 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhen Fan
HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations
Mar 06, 2024
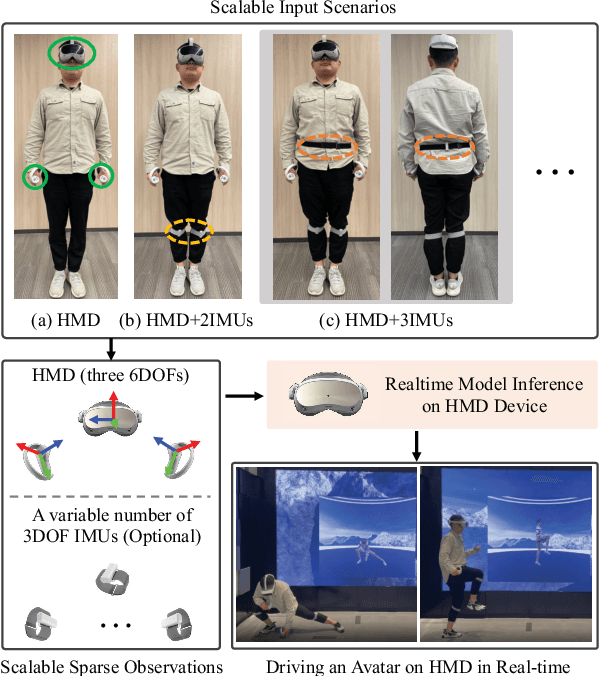
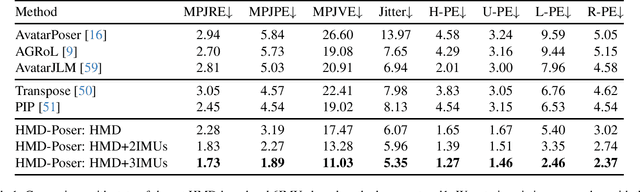
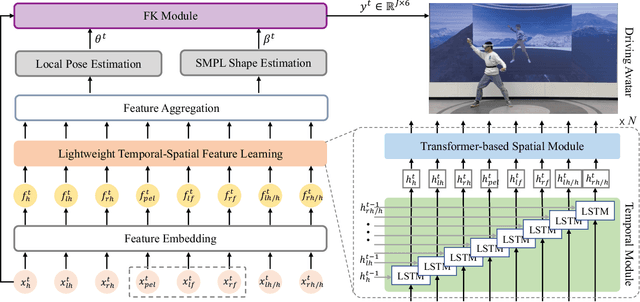
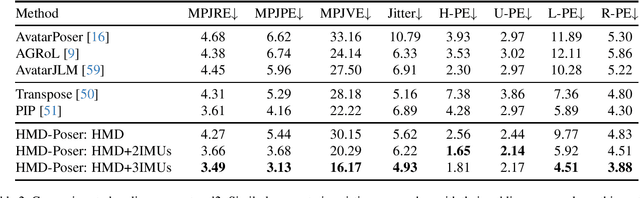
It is especially challenging to achieve real-time human motion tracking on a standalone VR Head-Mounted Display (HMD) such as Meta Quest and PICO. In this paper, we propose HMD-Poser, the first unified approach to recover full-body motions using scalable sparse observations from HMD and body-worn IMUs. In particular, it can support a variety of input scenarios, such as HMD, HMD+2IMUs, HMD+3IMUs, etc. The scalability of inputs may accommodate users' choices for both high tracking accuracy and easy-to-wear. A lightweight temporal-spatial feature learning network is proposed in HMD-Poser to guarantee that the model runs in real-time on HMDs. Furthermore, HMD-Poser presents online body shape estimation to improve the position accuracy of body joints. Extensive experimental results on the challenging AMASS dataset show that HMD-Poser achieves new state-of-the-art results in both accuracy and real-time performance. We also build a new free-dancing motion dataset to evaluate HMD-Poser's on-device performance and investigate the performance gap between synthetic data and real-captured sensor data. Finally, we demonstrate our HMD-Poser with a real-time Avatar-driving application on a commercial HMD. Our code and free-dancing motion dataset are available https://pico-ai-team.github.io/hmd-poser
Building Retrieval Systems for the ClueWeb22-B Corpus
Feb 06, 2024The ClueWeb22 dataset containing nearly 10 billion documents was released in 2022 to support academic and industry research. The goal of this project was to build retrieval baselines for the English section of the "super head" part (category B) of this dataset. These baselines can then be used by the research community to compare their systems and also to generate data to train/evaluate new retrieval and ranking algorithms. The report covers sparse and dense first stage retrievals as well as neural rerankers that were implemented for this dataset. These systems are available as a service on a Carnegie Mellon University cluster.
Combating Adversarial Attacks with Multi-Agent Debate
Jan 11, 2024While state-of-the-art language models have achieved impressive results, they remain susceptible to inference-time adversarial attacks, such as adversarial prompts generated by red teams arXiv:2209.07858. One approach proposed to improve the general quality of language model generations is multi-agent debate, where language models self-evaluate through discussion and feedback arXiv:2305.14325. We implement multi-agent debate between current state-of-the-art language models and evaluate models' susceptibility to red team attacks in both single- and multi-agent settings. We find that multi-agent debate can reduce model toxicity when jailbroken or less capable models are forced to debate with non-jailbroken or more capable models. We also find marginal improvements through the general usage of multi-agent interactions. We further perform adversarial prompt content classification via embedding clustering, and analyze the susceptibility of different models to different types of attack topics.
