 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhensong Qian
FactorBase: SQL for Learning A Multi-Relational Graphical Model
Aug 10, 2015
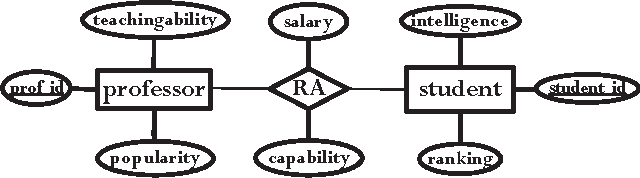
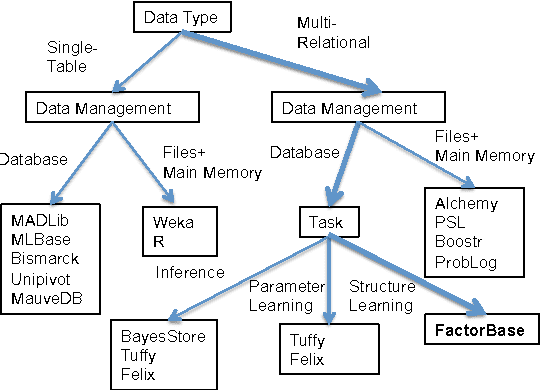
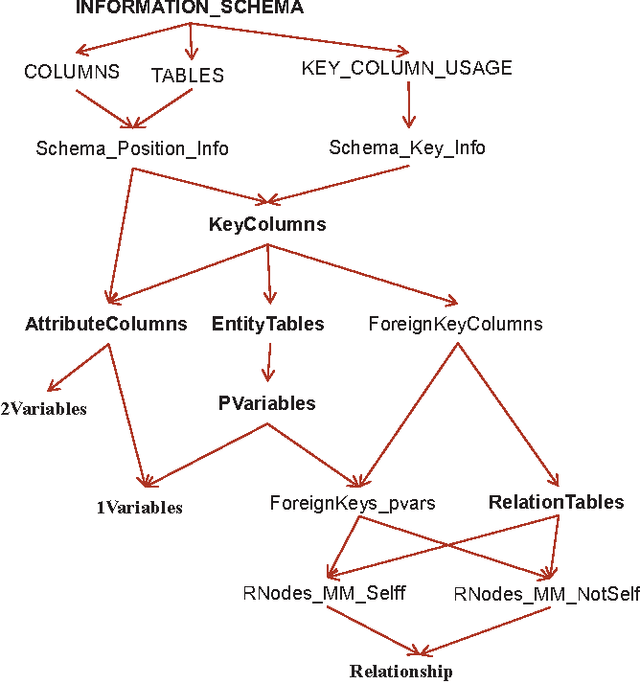
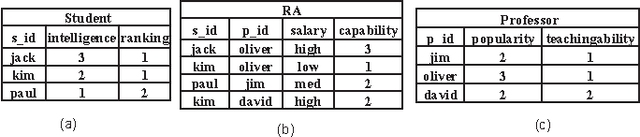
We describe FactorBase, a new SQL-based framework that leverages a relational database management system to support multi-relational model discovery. A multi-relational statistical model provides an integrated analysis of the heterogeneous and interdependent data resources in the database. We adopt the BayesStore design philosophy: statistical models are stored and managed as first-class citizens inside a database. Whereas previous systems like BayesStore support multi-relational inference, FactorBase supports multi-relational learning. A case study on six benchmark databases evaluates how our system supports a challenging machine learning application, namely learning a first-order Bayesian network model for an entire database. Model learning in this setting has to examine a large number of potential statistical associations across data tables. Our implementation shows how the SQL constructs in FactorBase facilitate the fast, modular, and reliable development of highly scalable model learning systems.
SQL for SRL: Structure Learning Inside a Database System
Jul 02, 2015
The position we advocate in this paper is that relational algebra can provide a unified language for both representing and computing with statistical-relational objects, much as linear algebra does for traditional single-table machine learning. Relational algebra is implemented in the Structured Query Language (SQL), which is the basis of relational database management systems. To support our position, we have developed the FACTORBASE system, which uses SQL as a high-level scripting language for statistical-relational learning of a graphical model structure. The design philosophy of FACTORBASE is to manage statistical models as first-class citizens inside a database. Our implementation shows how our SQL constructs in FACTORBASE facilitate fast, modular, and reliable program development. Empirical evidence from six benchmark databases indicates that leveraging database system capabilities achieves scalable model structure learning.
