 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhengbao He
Friendly Sharpness-Aware Minimization
Mar 19, 2024
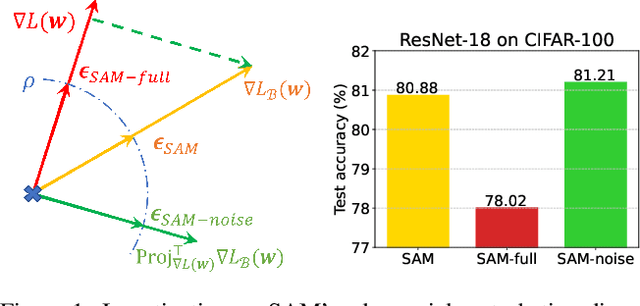
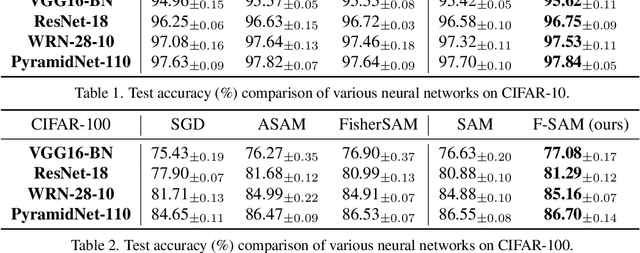
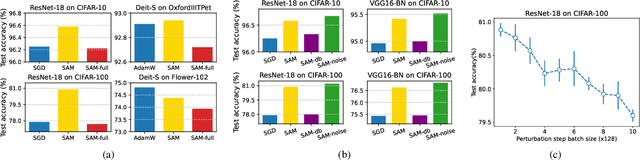
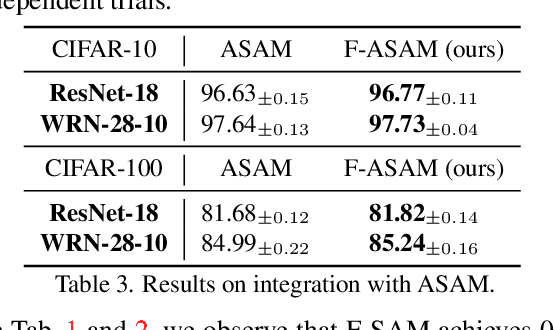
Sharpness-Aware Minimization (SAM) has been instrumental in improving deep neural network training by minimizing both training loss and loss sharpness. Despite the practical success, the mechanisms behind SAM's generalization enhancements remain elusive, limiting its progress in deep learning optimization. In this work, we investigate SAM's core components for generalization improvement and introduce "Friendly-SAM" (F-SAM) to further enhance SAM's generalization. Our investigation reveals the key role of batch-specific stochastic gradient noise within the adversarial perturbation, i.e., the current minibatch gradient, which significantly influences SAM's generalization performance. By decomposing the adversarial perturbation in SAM into full gradient and stochastic gradient noise components, we discover that relying solely on the full gradient component degrades generalization while excluding it leads to improved performance. The possible reason lies in the full gradient component's increase in sharpness loss for the entire dataset, creating inconsistencies with the subsequent sharpness minimization step solely on the current minibatch data. Inspired by these insights, F-SAM aims to mitigate the negative effects of the full gradient component. It removes the full gradient estimated by an exponentially moving average (EMA) of historical stochastic gradients, and then leverages stochastic gradient noise for improved generalization. Moreover, we provide theoretical validation for the EMA approximation and prove the convergence of F-SAM on non-convex problems. Extensive experiments demonstrate the superior generalization performance and robustness of F-SAM over vanilla SAM. Code is available at https://github.com/nblt/F-SAM.
