Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
Mar 26, 2024
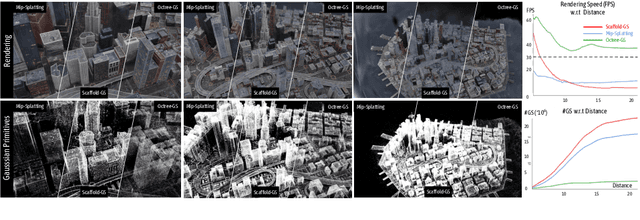



The recent 3D Gaussian splatting (3D-GS) has shown remarkable rendering fidelity and efficiency compared to NeRF-based neural scene representations. While demonstrating the potential for real-time rendering, 3D-GS encounters rendering bottlenecks in large scenes with complex details due to an excessive number of Gaussian primitives located within the viewing frustum. This limitation is particularly noticeable in zoom-out views and can lead to inconsistent rendering speeds in scenes with varying details. Moreover, it often struggles to capture the corresponding level of details at different scales with its heuristic density control operation. Inspired by the Level-of-Detail (LOD) techniques, we introduce Octree-GS, featuring an LOD-structured 3D Gaussian approach supporting level-of-detail decomposition for scene representation that contributes to the final rendering results. Our model dynamically selects the appropriate level from the set of multi-resolution anchor points, ensuring consistent rendering performance with adaptive LOD adjustments while maintaining high-fidelity rendering results.
Misalignment-Robust Frequency Distribution Loss for Image Transformation
Feb 28, 2024This paper aims to address a common challenge in deep learning-based image transformation methods, such as image enhancement and super-resolution, which heavily rely on precisely aligned paired datasets with pixel-level alignments. However, creating precisely aligned paired images presents significant challenges and hinders the advancement of methods trained on such data. To overcome this challenge, this paper introduces a novel and simple Frequency Distribution Loss (FDL) for computing distribution distance within the frequency domain. Specifically, we transform image features into the frequency domain using Discrete Fourier Transformation (DFT). Subsequently, frequency components (amplitude and phase) are processed separately to form the FDL loss function. Our method is empirically proven effective as a training constraint due to the thoughtful utilization of global information in the frequency domain. Extensive experimental evaluations, focusing on image enhancement and super-resolution tasks, demonstrate that FDL outperforms existing misalignment-robust loss functions. Furthermore, we explore the potential of our FDL for image style transfer that relies solely on completely misaligned data. Our code is available at: https://github.com/eezkni/FDL
ColNeRF: Collaboration for Generalizable Sparse Input Neural Radiance Field
Dec 15, 2023Neural Radiance Fields (NeRF) have demonstrated impressive potential in synthesizing novel views from dense input, however, their effectiveness is challenged when dealing with sparse input. Existing approaches that incorporate additional depth or semantic supervision can alleviate this issue to an extent. However, the process of supervision collection is not only costly but also potentially inaccurate, leading to poor performance and generalization ability in diverse scenarios. In our work, we introduce a novel model: the Collaborative Neural Radiance Fields (ColNeRF) designed to work with sparse input. The collaboration in ColNeRF includes both the cooperation between sparse input images and the cooperation between the output of the neural radiation field. Through this, we construct a novel collaborative module that aligns information from various views and meanwhile imposes self-supervised constraints to ensure multi-view consistency in both geometry and appearance. A Collaborative Cross-View Volume Integration module (CCVI) is proposed to capture complex occlusions and implicitly infer the spatial location of objects. Moreover, we introduce self-supervision of target rays projected in multiple directions to ensure geometric and color consistency in adjacent regions. Benefiting from the collaboration at the input and output ends, ColNeRF is capable of capturing richer and more generalized scene representation, thereby facilitating higher-quality results of the novel view synthesis. Extensive experiments demonstrate that ColNeRF outperforms state-of-the-art sparse input generalizable NeRF methods. Furthermore, our approach exhibits superiority in fine-tuning towards adapting to new scenes, achieving competitive performance compared to per-scene optimized NeRF-based methods while significantly reducing computational costs. Our code is available at: https://github.com/eezkni/ColNeRF.
Just Noticeable Difference Modeling for Face Recognition System
Sep 13, 2022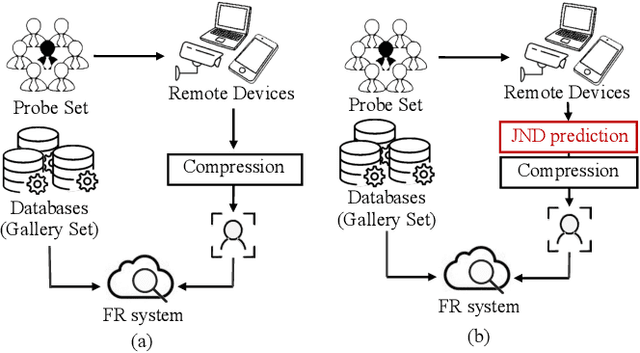