Fast Learning of Relational Dependency Networks
Dec 09, 2014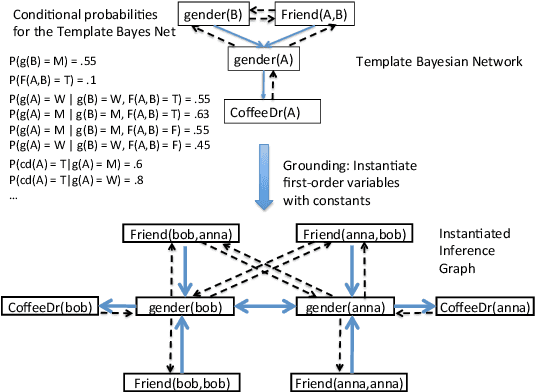
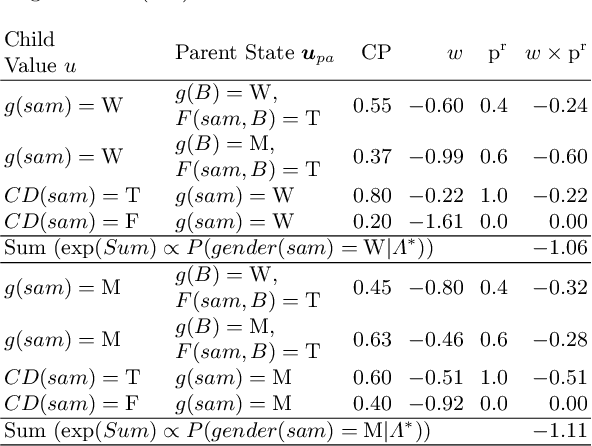
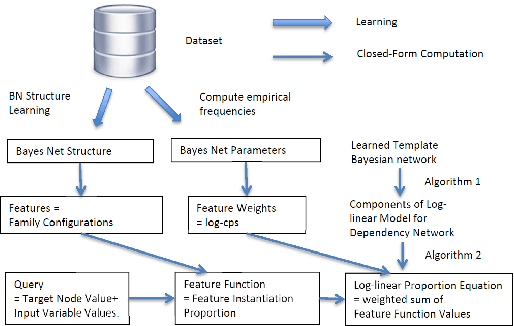
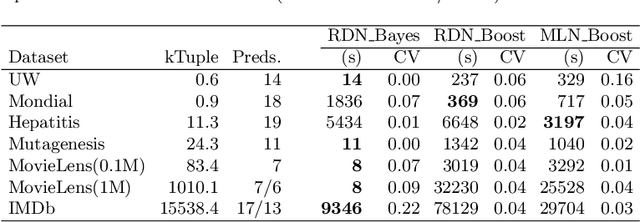
A Relational Dependency Network (RDN) is a directed graphical model widely used for multi-relational data. These networks allow cyclic dependencies, necessary to represent relational autocorrelations. We describe an approach for learning both the RDN's structure and its parameters, given an input relational database: First learn a Bayesian network (BN), then transform the Bayesian network to an RDN. Thus fast Bayes net learning can provide fast RDN learning. The BN-to-RDN transform comprises a simple, local adjustment of the Bayes net structure and a closed-form transform of the Bayes net parameters. This method can learn an RDN for a dataset with a million tuples in minutes. We empirically compare our approach to state-of-the art RDN learning methods that use functional gradient boosting, on five benchmark datasets. Learning RDNs via BNs scales much better to large datasets than learning RDNs with boosting, and provides competitive accuracy in predictions.
Computing Multi-Relational Sufficient Statistics for Large Databases
Aug 22, 2014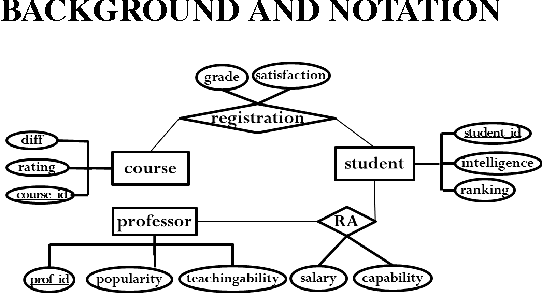
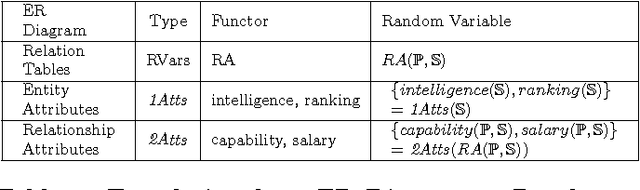
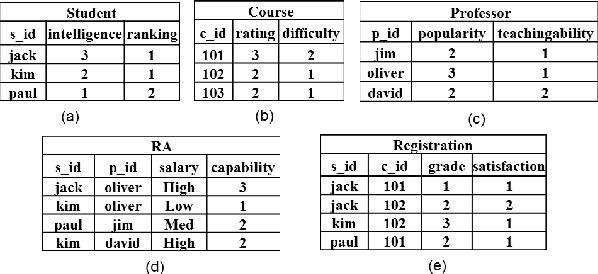
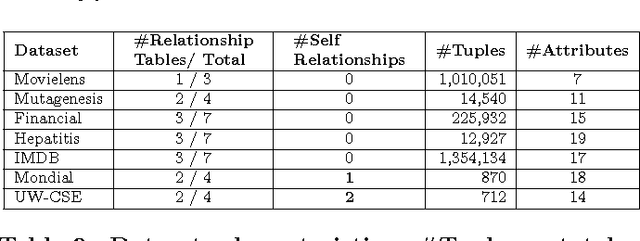
Databases contain information about which relationships do and do not hold among entities. To make this information accessible for statistical analysis requires computing sufficient statistics that combine information from different database tables. Such statistics may involve any number of {\em positive and negative} relationships. With a naive enumeration approach, computing sufficient statistics for negative relationships is feasible only for small databases. We solve this problem with a new dynamic programming algorithm that performs a virtual join, where the requisite counts are computed without materializing join tables. Contingency table algebra is a new extension of relational algebra, that facilitates the efficient implementation of this M\"obius virtual join operation. The M\"obius Join scales to large datasets (over 1M tuples) with complex schemas. Empirical evaluation with seven benchmark datasets showed that information about the presence and absence of links can be exploited in feature selection, association rule mining, and Bayesian network learning.