Investigating Catastrophic Overfitting in Fast Adversarial Training: A Self-fitting Perspective
Feb 23, 2023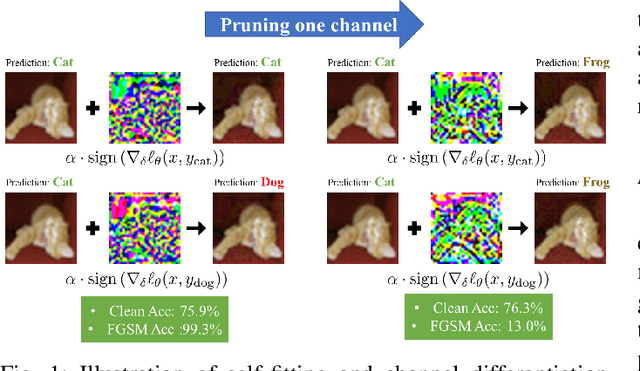
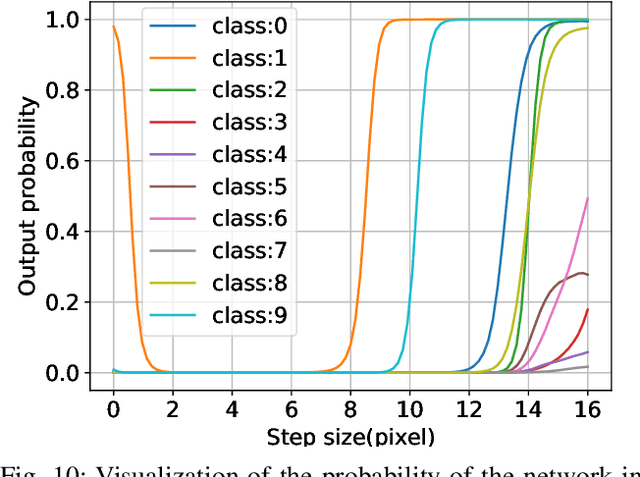
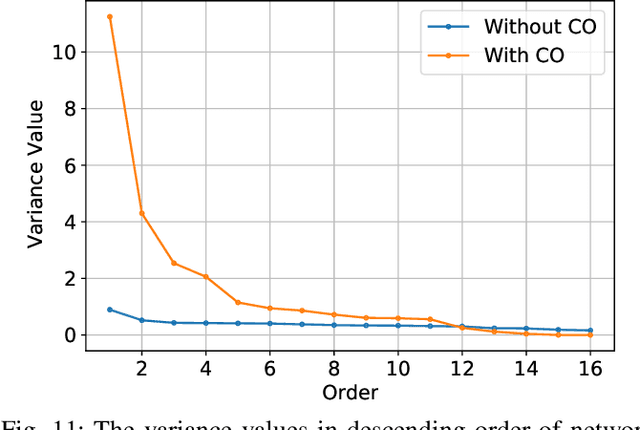
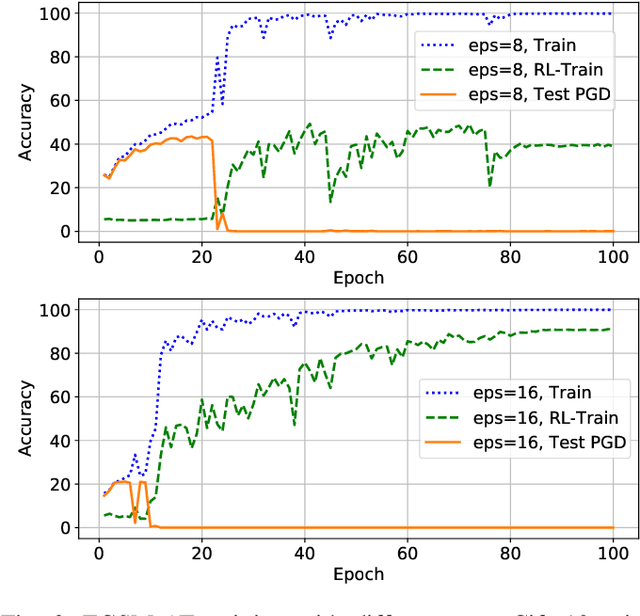
Although fast adversarial training provides an efficient approach for building robust networks, it may suffer from a serious problem known as catastrophic overfitting (CO), where the multi-step robust accuracy suddenly collapses to zero. In this paper, we for the first time decouple the FGSM examples into data-information and self-information, which reveals an interesting phenomenon called "self-fitting". Self-fitting, i.e., DNNs learn the self-information embedded in single-step perturbations, naturally leads to the occurrence of CO. When self-fitting occurs, the network experiences an obvious "channel differentiation" phenomenon that some convolution channels accounting for recognizing self-information become dominant, while others for data-information are suppressed. In this way, the network learns to only recognize images with sufficient self-information and loses generalization ability to other types of data. Based on self-fitting, we provide new insight into the existing methods to mitigate CO and extend CO to multi-step adversarial training. Our findings reveal a self-learning mechanism in adversarial training and open up new perspectives for suppressing different kinds of information to mitigate CO.
