 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenghao Peng
SwinTextSpotter v2: Towards Better Synergy for Scene Text Spotting
Jan 15, 2024
End-to-end scene text spotting, which aims to read the text in natural images, has garnered significant attention in recent years. However, recent state-of-the-art methods usually incorporate detection and recognition simply by sharing the backbone, which does not directly take advantage of the feature interaction between the two tasks. In this paper, we propose a new end-to-end scene text spotting framework termed SwinTextSpotter v2, which seeks to find a better synergy between text detection and recognition. Specifically, we enhance the relationship between two tasks using novel Recognition Conversion and Recognition Alignment modules. Recognition Conversion explicitly guides text localization through recognition loss, while Recognition Alignment dynamically extracts text features for recognition through the detection predictions. This simple yet effective design results in a concise framework that requires neither an additional rectification module nor character-level annotations for the arbitrarily-shaped text. Furthermore, the parameters of the detector are greatly reduced without performance degradation by introducing a Box Selection Schedule. Qualitative and quantitative experiments demonstrate that SwinTextSpotter v2 achieved state-of-the-art performance on various multilingual (English, Chinese, and Vietnamese) benchmarks. The code will be available at \href{https://github.com/mxin262/SwinTextSpotterv2}{SwinTextSpotter v2}.
CAT: Closed-loop Adversarial Training for Safe End-to-End Driving
Oct 19, 2023Driving safety is a top priority for autonomous vehicles. Orthogonal to prior work handling accident-prone traffic events by algorithm designs at the policy level, we investigate a Closed-loop Adversarial Training (CAT) framework for safe end-to-end driving in this paper through the lens of environment augmentation. CAT aims to continuously improve the safety of driving agents by training the agent on safety-critical scenarios that are dynamically generated over time. A novel resampling technique is developed to turn log-replay real-world driving scenarios into safety-critical ones via probabilistic factorization, where the adversarial traffic generation is modeled as the multiplication of standard motion prediction sub-problems. Consequently, CAT can launch more efficient physical attacks compared to existing safety-critical scenario generation methods and yields a significantly less computational cost in the iterative learning pipeline. We incorporate CAT into the MetaDrive simulator and validate our approach on hundreds of driving scenarios imported from real-world driving datasets. Experimental results demonstrate that CAT can effectively generate adversarial scenarios countering the agent being trained. After training, the agent can achieve superior driving safety in both log-replay and safety-critical traffic scenarios on the held-out test set. Code and data are available at https://metadriverse.github.io/cat.
ScenarioNet: Open-Source Platform for Large-Scale Traffic Scenario Simulation and Modeling
Jul 02, 2023



Large-scale driving datasets such as Waymo Open Dataset and nuScenes substantially accelerate autonomous driving research, especially for perception tasks such as 3D detection and trajectory forecasting. Since the driving logs in these datasets contain HD maps and detailed object annotations which accurately reflect the real-world complexity of traffic behaviors, we can harvest a massive number of complex traffic scenarios and recreate their digital twins in simulation. Compared to the hand-crafted scenarios often used in existing simulators, data-driven scenarios collected from the real world can facilitate many research opportunities in machine learning and autonomous driving. In this work, we present ScenarioNet, an open-source platform for large-scale traffic scenario modeling and simulation. ScenarioNet defines a unified scenario description format and collects a large-scale repository of real-world traffic scenarios from the heterogeneous data in various driving datasets including Waymo, nuScenes, Lyft L5, and nuPlan datasets. These scenarios can be further replayed and interacted with in multiple views from Bird-Eye-View layout to realistic 3D rendering in MetaDrive simulator. This provides a benchmark for evaluating the safety of autonomous driving stacks in simulation before their real-world deployment. We further demonstrate the strengths of ScenarioNet on large-scale scenario generation, imitation learning, and reinforcement learning in both single-agent and multi-agent settings. Code, demo videos, and website are available at https://metadriverse.github.io/scenarionet.
Guarded Policy Optimization with Imperfect Online Demonstrations
Mar 03, 2023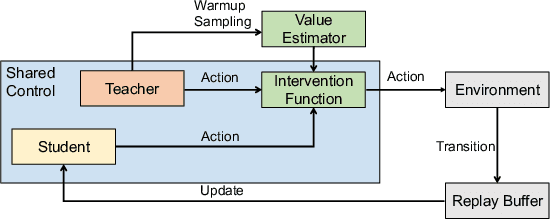


