 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhen Wu
Emotion-Anchored Contrastive Learning Framework for Emotion Recognition in Conversation
Mar 29, 2024
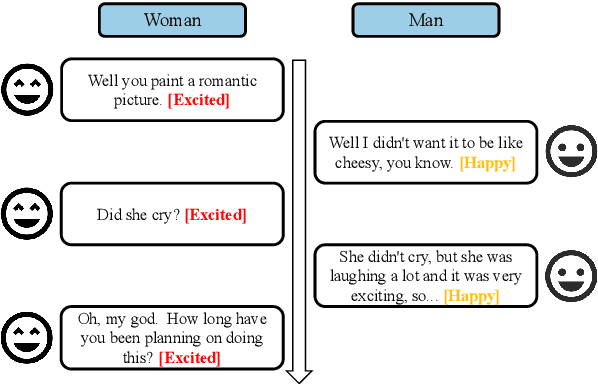
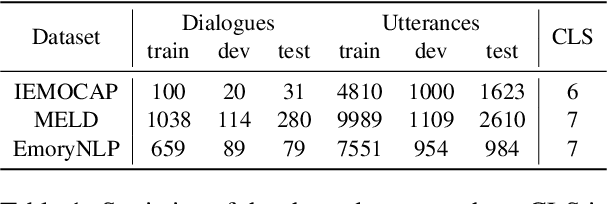
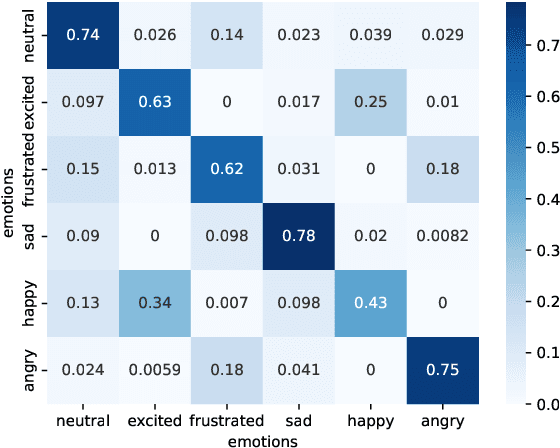
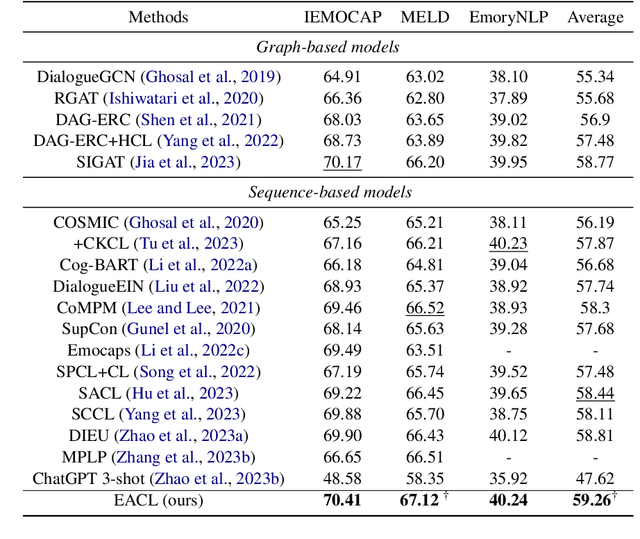
Emotion Recognition in Conversation (ERC) involves detecting the underlying emotion behind each utterance within a conversation. Effectively generating representations for utterances remains a significant challenge in this task. Recent works propose various models to address this issue, but they still struggle with differentiating similar emotions such as excitement and happiness. To alleviate this problem, We propose an Emotion-Anchored Contrastive Learning (EACL) framework that can generate more distinguishable utterance representations for similar emotions. To achieve this, we utilize label encodings as anchors to guide the learning of utterance representations and design an auxiliary loss to ensure the effective separation of anchors for similar emotions. Moreover, an additional adaptation process is proposed to adapt anchors to serve as effective classifiers to improve classification performance. Across extensive experiments, our proposed EACL achieves state-of-the-art emotion recognition performance and exhibits superior performance on similar emotions. Our code is available at https://github.com/Yu-Fangxu/EACL.