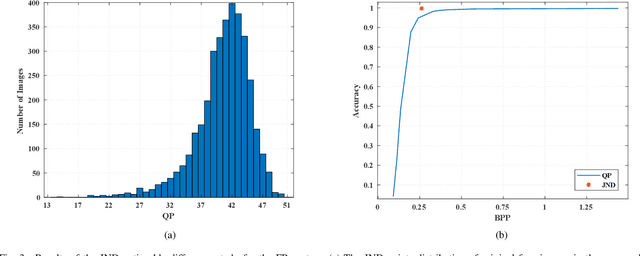
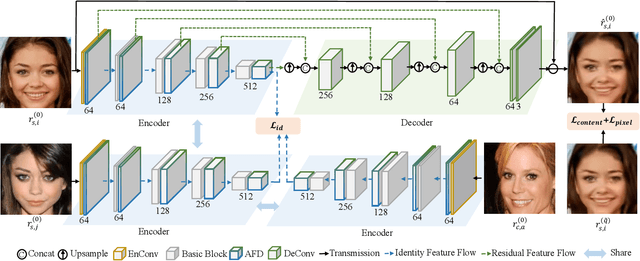
High-quality face images are required to guarantee the stability and reliability of automatic face recognition (FR) systems in surveillance and security scenarios. However, a massive amount of face data is usually compressed before being analyzed due to limitations on transmission or storage. The compressed images may lose the powerful identity information, resulting in the performance degradation of the FR system. Herein, we make the first attempt to study just noticeable difference (JND) for the FR system, which can be defined as the maximum distortion that the FR system cannot notice. More specifically, we establish a JND dataset including 3530 original images and 137,670 compressed images generated by advanced reference encoding/decoding software based on the Versatile Video Coding (VVC) standard (VTM-15.0). Subsequently, we develop a novel JND prediction model to directly infer JND images for the FR system. In particular, in order to maximum redundancy removal without impairment of robust identity information, we apply the encoder with multiple feature extraction and attention-based feature decomposition modules to progressively decompose face features into two uncorrelated components, i.e., identity and residual features, via self-supervised learning. Then, the residual feature is fed into the decoder to generate the residual map. Finally, the predicted JND map is obtained by subtracting the residual map from the original image. Experimental results have demonstrated that the proposed model achieves higher accuracy of JND map prediction compared with the state-of-the-art JND models, and is capable of saving more bits while maintaining the performance of the FR system compared with VTM-15.0.
High Dynamic Range Image Quality Assessment Based on Frequency Disparity
Sep 06, 2022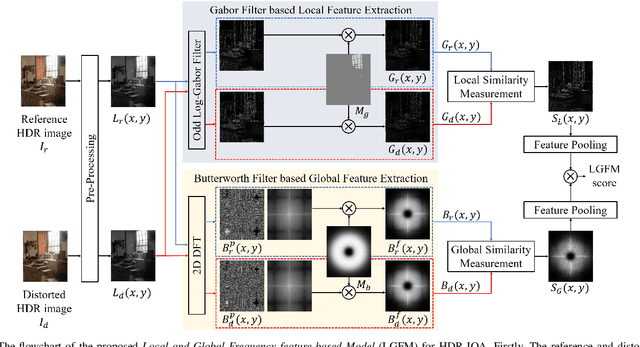