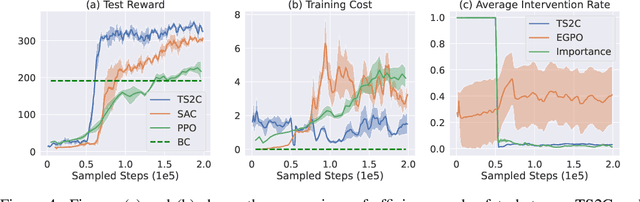
The Teacher-Student Framework (TSF) is a reinforcement learning setting where a teacher agent guards the training of a student agent by intervening and providing online demonstrations. Assuming optimal, the teacher policy has the perfect timing and capability to intervene in the learning process of the student agent, providing safety guarantee and exploration guidance. Nevertheless, in many real-world settings it is expensive or even impossible to obtain a well-performing teacher policy. In this work, we relax the assumption of a well-performing teacher and develop a new method that can incorporate arbitrary teacher policies with modest or inferior performance. We instantiate an Off-Policy Reinforcement Learning algorithm, termed Teacher-Student Shared Control (TS2C), which incorporates teacher intervention based on trajectory-based value estimation. Theoretical analysis validates that the proposed TS2C algorithm attains efficient exploration and substantial safety guarantee without being affected by the teacher's own performance. Experiments on various continuous control tasks show that our method can exploit teacher policies at different performance levels while maintaining a low training cost. Moreover, the student policy surpasses the imperfect teacher policy in terms of higher accumulated reward in held-out testing environments. Code is available at https://metadriverse.github.io/TS2C.
TrafficGen: Learning to Generate Diverse and Realistic Traffic Scenarios
Oct 12, 2022



Diverse and realistic traffic scenarios are crucial for evaluating the AI safety of autonomous driving systems in simulation. This work introduces a data-driven method called TrafficGen for traffic scenario generation. It learns from the fragmented human driving data collected in the real world and then can generate realistic traffic scenarios. TrafficGen is an autoregressive generative model with an encoder-decoder architecture. In each autoregressive iteration, it first encodes the current traffic context with the attention mechanism and then decodes a vehicle's initial state followed by generating its long trajectory. We evaluate the trained model in terms of vehicle placement and trajectories and show substantial improvements over baselines. TrafficGen can be also used to augment existing traffic scenarios, by adding new vehicles and extending the fragmented trajectories. We further demonstrate that importing the generated scenarios into a simulator as interactive training environments improves the performance and the safety of driving policy learned from reinforcement learning. More project resource is available at https://metadriverse.github.io/trafficgen
Human-AI Shared Control via Frequency-based Policy Dissection
May 31, 2022



Human-AI shared control allows human to interact and collaborate with AI to accomplish control tasks in complex environments. Previous Reinforcement Learning (RL) methods attempt the goal-conditioned design to achieve human-controllable policies at the cost of redesigning the reward function and training paradigm. Inspired by the neuroscience approach to investigate the motor cortex in primates, we develop a simple yet effective frequency-based approach called \textit{Policy Dissection} to align the intermediate representation of the learned neural controller with the kinematic attributes of the agent behavior. Without modifying the neural controller or retraining the model, the proposed approach can convert a given RL-trained policy into a human-interactive policy. We evaluate the proposed approach on the RL tasks of autonomous driving and locomotion. The experiments show that human-AI shared control achieved by Policy Dissection in driving task can substantially improve the performance and safety in unseen traffic scenes. With human in the loop, the locomotion robots also exhibit versatile controllable motion skills even though they are only trained to move forward. Our results suggest the promising direction of implementing human-AI shared autonomy through interpreting the learned representation of the autonomous agents. Demo video and code will be made available at https://metadriverse.github.io/policydissect.
Action-Conditioned Contrastive Policy Pretraining
Apr 05, 2022



Deep visuomotor policy learning achieves promising results in control tasks such as robotic manipulation and autonomous driving, where the action is generated from the visual input by the neural policy. However, it requires a huge number of online interactions with the training environment, which limits its real-world application. Compared to the popular unsupervised feature learning for visual recognition, feature pretraining for visuomotor control tasks is much less explored. In this work, we aim to pretrain policy representations for driving tasks using hours-long uncurated YouTube videos. A new contrastive policy pretraining method is developed to learn action-conditioned features from video frames with action pseudo labels. Experiments show that the resulting action-conditioned features bring substantial improvements to the downstream reinforcement learning and imitation learning tasks, outperforming the weights pretrained from previous unsupervised learning methods. Code and models will be made publicly available.
SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition
Mar 19, 2022