Knowledge-aware Dual-side Attribute-enhanced Recommendation
Mar 24, 2024\textit{Knowledge-aware} recommendation methods (KGR) based on \textit{graph neural networks} (GNNs) and \textit{contrastive learning} (CL) have achieved promising performance. However, they fall short in modeling fine-grained user preferences and further fail to leverage the \textit{preference-attribute connection} to make predictions, leading to sub-optimal performance. To address the issue, we propose a method named \textit{\textbf{K}nowledge-aware \textbf{D}ual-side \textbf{A}ttribute-enhanced \textbf{R}ecommendation} (KDAR). Specifically, we build \textit{user preference representations} and \textit{attribute fusion representations} upon the attribute information in knowledge graphs, which are utilized to enhance \textit{collaborative filtering} (CF) based user and item representations, respectively. To discriminate the contribution of each attribute in these two types of attribute-based representations, a \textit{multi-level collaborative alignment contrasting} mechanism is proposed to align the importance of attributes with CF signals. Experimental results on four benchmark datasets demonstrate the superiority of KDAR over several state-of-the-art baselines. Further analyses verify the effectiveness of our method. The code of KDAR is released at: \href{https://github.com/TJTP/KDAR}{https://github.com/TJTP/KDAR}.
Dr3: Ask Large Language Models Not to Give Off-Topic Answers in Open Domain Multi-Hop Question Answering
Mar 19, 2024
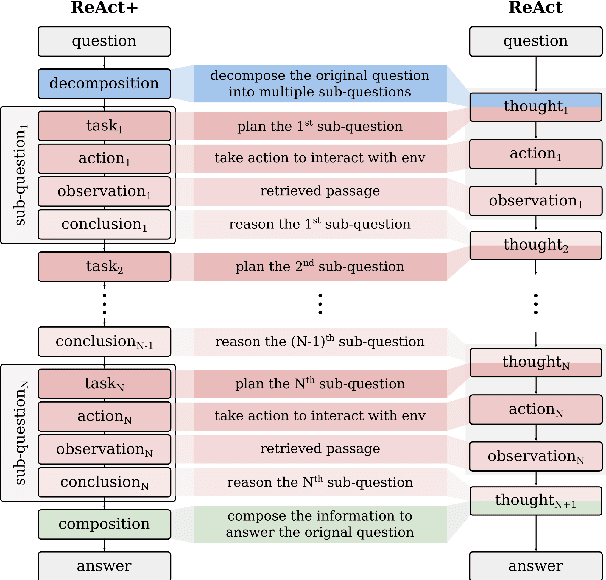
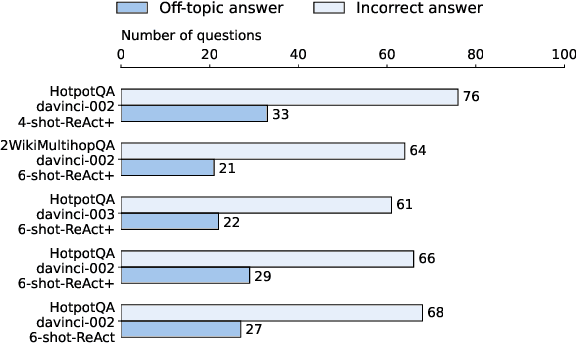
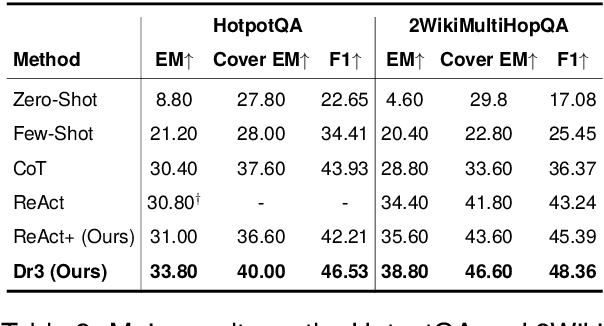
Open Domain Multi-Hop Question Answering (ODMHQA) plays a crucial role in Natural Language Processing (NLP) by aiming to answer complex questions through multi-step reasoning over retrieved information from external knowledge sources. Recently, Large Language Models (LLMs) have demonstrated remarkable performance in solving ODMHQA owing to their capabilities including planning, reasoning, and utilizing tools. However, LLMs may generate off-topic answers when attempting to solve ODMHQA, namely the generated answers are irrelevant to the original questions. This issue of off-topic answers accounts for approximately one-third of incorrect answers, yet remains underexplored despite its significance. To alleviate this issue, we propose the Discriminate->Re-Compose->Re- Solve->Re-Decompose (Dr3) mechanism. Specifically, the Discriminator leverages the intrinsic capabilities of LLMs to judge whether the generated answers are off-topic. In cases where an off-topic answer is detected, the Corrector performs step-wise revisions along the reversed reasoning chain (Re-Compose->Re-Solve->Re-Decompose) until the final answer becomes on-topic. Experimental results on the HotpotQA and 2WikiMultiHopQA datasets demonstrate that our Dr3 mechanism considerably reduces the occurrence of off-topic answers in ODMHQA by nearly 13%, improving the performance in Exact Match (EM) by nearly 3% compared to the baseline method without the Dr3 mechanism.