Universal Adversarial Attack on Attention and the Resulting Dataset DAmageNet
Jan 16, 2020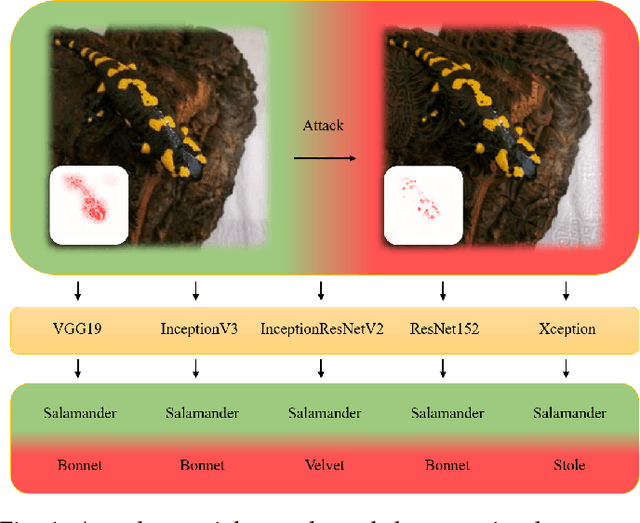
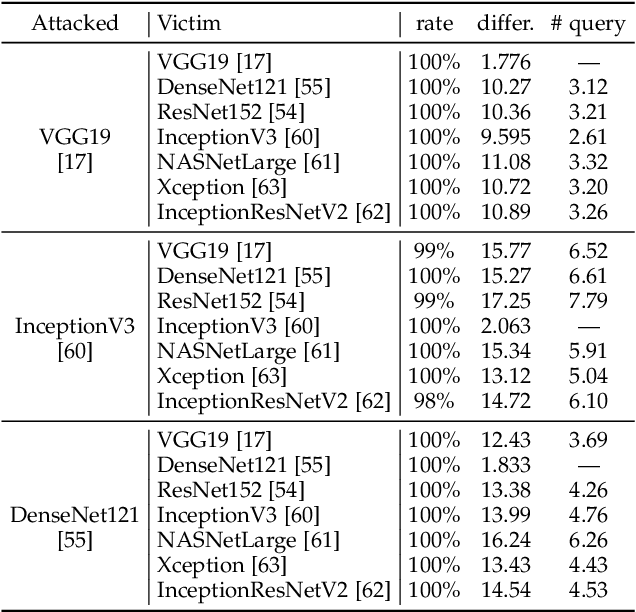

Adversarial attacks on deep neural networks (DNNs) have been found for several years. However, the existing adversarial attacks have high success rates only when the information of the attacked DNN is well-known or could be estimated by structure similarity or massive queries. In this paper, we propose an \emph{Attack on Attention} (AoA), a semantic feature commonly shared by DNNs. The transferability of AoA is quite high. With no more than 10 queries of the decision only, AoA can achieve almost 100\% success rate when attacking on many popular DNNs. Even without query, AoA could keep a surprisingly high attack performance. We apply AoA to generate 96020 adversarial samples from ImageNet to defeat many neural networks, and thus name the dataset as \emph{DAmageNet}. 20 well-trained DNNs are tested on DAmageNet. Without adversarial training, most of the tested DNNs have an error rate over 90\%. DAmageNet is the first universal adversarial dataset and it could serve as a benchmark for robustness testing and adversarial training.
