 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhengfeng Lai
MobilityGPT: Enhanced Human Mobility Modeling with a GPT model
Feb 05, 2024
Generative models have shown promising results in capturing human mobility characteristics and generating synthetic trajectories. However, it remains challenging to ensure that the generated geospatial mobility data is semantically realistic, including consistent location sequences, and reflects real-world characteristics, such as constraining on geospatial limits. To address these issues, we reformat human mobility modeling as an autoregressive generation task, leveraging Generative Pre-trained Transformer (GPT). To ensure its controllable generation to alleviate the above challenges, we propose a geospatially-aware generative model, MobilityGPT. We propose a gravity-based sampling method to train a transformer for semantic sequence similarity. Then, we constrained the training process via a road connectivity matrix that provides the connectivity of sequences in trajectory generation, thereby keeping generated trajectories in geospatial limits. Lastly, we constructed a Reinforcement Learning from Trajectory Feedback (RLTF) to minimize the travel distance between training and the synthetically generated trajectories. Our experiments on real-world datasets demonstrate that MobilityGPT outperforms state-of-the-art methods in generating high-quality mobility trajectories that are closest to real data in terms of origin-destination similarity, trip length, travel radius, link, and gravity distributions.
From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
Oct 11, 2023
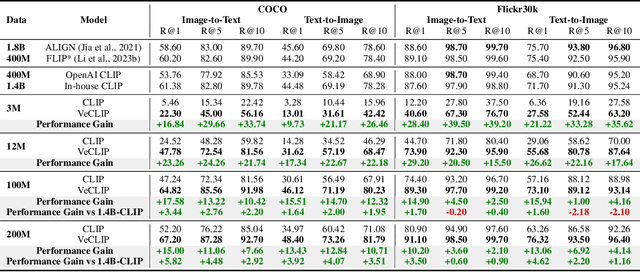
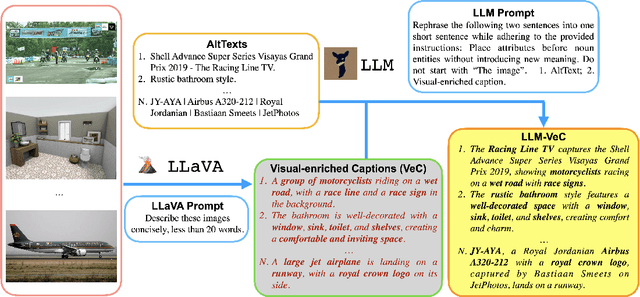
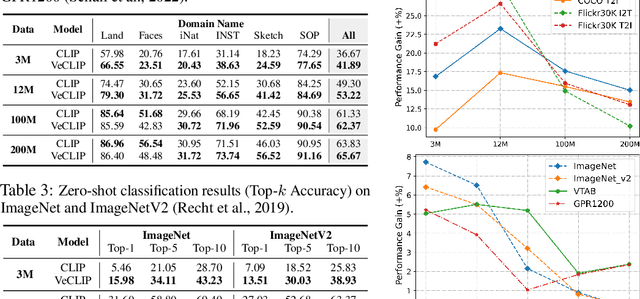
Web-crawled datasets are pivotal to the success of pre-training vision-language models, exemplified by CLIP. However, web-crawled AltTexts can be noisy and potentially irrelevant to images, thereby undermining the crucial image-text alignment. Existing methods for rewriting captions using large language models (LLMs) have shown promise on small, curated datasets like CC3M and CC12M. Nevertheless, their efficacy on massive web-captured captions is constrained by the inherent noise and randomness in such data. In this study, we address this limitation by focusing on two key aspects: data quality and data variety. Unlike recent LLM rewriting techniques, we emphasize exploiting visual concepts and their integration into the captions to improve data quality. For data variety, we propose a novel mixed training scheme that optimally leverages AltTexts alongside newly generated Visual-enriched Captions (VeC). We use CLIP as one example and adapt the method for CLIP training on large-scale web-crawled datasets, named VeCLIP. We conduct a comprehensive evaluation of VeCLIP across small, medium, and large scales of raw data. Our results show significant advantages in image-text alignment and overall model performance, underscoring the effectiveness of VeCLIP in improving CLIP training. For example, VeCLIP achieves a remarkable over 20% improvement in COCO and Flickr30k retrieval tasks under the 12M setting. For data efficiency, we also achieve a notable over 3% improvement while using only 14% of the data employed in the vanilla CLIP and 11% in ALIGN.