A Self-enhancement Approach for Domain-specific Chatbot Training via Knowledge Mining and Digest
Nov 17, 2023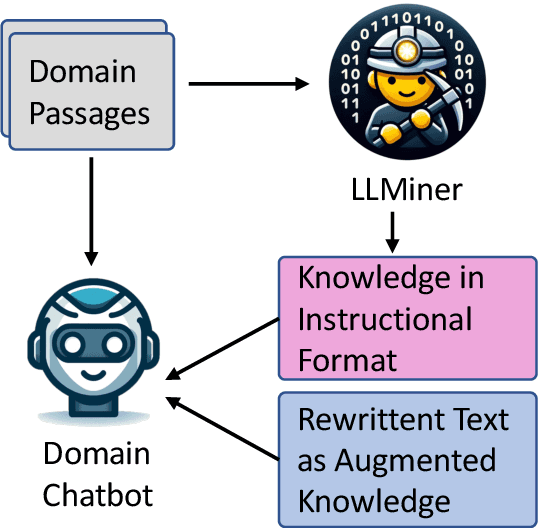
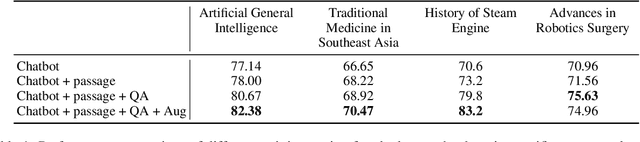
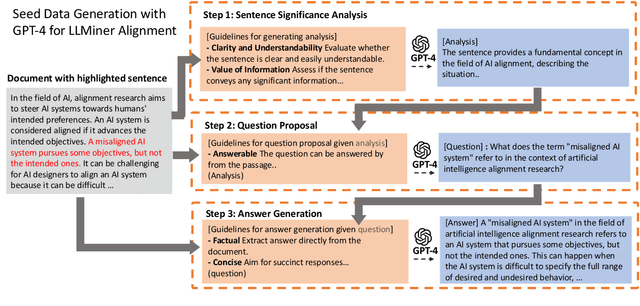
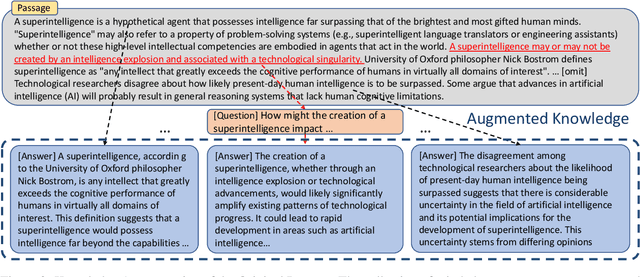
Large Language Models (LLMs), despite their great power in language generation, often encounter challenges when dealing with intricate and knowledge-demanding queries in specific domains. This paper introduces a novel approach to enhance LLMs by effectively extracting the relevant knowledge from domain-specific textual sources, and the adaptive training of a chatbot with domain-specific inquiries. Our two-step approach starts from training a knowledge miner, namely LLMiner, which autonomously extracts Question-Answer pairs from relevant documents through a chain-of-thought reasoning process. Subsequently, we blend the mined QA pairs with a conversational dataset to fine-tune the LLM as a chatbot, thereby enriching its domain-specific expertise and conversational capabilities. We also developed a new evaluation benchmark which comprises four domain-specific text corpora and associated human-crafted QA pairs for testing. Our model shows remarkable performance improvement over generally aligned LLM and surpasses domain-adapted models directly fine-tuned on domain corpus. In particular, LLMiner achieves this with minimal human intervention, requiring only 600 seed instances, thereby providing a pathway towards self-improvement of LLMs through model-synthesized training data.
Localize, Group, and Select: Boosting Text-VQA by Scene Text Modeling
Aug 20, 2021


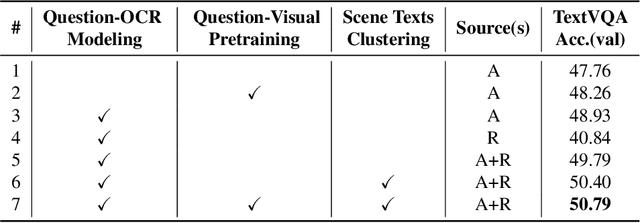
As an important task in multimodal context understanding, Text-VQA (Visual Question Answering) aims at question answering through reading text information in images. It differentiates from the original VQA task as Text-VQA requires large amounts of scene-text relationship understanding, in addition to the cross-modal grounding capability. In this paper, we propose Localize, Group, and Select (LOGOS), a novel model which attempts to tackle this problem from multiple aspects. LOGOS leverages two grounding tasks to better localize the key information of the image, utilizes scene text clustering to group individual OCR tokens, and learns to select the best answer from different sources of OCR (Optical Character Recognition) texts. Experiments show that LOGOS outperforms previous state-of-the-art methods on two Text-VQA benchmarks without using additional OCR annotation data. Ablation studies and analysis demonstrate the capability of LOGOS to bridge different modalities and better understand scene text.