DAmageNet: A Universal Adversarial Dataset
Dec 16, 2019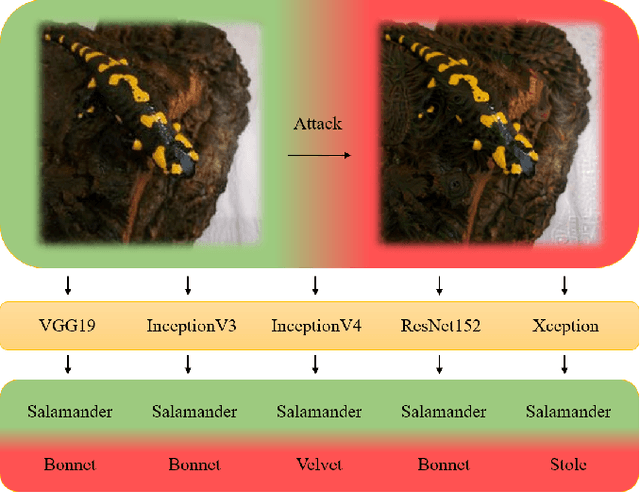
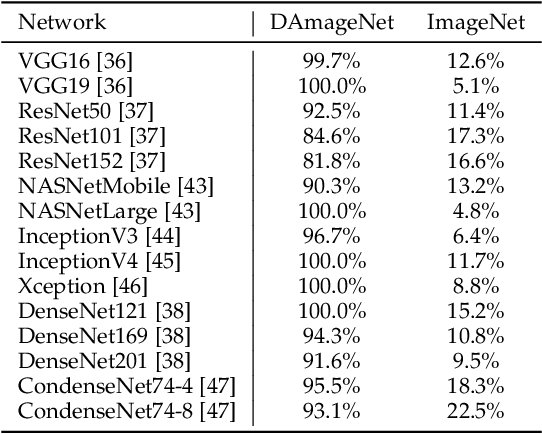

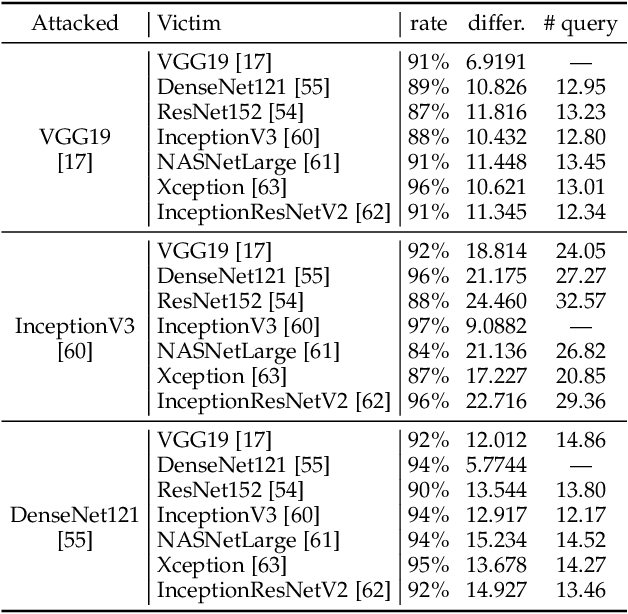
It is now well known that deep neural networks (DNNs) are vulnerable to adversarial attack. Adversarial samples are similar to the clean ones, but are able to cheat the attacked DNN to produce incorrect predictions in high confidence. But most of the existing adversarial attacks have high success rate only when the information of the attacked DNN is well-known or could be estimated by massive queries. A promising way is to generate adversarial samples with high transferability. By this way, we generate 96020 transferable adversarial samples from original ones in ImageNet. The average difference, measured by root means squared deviation, is only around 3.8 on average. However, the adversarial samples are misclassified by various models with an error rate up to 90\%. Since the images are generated independently with the attacked DNNs, this is essentially zero-query adversarial attack. We call the dataset \emph{DAmageNet}, which is the first universal adversarial dataset that beats many models trained in ImageNet. By finding the drawbacks, DAmageNet could serve as a benchmark to study and improve robustness of DNNs. DAmageNet could be downloaded in http://www.pami.sjtu.edu.cn/Show/56/122.