In this paper, a novel and effective image quality assessment (IQA) algorithm based on frequency disparity for high dynamic range (HDR) images is proposed, termed as local-global frequency feature-based model (LGFM). Motivated by the assumption that the human visual system is highly adapted for extracting structural information and partial frequencies when perceiving the visual scene, the Gabor and the Butterworth filters are applied to the luminance of the HDR image to extract local and global frequency features, respectively. The similarity measurement and feature pooling are sequentially performed on the frequency features to obtain the predicted quality score. The experiments evaluated on four widely used benchmarks demonstrate that the proposed LGFM can provide a higher consistency with the subjective perception compared with the state-of-the-art HDR IQA methods. Our code is available at: \url{https://github.com/eezkni/LGFM}.
Cycle-Interactive Generative Adversarial Network for Robust Unsupervised Low-Light Enhancement
Jul 03, 2022
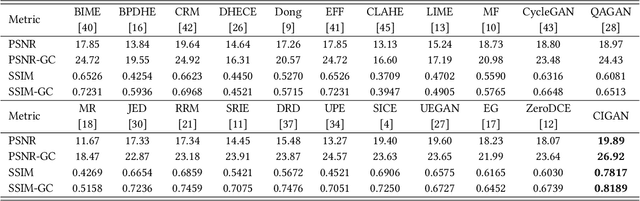
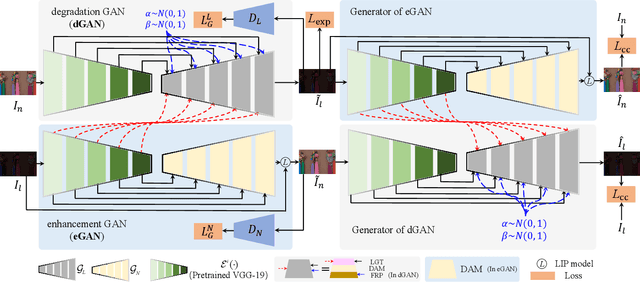
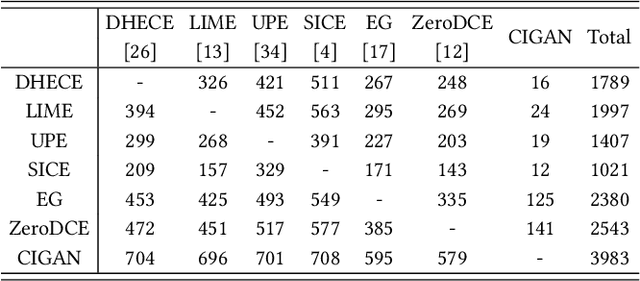
Getting rid of the fundamental limitations in fitting to the paired training data, recent unsupervised low-light enhancement methods excel in adjusting illumination and contrast of images. However, for unsupervised low light enhancement, the remaining noise suppression issue due to the lacking of supervision of detailed signal largely impedes the wide deployment of these methods in real-world applications. Herein, we propose a novel Cycle-Interactive Generative Adversarial Network (CIGAN) for unsupervised low-light image enhancement, which is capable of not only better transferring illumination distributions between low/normal-light images but also manipulating detailed signals between two domains, e.g., suppressing/synthesizing realistic noise in the cyclic enhancement/degradation process. In particular, the proposed low-light guided transformation feed-forwards the features of low-light images from the generator of enhancement GAN (eGAN) into the generator of degradation GAN (dGAN). With the learned information of real low-light images, dGAN can synthesize more realistic diverse illumination and contrast in low-light images. Moreover, the feature randomized perturbation module in dGAN learns to increase the feature randomness to produce diverse feature distributions, persuading the synthesized low-light images to contain realistic noise. Extensive experiments demonstrate both the superiority of the proposed method and the effectiveness of each module in CIGAN.
Generalized Visual Quality Assessment of GAN-Generated Face Images
Jan 28, 2022