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
Feb 15, 2024Multimodal large language models (MLLMs) have attracted increasing attention in the past few years, but they may still generate descriptions that include objects not present in the corresponding images, a phenomenon known as object hallucination. To eliminate hallucinations, existing methods manually annotate paired responses with and without hallucinations, and then employ various alignment algorithms to improve the alignment capability between images and text. However, they not only demand considerable computation resources during the finetuning stage but also require expensive human annotation to construct paired data needed by the alignment algorithms. To address these issues, we borrow the idea of unlearning and propose an efficient fine-grained unlearning framework (EFUF), which can eliminate hallucinations without the need for paired data. Extensive experiments show that our method consistently reduces hallucinations while preserving the generation quality with modest computational overhead. Our code and datasets will be publicly available.
Make BERT-based Chinese Spelling Check Model Enhanced by Layerwise Attention and Gaussian Mixture Model
Dec 27, 2023BERT-based models have shown a remarkable ability in the Chinese Spelling Check (CSC) task recently. However, traditional BERT-based methods still suffer from two limitations. First, although previous works have identified that explicit prior knowledge like Part-Of-Speech (POS) tagging can benefit in the CSC task, they neglected the fact that spelling errors inherent in CSC data can lead to incorrect tags and therefore mislead models. Additionally, they ignored the correlation between the implicit hierarchical information encoded by BERT's intermediate layers and different linguistic phenomena. This results in sub-optimal accuracy. To alleviate the above two issues, we design a heterogeneous knowledge-infused framework to strengthen BERT-based CSC models. To incorporate explicit POS knowledge, we utilize an auxiliary task strategy driven by Gaussian mixture model. Meanwhile, to incorporate implicit hierarchical linguistic knowledge within the encoder, we propose a novel form of n-gram-based layerwise self-attention to generate a multilayer representation. Experimental results show that our proposed framework yields a stable performance boost over four strong baseline models and outperforms the previous state-of-the-art methods on two datasets.
* 10 pages, 4 figures, 2023 International Joint Conference on Neural Networks (IJCNN)
FOAL: Fine-grained Contrastive Learning for Cross-domain Aspect Sentiment Triplet Extraction
Nov 17, 2023Aspect Sentiment Triplet Extraction (ASTE) has achieved promising results while relying on sufficient annotation data in a specific domain. However, it is infeasible to annotate data for each individual domain. We propose to explore ASTE in the cross-domain setting, which transfers knowledge from a resource-rich source domain to a resource-poor target domain, thereby alleviating the reliance on labeled data in the target domain. To effectively transfer the knowledge across domains and extract the sentiment triplets accurately, we propose a method named Fine-grained cOntrAstive Learning (FOAL) to reduce the domain discrepancy and preserve the discriminability of each category. Experiments on six transfer pairs show that FOAL achieves 6% performance gains and reduces the domain discrepancy significantly compared with strong baselines. Our code will be publicly available once accepted.
M2DF: Multi-grained Multi-curriculum Denoising Framework for Multimodal Aspect-based Sentiment Analysis
Oct 23, 2023



Multimodal Aspect-based Sentiment Analysis (MABSA) is a fine-grained Sentiment Analysis task, which has attracted growing research interests recently. Existing work mainly utilizes image information to improve the performance of MABSA task. However, most of the studies overestimate the importance of images since there are many noise images unrelated to the text in the dataset, which will have a negative impact on model learning. Although some work attempts to filter low-quality noise images by setting thresholds, relying on thresholds will inevitably filter out a lot of useful image information. Therefore, in this work, we focus on whether the negative impact of noisy images can be reduced without modifying the data. To achieve this goal, we borrow the idea of Curriculum Learning and propose a Multi-grained Multi-curriculum Denoising Framework (M2DF), which can achieve denoising by adjusting the order of training data. Extensive experimental results show that our framework consistently outperforms state-of-the-art work on three sub-tasks of MABSA.