End-to-end scene text spotting has attracted great attention in recent years due to the success of excavating the intrinsic synergy of the scene text detection and recognition. However, recent state-of-the-art methods usually incorporate detection and recognition simply by sharing the backbone, which does not directly take advantage of the feature interaction between the two tasks. In this paper, we propose a new end-to-end scene text spotting framework termed SwinTextSpotter. Using a transformer encoder with dynamic head as the detector, we unify the two tasks with a novel Recognition Conversion mechanism to explicitly guide text localization through recognition loss. The straightforward design results in a concise framework that requires neither additional rectification module nor character-level annotation for the arbitrarily-shaped text. Qualitative and quantitative experiments on multi-oriented datasets RoIC13 and ICDAR 2015, arbitrarily-shaped datasets Total-Text and CTW1500, and multi-lingual datasets ReCTS (Chinese) and VinText (Vietnamese) demonstrate SwinTextSpotter significantly outperforms existing methods. Code is available at https://github.com/mxin262/SwinTextSpotter.
Efficient Learning of Safe Driving Policy via Human-AI Copilot Optimization
Feb 17, 2022



Human intervention is an effective way to inject human knowledge into the training loop of reinforcement learning, which can bring fast learning and ensured training safety. Given the very limited budget of human intervention, it remains challenging to design when and how human expert interacts with the learning agent in the training. In this work, we develop a novel human-in-the-loop learning method called Human-AI Copilot Optimization (HACO).To allow the agent's sufficient exploration in the risky environments while ensuring the training safety, the human expert can take over the control and demonstrate how to avoid probably dangerous situations or trivial behaviors. The proposed HACO then effectively utilizes the data both from the trial-and-error exploration and human's partial demonstration to train a high-performing agent. HACO extracts proxy state-action values from partial human demonstration and optimizes the agent to improve the proxy values meanwhile reduce the human interventions. The experiments show that HACO achieves a substantially high sample efficiency in the safe driving benchmark. HACO can train agents to drive in unseen traffic scenarios with a handful of human intervention budget and achieve high safety and generalizability, outperforming both reinforcement learning and imitation learning baselines with a large margin. Code and demo videos are available at: https://decisionforce.github.io/HACO/.
Safe Driving via Expert Guided Policy Optimization
Oct 30, 2021
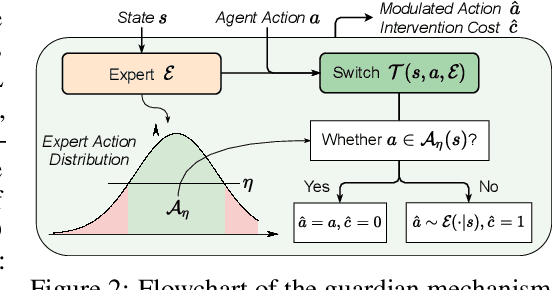
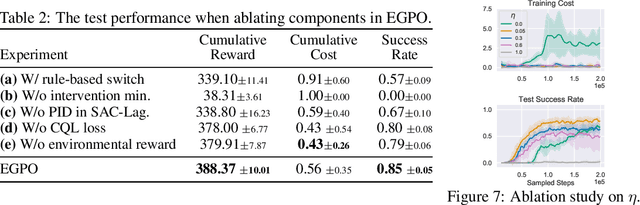

When learning common skills like driving, beginners usually have domain experts standing by to ensure the safety of the learning process. We formulate such learning scheme under the Expert-in-the-loop Reinforcement Learning where a guardian is introduced to safeguard the exploration of the learning agent. While allowing the sufficient exploration in the uncertain environment, the guardian intervenes under dangerous situations and demonstrates the correct actions to avoid potential accidents. Thus ERL enables both exploration and expert's partial demonstration as two training sources. Following such a setting, we develop a novel Expert Guided Policy Optimization (EGPO) method which integrates the guardian in the loop of reinforcement learning. The guardian is composed of an expert policy to generate demonstration and a switch function to decide when to intervene. Particularly, a constrained optimization technique is used to tackle the trivial solution that the agent deliberately behaves dangerously to deceive the expert into taking over. Offline RL technique is further used to learn from the partial demonstration generated by the expert. Safe driving experiments show that our method achieves superior training and test-time safety, outperforms baselines with a substantial margin in sample efficiency, and preserves the generalizabiliy to unseen environments in test-time. Demo video and source code are available at: https://decisionforce.github.io/EGPO/