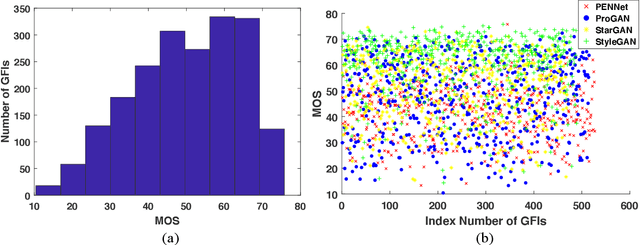
Recent years have witnessed the dramatically increased interest in face generation with generative adversarial networks (GANs). A number of successful GAN algorithms have been developed to produce vivid face images towards different application scenarios. However, little work has been dedicated to automatic quality assessment of such GAN-generated face images (GFIs), even less have been devoted to generalized and robust quality assessment of GFIs generated with unseen GAN model. Herein, we make the first attempt to study the subjective and objective quality towards generalized quality assessment of GFIs. More specifically, we establish a large-scale database consisting of GFIs from four GAN algorithms, the pseudo labels from image quality assessment (IQA) measures, as well as the human opinion scores via subjective testing. Subsequently, we develop a quality assessment model that is able to deliver accurate quality predictions for GFIs from both available and unseen GAN algorithms based on meta-learning. In particular, to learn shared knowledge from GFIs pairs that are born of limited GAN algorithms, we develop the convolutional block attention (CBA) and facial attributes-based analysis (ABA) modules, ensuring that the learned knowledge tends to be consistent with human visual perception. Extensive experiments exhibit that the proposed model achieves better performance compared with the state-of-the-art IQA models, and is capable of retaining the effectiveness when evaluating GFIs from the unseen GAN algorithms.
CSformer: Bridging Convolution and Transformer for Compressive Sensing
Dec 31, 2021



Convolution neural networks (CNNs) have succeeded in compressive image sensing. However, due to the inductive bias of locality and weight sharing, the convolution operations demonstrate the intrinsic limitations in modeling the long-range dependency. Transformer, designed initially as a sequence-to-sequence model, excels at capturing global contexts due to the self-attention-based architectures even though it may be equipped with limited localization abilities. This paper proposes CSformer, a hybrid framework that integrates the advantages of leveraging both detailed spatial information from CNN and the global context provided by transformer for enhanced representation learning. The proposed approach is an end-to-end compressive image sensing method, composed of adaptive sampling and recovery. In the sampling module, images are measured block-by-block by the learned sampling matrix. In the reconstruction stage, the measurement is projected into dual stems. One is the CNN stem for modeling the neighborhood relationships by convolution, and the other is the transformer stem for adopting global self-attention mechanism. The dual branches structure is concurrent, and the local features and global representations are fused under different resolutions to maximize the complementary of features. Furthermore, we explore a progressive strategy and window-based transformer block to reduce the parameter and computational complexity. The experimental results demonstrate the effectiveness of the dedicated transformer-based architecture for compressive sensing, which achieves superior performance compared to state-of-the-art methods on different datasets.
Unpaired Image Enhancement with Quality-Attention Generative Adversarial Network
Dec 30, 2020



In this work, we aim to learn an unpaired image enhancement model, which can enrich low-quality images with the characteristics of high-quality images provided by users. We propose a quality attention generative adversarial network (QAGAN) trained on unpaired data based on the bidirectional Generative Adversarial Network (GAN) embedded with a quality attention module (QAM). The key novelty of the proposed QAGAN lies in the injected QAM for the generator such that it learns domain-relevant quality attention directly from the two domains. More specifically, the proposed QAM allows the generator to effectively select semantic-related characteristics from the spatial-wise and adaptively incorporate style-related attributes from the channel-wise, respectively. Therefore, in our proposed QAGAN, not only discriminators but also the generator can directly access both domains which significantly facilitates the generator to learn the mapping function. Extensive experimental results show that, compared with the state-of-the-art methods based on unpaired learning, our proposed method achieves better performance in both objective and subjective evaluations.
Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network
Dec 30, 2020



Improving the aesthetic quality of images is challenging and eager for the public. To address this problem, most existing algorithms are based on supervised learning methods to learn an automatic photo enhancer for paired data, which consists of low-quality photos and corresponding expert-retouched versions. However, the style and characteristics of photos retouched by experts may not meet the needs or preferences of general users. In this paper, we present an unsupervised image enhancement generative adversarial network (UEGAN), which learns the corresponding image-to-image mapping from a set of images with desired characteristics in an unsupervised manner, rather than learning on a large number of paired images. The proposed model is based on single deep GAN which embeds the modulation and attention mechanisms to capture richer global and local features. Based on the proposed model, we introduce two losses to deal with the unsupervised image enhancement: (1) fidelity loss, which is defined as a L2 regularization in the feature domain of a pre-trained VGG network to ensure the content between the enhanced image and the input image is the same, and (2) quality loss that is formulated as a relativistic hinge adversarial loss to endow the input image the desired characteristics. Both quantitative and qualitative results show that the proposed model effectively improves the aesthetic quality of images. Our code is available at: https://github.com/eezkni/UEGAN.