DRIN: Dynamic Relation Interactive Network for Multimodal Entity Linking
Oct 09, 2023


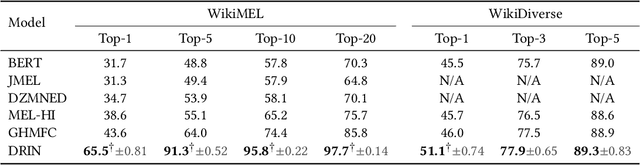
Multimodal Entity Linking (MEL) is a task that aims to link ambiguous mentions within multimodal contexts to referential entities in a multimodal knowledge base. Recent methods for MEL adopt a common framework: they first interact and fuse the text and image to obtain representations of the mention and entity respectively, and then compute the similarity between them to predict the correct entity. However, these methods still suffer from two limitations: first, as they fuse the features of text and image before matching, they cannot fully exploit the fine-grained alignment relations between the mention and entity. Second, their alignment is static, leading to low performance when dealing with complex and diverse data. To address these issues, we propose a novel framework called Dynamic Relation Interactive Network (DRIN) for MEL tasks. DRIN explicitly models four different types of alignment between a mention and entity and builds a dynamic Graph Convolutional Network (GCN) to dynamically select the corresponding alignment relations for different input samples. Experiments on two datasets show that DRIN outperforms state-of-the-art methods by a large margin, demonstrating the effectiveness of our approach.
Towards Better Chain-of-Thought Prompting Strategies: A Survey
Oct 08, 2023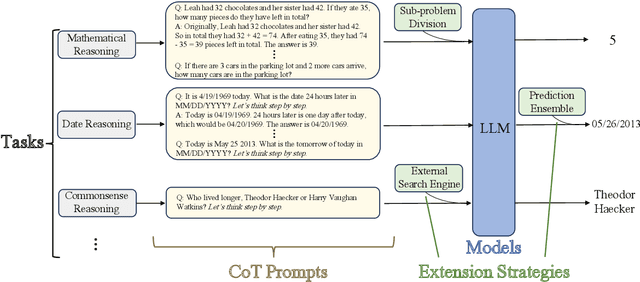
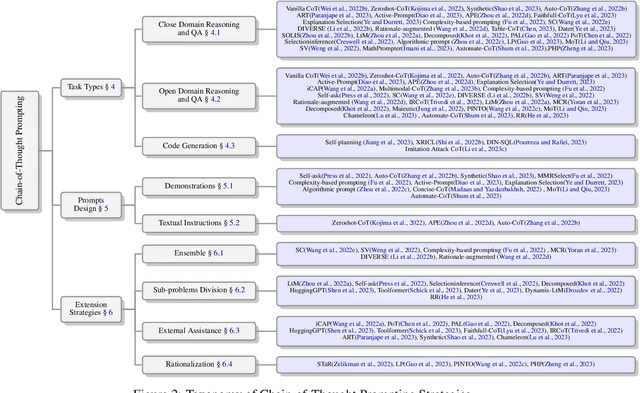

Chain-of-Thought (CoT), a step-wise and coherent reasoning chain, shows its impressive strength when used as a prompting strategy for large language models (LLM). Recent years, the prominent effect of CoT prompting has attracted emerging research. However, there still lacks of a systematic summary about key factors of CoT prompting and comprehensive guide for prompts utilizing. For a deeper understanding about CoT prompting, we survey on a wide range of current research, presenting a systematic and comprehensive analysis on several factors that may influence the effect of CoT prompting, and introduce how to better apply it in different applications under these discussions. We further analyze the challenges and propose some future directions about CoT prompting. This survey could provide an overall reference on related research.
Dynamic Demonstrations Controller for In-Context Learning
Sep 30, 2023In-Context Learning (ICL) is a new paradigm for natural language processing (NLP), where a large language model (LLM) observes a small number of demonstrations and a test instance as its input, and directly makes predictions without updating model parameters. Previous studies have revealed that ICL is sensitive to the selection and the ordering of demonstrations. However, there are few studies regarding the impact of the demonstration number on the ICL performance within a limited input length of LLM, because it is commonly believed that the number of demonstrations is positively correlated with model performance. In this paper, we found this conclusion does not always hold true. Through pilot experiments, we discover that increasing the number of demonstrations does not necessarily lead to improved performance. Building upon this insight, we propose a Dynamic Demonstrations Controller (D$^2$Controller), which can improve the ICL performance by adjusting the number of demonstrations dynamically. The experimental results show that D$^2$Controller yields a 5.4% relative improvement on eight different sizes of LLMs across ten datasets. Moreover, we also extend our method to previous ICL models and achieve competitive results.