 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhao Zhou
Efficient scene text image super-resolution with semantic guidance
Mar 20, 2024




Scene text image super-resolution has significantly improved the accuracy of scene text recognition. However, many existing methods emphasize performance over efficiency and ignore the practical need for lightweight solutions in deployment scenarios. Faced with the issues, our work proposes an efficient framework called SGENet to facilitate deployment on resource-limited platforms. SGENet contains two branches: super-resolution branch and semantic guidance branch. We apply a lightweight pre-trained recognizer as a semantic extractor to enhance the understanding of text information. Meanwhile, we design the visual-semantic alignment module to achieve bidirectional alignment between image features and semantics, resulting in the generation of highquality prior guidance. We conduct extensive experiments on benchmark dataset, and the proposed SGENet achieves excellent performance with fewer computational costs. Code is available at https://github.com/SijieLiu518/SGENet
Aggregated Text Transformer for Scene Text Detection
Nov 25, 2022


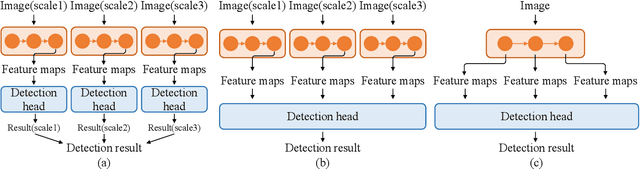
This paper explores the multi-scale aggregation strategy for scene text detection in natural images. We present the Aggregated Text TRansformer(ATTR), which is designed to represent texts in scene images with a multi-scale self-attention mechanism. Starting from the image pyramid with multiple resolutions, the features are first extracted at different scales with shared weight and then fed into an encoder-decoder architecture of Transformer. The multi-scale image representations are robust and contain rich information on text contents of various sizes. The text Transformer aggregates these features to learn the interaction across different scales and improve text representation. The proposed method detects scene texts by representing each text instance as an individual binary mask, which is tolerant of curve texts and regions with dense instances. Extensive experiments on public scene text detection datasets demonstrate the effectiveness of the proposed framework.
Progressive Scene Text Erasing with Self-Supervision
Jul 23, 2022


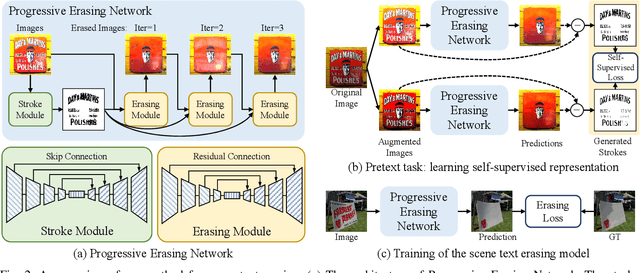
Scene text erasing seeks to erase text contents from scene images and current state-of-the-art text erasing models are trained on large-scale synthetic data. Although data synthetic engines can provide vast amounts of annotated training samples, there are differences between synthetic and real-world data. In this paper, we employ self-supervision for feature representation on unlabeled real-world scene text images. A novel pretext task is designed to keep consistent among text stroke masks of image variants. We design the Progressive Erasing Network in order to remove residual texts. The scene text is erased progressively by leveraging the intermediate generated results which provide the foundation for subsequent higher quality results. Experiments show that our method significantly improves the generalization of the text erasing task and achieves state-of-the-art performance on public benchmarks.
Document Layout Analysis with Aesthetic-Guided Image Augmentation
Nov 27, 2021



Document layout analysis (DLA) plays an important role in information extraction and document understanding. At present, document layout analysis has reached a milestone achievement, however, document layout analysis of non-Manhattan is still a challenge. In this paper, we propose an image layer modeling method to tackle this challenge. To measure the proposed image layer modeling method, we propose a manually-labeled non-Manhattan layout fine-grained segmentation dataset named FPD. As far as we know, FPD is the first manually-labeled non-Manhattan layout fine-grained segmentation dataset. To effectively extract fine-grained features of documents, we propose an edge embedding network named L-E^3Net. Experimental results prove that our proposed image layer modeling method can better deal with the fine-grained segmented document of the non-Manhattan layout.
Curve Text Detection with Local Segmentation Network and Curve Connection
Mar 23, 2019
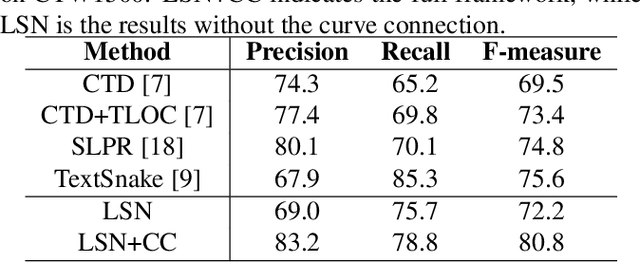

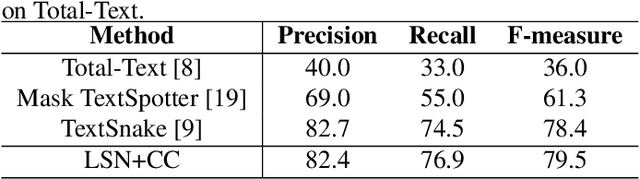
Curve text or arbitrary shape text is very common in real-world scenarios. In this paper, we propose a novel framework with the local segmentation network (LSN) followed by the curve connection to detect text in horizontal, oriented and curved forms. The LSN is composed of two elements, i.e., proposal generation to get the horizontal rectangle proposals with high overlap with text and text segmentation to find the arbitrary shape text region within proposals. The curve connection is then designed to connect the local mask to the detection results. We conduct experiments using the proposed framework on two real-world curve text detection datasets and demonstrate the effectiveness over previous approaches.