 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhehao Zhang
A quality assurance framework for real-time monitoring of deep learning segmentation models in radiotherapy
May 19, 2023
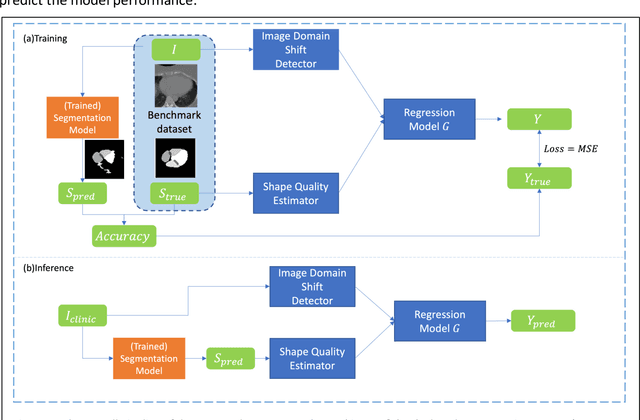
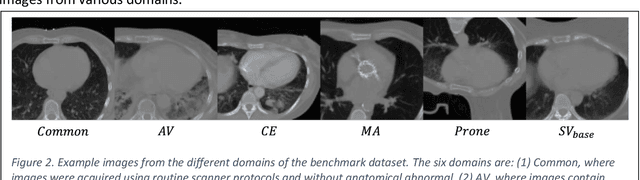
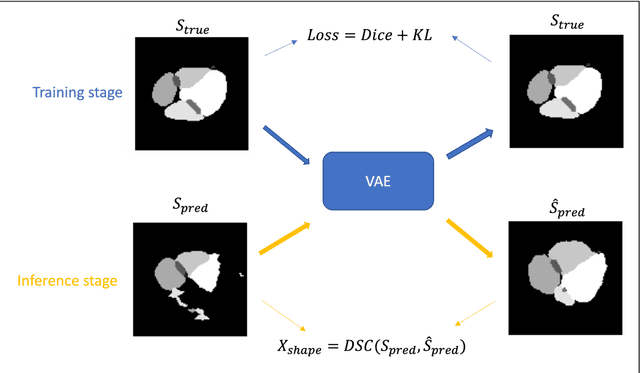
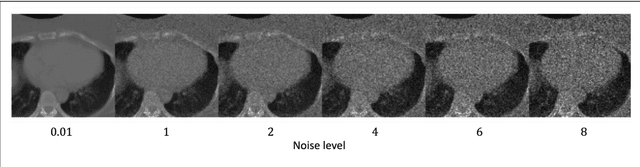
To safely deploy deep learning models in the clinic, a quality assurance framework is needed for routine or continuous monitoring of input-domain shift and the models' performance without ground truth contours. In this work, cardiac substructure segmentation was used as an example task to establish a QA framework. A benchmark dataset consisting of Computed Tomography (CT) images along with manual cardiac delineations of 241 patients were collected, including one 'common' image domain and five 'uncommon' domains. Segmentation models were tested on the benchmark dataset for an initial evaluation of model capacity and limitations. An image domain shift detector was developed by utilizing a trained Denoising autoencoder (DAE) and two hand-engineered features. Another Variational Autoencoder (VAE) was also trained to estimate the shape quality of the auto-segmentation results. Using the extracted features from the image/segmentation pair as inputs, a regression model was trained to predict the per-patient segmentation accuracy, measured by Dice coefficient similarity (DSC). The framework was tested across 19 segmentation models to evaluate the generalizability of the entire framework. As results, the predicted DSC of regression models achieved a mean absolute error (MAE) ranging from 0.036 to 0.046 with an averaged MAE of 0.041. When tested on the benchmark dataset, the performances of all segmentation models were not significantly affected by scanning parameters: FOV, slice thickness and reconstructions kernels. For input images with Poisson noise, CNN-based segmentation models demonstrated a decreased DSC ranging from 0.07 to 0.41, while the transformer-based model was not significantly affected.
Can Large Language Models Transform Computational Social Science?
Apr 12, 2023
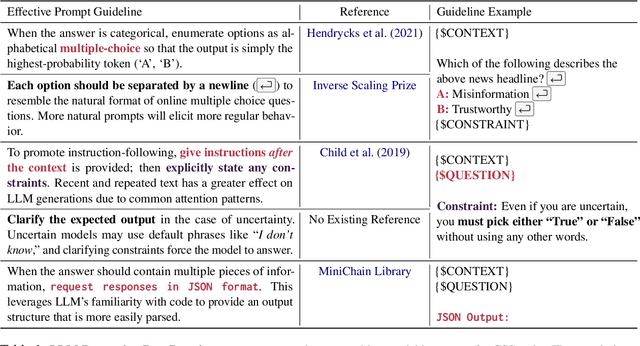
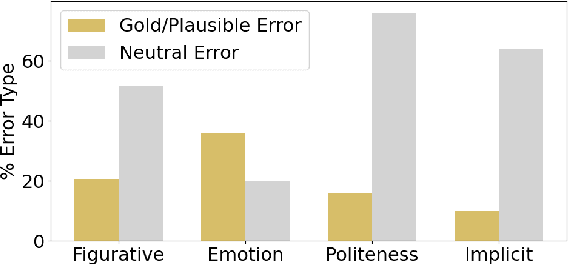
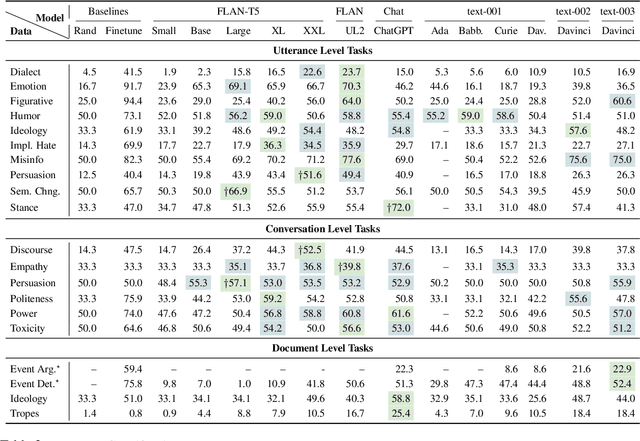
Large Language Models (LLMs) like ChatGPT are capable of successfully performing many language processing tasks zero-shot (without the need for training data). If this capacity also applies to the coding of social phenomena like persuasiveness and political ideology, then LLMs could effectively transform Computational Social Science (CSS). This work provides a road map for using LLMs as CSS tools. Towards this end, we contribute a set of prompting best practices and an extensive evaluation pipeline to measure the zero-shot performance of 13 language models on 24 representative CSS benchmarks. On taxonomic labeling tasks (classification), LLMs fail to outperform the best fine-tuned models but still achieve fair levels of agreement with humans. On free-form coding tasks (generation), LLMs produce explanations that often exceed the quality of crowdworkers' gold references. We conclude that today's LLMs can radically augment the CSS research pipeline in two ways: (1) serving as zero-shot data annotators on human annotation teams, and (2) bootstrapping challenging creative generation tasks (e.g., explaining the hidden meaning behind text). In summary, LLMs can significantly reduce costs and increase efficiency of social science analysis in partnership with humans.